(With embedded
Q&A)
Last updated:
Wednesday, September 20, 2006 08:38 PM
© Copyright 2006 Lawrence Chasin and Deborah Mowshowitz
Department of Biological Sciences Columbia University
New York, NY:
Bio C2005/F2401x 2006 Lec.5 L. Chasin September 19, 2006
Protein 3-dimensional structure
Tertiary structure (3o)
= overall 3-D conformation of a single polypeptide
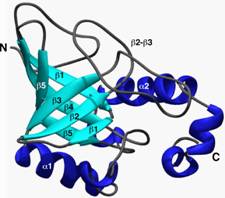
Protein domains
Denaturation, renaturation
Dialysis
Chaperonins
Quaternary (4o)= association of multiple polypeptides
Protein domains
Prosthetic groups
Membrane proteins, channels
Proteins bind molecules with great specificity
Protein purification
methods
Ultracentrifugation
Native gel electrophoresis
SDS gel electrophoresis
Gel filtration
Enzymes
-----------------------------------------------------------------------------------------------------------
(Tertiary
(3o)= overall 3-D of a polypeptide)
Tertiary structure means
the overall 3-dimensional folding of a single polypeptide chain. For this
overall shape, interactions between side chains are very important, as are
interactions between side chain and water. A generality is that
the hydrophilic groups are folded to be on the outside where they can interact
with water via hydrogen bonds, while the hydrophobic side chains are collected
in the inside of the structure, pushed together by hydrophobic forces. This rule
is not at all 100% true, and most proteins have side chains that deviate from
this generality. That is, there are hydrophobic side chains on the surface, but
they are intermingled among the hydrophilic groups. And there are hydrophilic
groups on the inside, where they are usually interacting with other hydrophilic
groups. In fact, it is this interaction of side chains with each other that
confers most of the overall 3-dimensional shape on a given polypeptide.
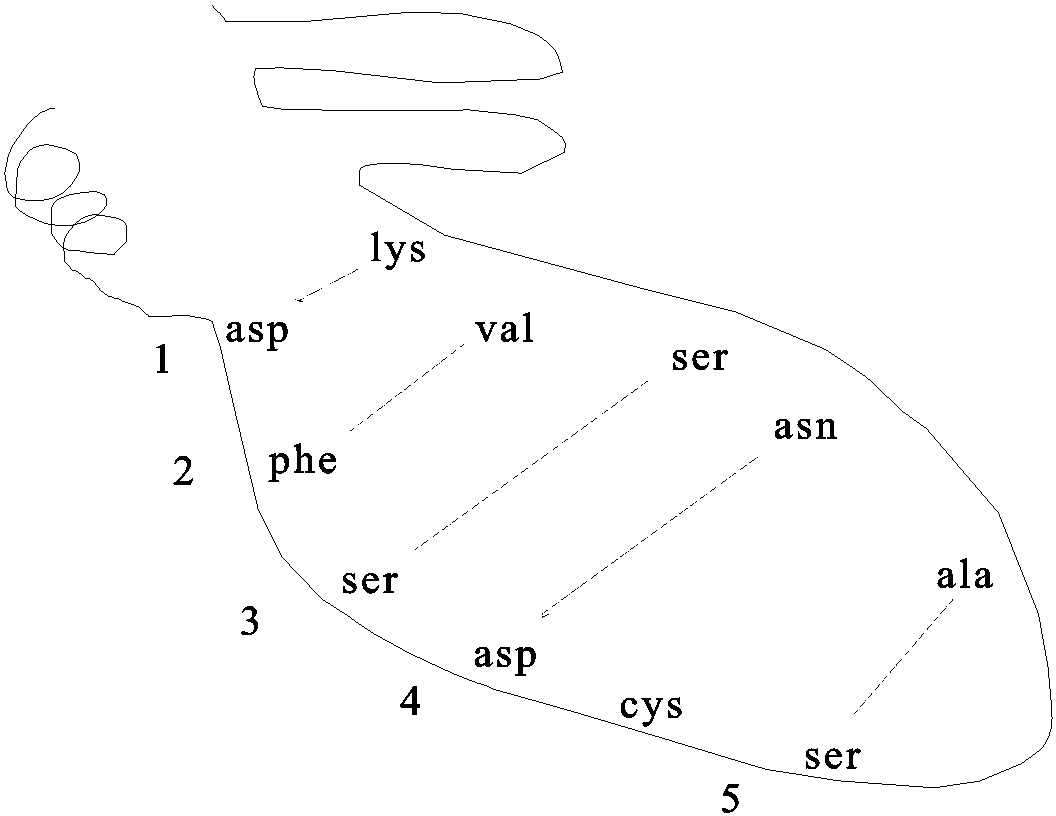
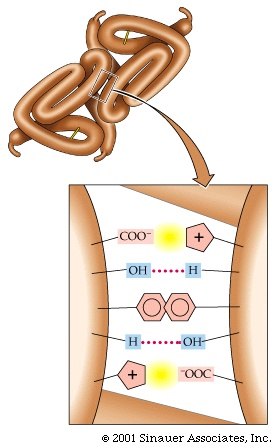
Pictured here are the weak bonds that were introduced earlier. The side chain interaction indicated in the diagram illustrate examples of these various interactions. Consult your text for the exact nature of the side chains:
1. ionic (lys - asp)
2. hydrophobic and VDW (phe - val)
3. H-bond (ser - ser)
4. H-bond to ionic (asp - asn)
5. van der Waals (ser - ala)
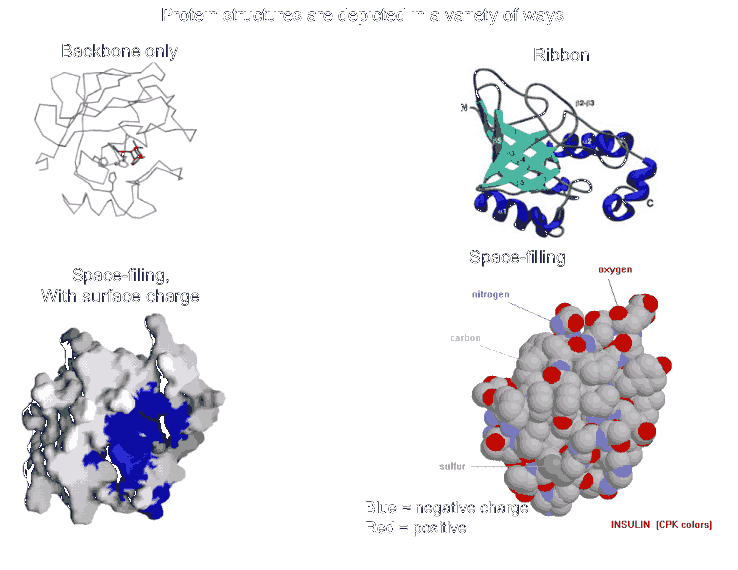
These weak interactions occur in loops between regions of secondary structure as well as between the secondary structures themselves (e.g., one alpha helix to another or to one side of a beta sheet). Most proteins fold into a roughly globular shape (enzymes, hemoglobin (Hb), antibodies--see pictures of proteins in your texts: a space-filling model, or showing just the backbone connections, or a ribbon model), but many take on an elongated or even fibrous shape (collagen, myosin [in muscle], fibroin [in silk]).
These are weak bonds, but in the aggregate, they are strong enough to hold the polypeptide together at least under the thermal motion conditions of physiological temperature (37 deg C) (Purves6ed 3.8; 7th 3.8). {Q&A}
(Sulfhydryls,
disulfides)
But there is one strong bond that contributes to the folding of some proteins.
This is the DISULFIDE BOND, and it differs from all these other bonds in being a
covalent bond. It can only be formed between the side chains of two CYSTEINE
residues. The side chain -CH2-SH contains a SULFHYDRYL group: -SH. Two
sulfhydryls can react with oxygen to lose their 2 hydrogen ATOMS (H with
its electron; not H+ ions, not protons) and become bound to each other in the
process:
Protein-CH2-SH + HS-CH2-Protein + ˝O2 ---> Protein-CH2-S-S-CH2-Protein + H2O
So now the two sulfur atoms are sharing electrons in a strong covalent bond. This bond cannot be broken by mere thermal energy, and so disulfide bonds hold the two parts of the polypeptide chains that had contained the two cysteines firmly together. Not all proteins have disulfide bonds, but many do.
This reaction is an example of an oxidation-reduction reaction: the sulfhydryls are getting oxidized (here losing hydrogen atoms is oxidation), while the oxygen is getting reduced, (or gaining hydrogen atoms) and ending up as water. This reaction will usually take place rapidly with no further help from catalysts. As in the case of the other reaction we discussed that doe not require a catalyst (the closure of the glucose ring) the two reacting species are positioned so that they can easily collide. In the case of a polypeptide, the 2 reacting cysteines are brought together by the concerted action of weak bonds among the other side chains in their vicinity.
(Note that it is not a hydrogen ION (proton, H+) that is being moved about here, but the hydrogen ATOM with its electron. Actually, it is the electrons that accompany the hydrogen atoms that are fundamental to the definition of oxidation/reduction, rather than the hydrogen atoms as a whole, as we shall see later. That is, oxidation is the loss of electrons, and reduction is the gain of electrons, with or without an accompanying hydrogen ion.)
The net result is tertiary structure, or the overall 3-dimensional shape of a folded-up single polypeptide. Note that there will be many regions of secondary structure within this overall tertiary structure. It is the interactions of the side chains that are to a large extent responsible for preventing the whole polypeptide from simply becoming 100% alpha-helix or 100% beta-sheet. (see picture of the tertiary structure of proteins represented by a folded ribbon, a space-filling model, and by simply tracing the backbone).
(Show wire model ball with alpha-helices and beta-sheets within it. )
To review tertiary structure, try problem 2-3 part D.
So now we can see that one polypeptide molecule can be folded into a compact structure and we can understand what holds it together, but why is it that there is only one structure formed and not many? Is there only one solution to the folding problem for a particular polypeptide chain?
Perhaps all possible conformations are tried in the course of folding, and only the most stable one accumulates. Can we predict the conformation from first principles? If we plug in the properties of all the amino acid side chains, how hydrophobic they are, what is the strength of an ionic bond, etc. we can ask a computer to try and try many combinations, many interactions. This is a very difficult computer problem, even for today's supercomputers, because the number of possibilities for a good-size polypeptide of say 500 amino acids is enormous (20^500). But it has been tried, and so far usually the wrong structure comes out. The right structure is determined by examining crystals of the proteins, beaming X-rays through the protein crystals and calculating how they are refracted by the atoms in the crystal. Perhaps we really don't know the right properties of the side chains. Or perhaps there is some guide to folding that being imposed on the polypeptide as it is being polymerized in the cell, some outside influence, even a template of sorts, one can imagine a plaster mold analogy, for example. That is not the case, as we shall see next.
(Denaturation,
renaturation)
Well, if it is true that the folded
structure of a particular protein is unique simply because it is the most
stable, then if we UN-fold the polypeptide, it should be able to RE-fold into a
its unique structure. How could we unfold a protein, let's say one with no
disulfide bonds, only weak bonds. We could consider egg albumin, for an
everyday case of polypeptide denaturation. Raw egg white is a concentrated
solution of this single ~500 amino acid polypeptide, that exists folded into a
roughly spherical shape.
How can we denature it?....Here's some examples:
Heat: thermal motion becomes to great for the weak bonds.
pH: acids and bases both work, disturbing ionic bonds.
"chaotropic" agents, such as very high concentrations (e.g., 8M) of urea (H2N-CO-NH2) can form so many H-bonds that they compete with and disrupt interactions with water.
organic solvents (e.g., hydrocarbons: octane, benzene, chloroform) turn the polypeptide inside out, as the hydrophobic forces disappear. {Q&A} {Q&A}
These are all DENATURING conditions. After denaturing the pure polypeptide, we could try to reverse the disruption.
Let's heat it to denature it (boil it). The sphere is now subject to faster and faster thermal motions, until finally it starts to unravel. What has happened to the egg white (the albumin polypeptide)? It has become denatured. Purves6ed 3.9; 7th 3.11]. No longer native, which is the structure in the cell. No covalent bonds have been broken by this 100oC temperature. The bundled up rope became the open randomly coiled rope in the Jacuzzi, and this allowed many wrong bonds to form, it exposed the hydrophobic groups normally hidden in the interior of the protein. In this concentrated solution a tangled mass of interacting polypeptide chains was produced, which resulted in a gel, a hot hard-boiled egg. So while folded up polypeptides are stable enough in their native environment inside the cell, the 3-dimensional structure is typically rather fragile: most proteins are easily denatured by heat and other treatments that can affect these weak bonds. This bundled rope in the Jacuzzi exists on the verge of becoming unraveled.
So now let's reverse the denaturation, let's cool down this hard-boiled egg and return it to normal temperatures. The gel seems to stay. We do not get back our runny egg white. A case of irreversible denaturation. But not a very fair experiment, letting all those molecules, present at a very high concentration, get SO tangled. Let's try a denaturation - renaturation in a more gentle, gradual way.
A fellow named Christian Anfinsen did this experiment in the 1950's. He took a protein called ribonuclease, a protein that is a digestive enzyme, a protein that helps break down the macromolecule RNA. It must be in its native structure to do this job.
Actually he had to break disulfides here to get full denaturation. So he did: he added a reducing agent: mercaptoethanol (HO-CH2-CH2-SH). In the presence of this reagent, one gets exchange among the disulfides and the sulfhydryls:
Protein-CH2-S-S-CH2-Protein + 2 HO-CH2CH2-SH --->
Protein-CH2-SH + HS-CH2-Protein + HO-CH2CH2-S-S-CH2CH2-OH
The protein's disulfide gets reduced (and the S-S bond cleaved), while the mercaptoethanol gets oxidized.
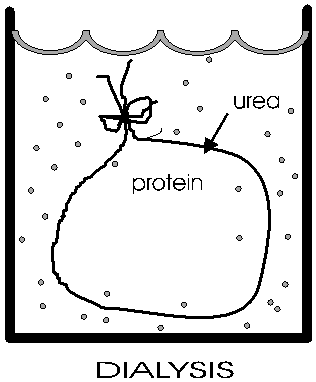
(Dialysis)
After disruption of the disulfide bonds in
ribonuclease, Anfinsen placed the polypeptide in a plastic sack, and added urea,
H2N-CO-NH2
to the solution outside the sack. Urea will break hydrogen bonds at high concentrations (e.g., 8M). {Q&A} {Q&A} The sack is made of a semi-permeable plastic material with pores big enough to allow small molecules like urea and water to pass through but not macromolecules like albumin or ribonuclease. This process of allowing the concentrations of changing small molecules to change while holding the concentrations of large molecules constant is a called dialysis. After allowing time for diffusion, the concentration of urea inside the sack should be the same as the concentration outside. {Q&A} He then checked that the protein had become denatured (e.g., by ultracentrifugation, see below)..
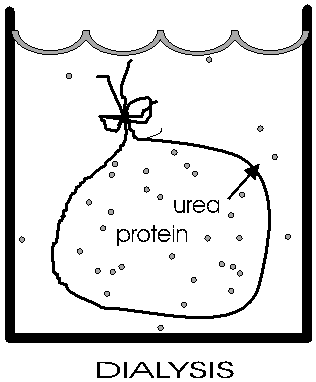
Now he gradually dialyzed out the urea (by changing the solution outside the sack to stepwise lower and lower concentrations of urea). A dilute solution of the protein was used, and the gradual removal of the urea gave time for the polypeptide to re-fold.
He then exposed the polypeptide to oxygen to get back the disulfide from correctly positioned cysteine side chains (forming H20).
He got back native ribonuclease. It checked out physically, and also functionally, by the fact that it regained its ability to digest RNA.
This type of experiment has been now been repeated many times for many different proteins. It works for many, fails for some. But the positive results are very important, for they prove that for many or even most proteins, all the information that is necessary for the complex and unique 3-dimensional structure is present in the primary sequence of the polypeptide chain.
That is, PRIMARY STRUCTURE DETERMINES TERTIARY STRUCTURE. This conclusion was a major step in biochemistry, indeed is a fundamental tenet, and earned Anfinsen a Nobel Prize.
(Chaperonins)
That said, it must be added that in the past 20 years, it has become apparent
that some special proteins, called chaperonins, can
help certain other proteins to fold with in the cell. It seems that these
chaperonins may be needed for initial folding, perhaps to keep the as yet
unfolded molecules from interacting with each other in non-productive ways, such
as aggregating via exposed hydrophobic groups, as I suggested as occurring
during the solidification of a hard boiled egg. See Purves 7th ed
fig. 3.12 for one complex chaperonin. The chaperonins are
also used when proteins denature inside the cell: for instance, after they
have traversed a membrane, with its hydrophobic environment. Or after cells have
been exposed briefly to slightly elevated temperature (called heat shock), when
a few of the least stable proteins may start to denature. The role, the
generality, and the mechanism by which these proteins aid other proteins in
folding correctly is not yet well understood. However, these cases do not really
detract from the general principle that primary sequence CAN determine all
higher order structures.
(Quaternary (4o)=
association of multiple polypeptides)
Tertiary structure describes folding of a
single polypeptide, and while many proteins do consist of a single chain, most
are composed of several distinct polypeptide
chains. The association of these separate chains in known as
QUATERNARY
STRUCTURE.
The number of polypeptides in a protein can be 2, 4, 8 or higher. Or 3 (rarer).
These chains are folded up in 3-dimensions, assuming a tertiary structure, and then are stuck to each other. What keeps them stuck together? The same answer as usual: those weak bonds we keep discussing, and more rarely, the covalent disulfides.
Proteins with quaternary structure are called MULTIMERIC proteins. Individual polypeptides are called SUB-UNITS (of the protein). {Q&A}
One polypeptide chain can be considered a monomer, relatively speaking. A protein with 4 chains a tetramer. Etc. The subunits can be identical ( called HOMOPOLYMERIC) or they can be different polypeptides (or HETEROPOLYMERIC).
Now we can distinguish a "protein" from a "polypeptide". In its native form, the macromolecule is called a protein, and may consist of one or more polypeptides, depending on the protein.
E.g., Hemoglobin, Hb, has the structure a2ß2, consisting of 4 polypeptides, 2 alpha chains and 2 beta chains, of MW 16,000 each. So the MW of the Hb protein (a tetramer) is 64,000. [Purves6ed 3.7]
If you denature a multimeric protein, the MW will change (unless the subunits are held together with disulfide bonds and you don't disrupt them ), e.g., the MW changes from 64000 to 16000. {Q&A}

The subunits of some multimeric proteins are held together by disulfide bonds (in addition to the usual weak bonds). For example, the antibody molecule, immunoglobulin, is a tetramer of two identical "heavy" chains (H) and two identical "light" chains (L), or H2L2 and it includes S-S bonds between the H and L chains. You must denature AND reduce the disulfides to get the individual subunit polypeptides dissociated from each other.
So the surfaces of polypeptides have also evolved to allow interaction with other particular subunits but not with other proteins in general.
Consider now Sickle Cell Disease again. Hemoglobin is a tetramer of 2 pairs of identical sub-units: a2b2. Glu --> val was the a.a. change comparing normal Hb to sickle Hb (HbS). The result is that the tetramers inappropriately interact, presumably via hydrophobic interactions that in normal Hb is precluded by the charged glu. In HbS this position is valine and now has a more hydrophobic patch of surface. The result is that these patches can now get stuck together by hydrophobic forces, aided by the fact that each HbS molecule has two such patches (one for each beta chain) and that the concentration of Hb molecules inside a red blood cell is very high (they can almost be viewed as bags as Hb). You get long chains of tetramers, and these long arrays can distort the shape of the RBC (red blood cell) into a sickle shape. This shape is not as hydrodynamic as the original shape, and the RBCs can now get clogged in small capillaries, the manifestation of the disease. One a.a. out of 250 was responsible. Once again we see that proteins are fragile, are often only on the brink of stability.
(Domains)
DOMAINS: One additional aspect of protein structure
is protein domains. The overall shape of
most proteins is roughly globular, but if one looks more closely, one can see
that most proteins can be divided into sub-regions that are folded more or less
independently of the rest. These folded up globules are called domains. An
interesting feature of many domains is that homologous domains can often be
found in many different proteins. Many of the individual amino acids in
the primary structure are different, but many others are the same, and the
overall shape of the domains in different proteins can be very similar. A
recognizable domain in a protein can often be associated with a particular
function, often the ability to bind a particular small molecule. In the
hemoglobin example, each subunit can bind a molecule of oxygen and an
oxygen-binding domain of similar structure might be found in several
different proteins, each of which needs to bind oxygen to carry out its
function. Thus we might also have a glucose binding domain, a phosphate-binding
domain or an RNA-binding domain in several proteins whose function requires them
to bind these molecules.
PROSTHETIC GROUPS: There are some NON-amino acid components of proteins that are so tightly bound they are considered part of the protein. These small molecules are called prosthetic groups, and in general they are not covalently attached to the protein but rather are bound tightly by a series of weak bonds,. These small molecules are usually essential for the function of the protein. For example, in hemoglobin, the "heme" groups are actually organic ring compounds with an iron atom at their center, and it is this iron atom that actually binds the oxygen that is carried by the hemoglobin protein. Some of the vitamins become prosthetic groups (e.g. riboflavin). Metal ions, especially divalent metal ions such as magnesium or zinc can also be considered prosthetic groups if they remain bound during the purification of a protein. See Becker for heme structure (also in the protein structure handout).
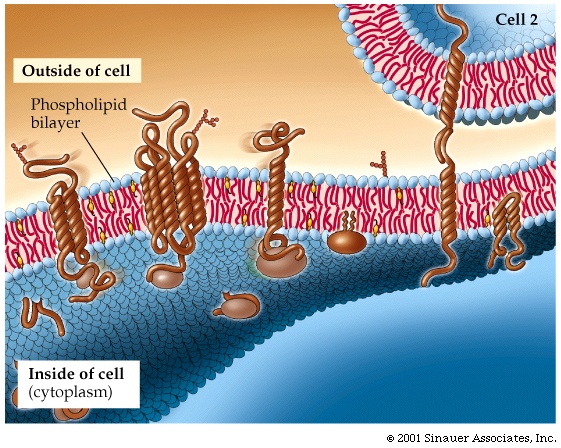
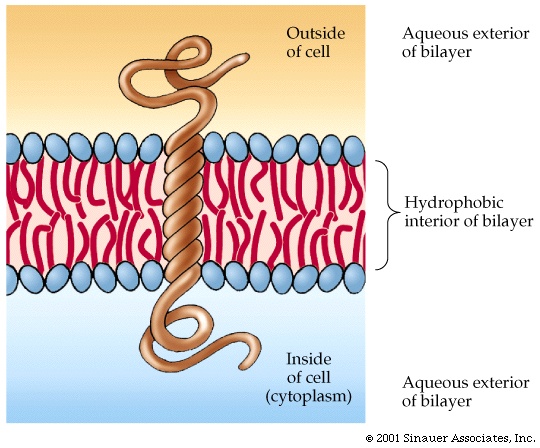
(Membrane proteins)
As an introduction into an example of the
function of proteins, let's consider first a special class of proteins that do
not follow some of the rules we have have seen that govern protein structure in
general. These are the MEMBRANE PROTEINS, the
proteins that reside, not in the aqueous environment of the cytoplasm or the
nucleus, but rather inside the hydrophobic environment of the membranes of the cell,
including the cell membrane.
In these proteins, the hydrophobic side chains are on the outside, as there are
no hydrophobic forces present to force them to coalesce. These
proteins can usually diffuse laterally in the lipid bilayer of the membrane
they can aggregate with each other with specificity, and they can become
anchored via attachment to structural cytoplasmic fibers. They can be
nearly completely enveloped by the lipid bilayer, or they could be partially
immersed, with a more conventional half (i.e., hydrophobics on the inside,
hydrophilics on the outside) sticking out into the cytoplasm or on the outside
of the cell. See [Purves6ed 5.1;
7th 5.1],
[Purves6ed 5.4; 7th 5.2].
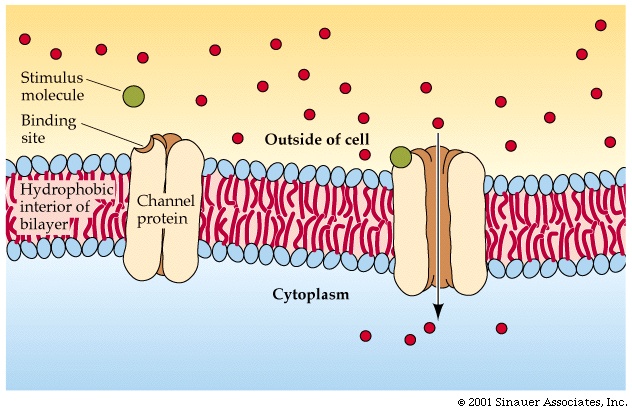
One class of membrane proteins act as channels through the membrane. The
channel proteins are formed into cylinders, with a hydrophobic exterior, but
with hydrophilic groups lining the hole through the interior of the cylinder.
Small molecules can pass through the cylinder, or channel, but large molecules
cannot fit through (note: macromolecules generally CANNOT diffuse onto cells).
See Purves6ed 5.9; 7th 5.9.
To
consider how peptides fit into a membrane, try problem 2-13, part D.
At this point you should be able to do all the problems in problem set #2.
So we have a cellular function for a protein, and a function that shows some
selectivity on the basis of size there. How about other criteria of selectivity,
like charge?
Some channels can distinguish charge: + repels +, and attracts -, so a channel that is lined with positive charge could bind a negatively charged ion and, if there's a higher concentration outside than inside, eventually pass these ions along from the outside of the cell to the inside. A positively charged ion on the other hand would be repelled by the channel and so would not get into the cell by this route.
You can a imagine the same sort of selectivity based on hydrogen bonding, for example.
So a protein can detect charge and surface electrical properties, but how about shape?
(Proteins bind
molecules with great specificity)
Consider a pocket on the surface of a
folded protein. As I've drawn this surface pocket, the free amino acid gly can
fit in and bind using the electrical attraction of ionic bonds. However, the closely
related amino acid alanine, with a methyl group as a side chain, cannot fit into
this hypothetical protein A drawn here (yellow). Ionic bonds and van der Waals
bonds (VDW) are responsible for the binding in this example so far (using
different colors for protein and aa)
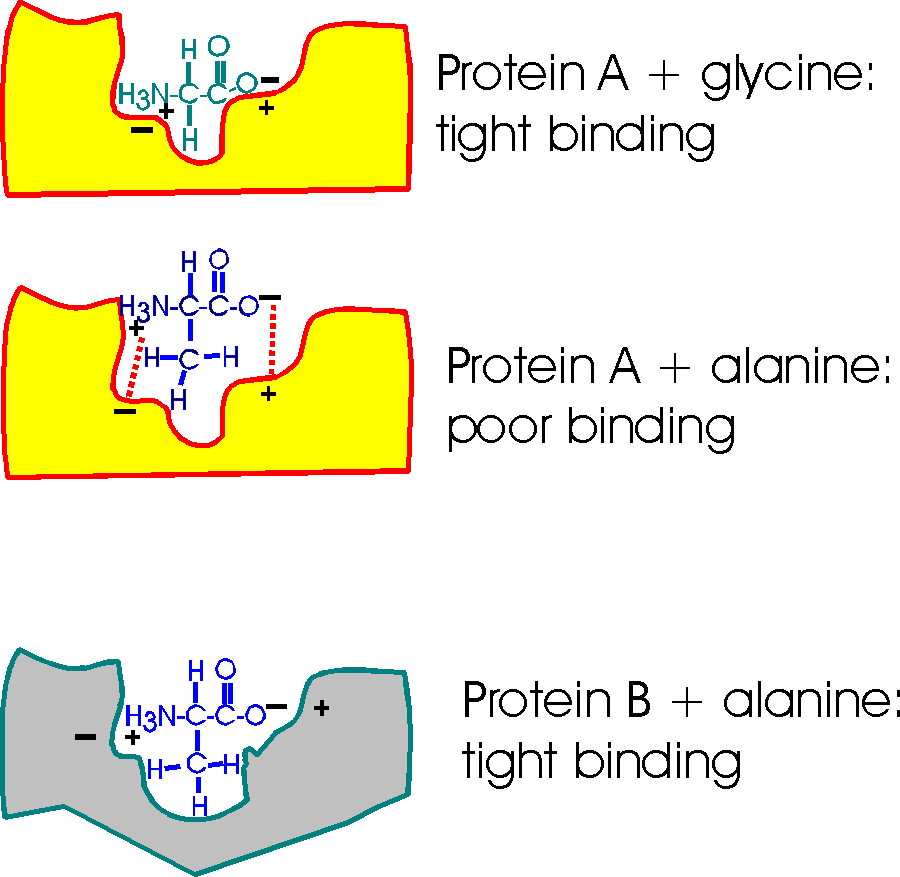
But a similar pocket on the surface of another protein (gray protein B) could be built to accommodate the methyl (the -CH3 group) of alanine and supply some more V.D.W. bonds there in the process.
So Protein A binds glycine, but not alanine.
And Protein B binds alanine (but gly not so tightly).
So you can get specific binding ... and this binding is critically dependent upon the structure of the protein, the shape of the binding site. This binding is also a critical part of the function of the protein, and we will soon see.
Specific binding at a protein surface is not restricted to interactions between a macromolecule and a small molecule. There is also specificity in the interactions between two macromolecules, as exemplified many times by quaternary structure: the complementary surfaces of the two correct subunits fit together with great specificity; just the right subunits polypeptide specifically associate to form a multimeric protein. For example, the subunits of immunoglobulin (Ig) never associate with the subunits of hemoglobin (Hb).
PROTEIN PURIFICATION (SEPARATIONS)
(Protein
purification methods:
Ultracentrifugation)
Now that we know quite a bit about
proteins, let's take some time once again to discuss methodology. In this
case, the purification of individual proteins, which involves their separation
from all the other proteins in the cell. Much of what we want to know about
proteins requires that we have a pure preparation containing only protein
molecules of one homogeneous type. Since there are 3000 different types of
protein molecules in E. coli, our task will be to separate one away from all
2999 others, to purify it.
[The verb "separate" sometimes causes confusion at this point. In the context of purifications, "separate" is used as a relatively passive action, operating on a mixture without altering the components greatly, e.g., to separate the wheat from the chaff. Our primary objective here will not be to cleave molecules (e.g., "I'm gonna separate your head from your body"), although sometimes a cleavage may occur in the course of an experiment (e.g., cleavage of the disulfides of immunoglobulin in order to effect a separation of the individual subunits).]
How can we proceed to purify a protein? Well, what makes one protein different from another?
Can you proffer some characteristics?: size (MW), charge (net), shape, hydrophobicity (solubility), surface binding ability....
Yes, all these are used in what is still a challenging task for any biochemistry laboratory, the purification of its favorite protein.
Here is one sometimes useful method: ULTRACENTRIFUGATION
ultra means = >20,000 rpm; 60,000 rpm is common, compare a Ferrari at 6000 rpm, redlining; this is ten times faster; you need a vacuum chamber so heat from air friction cannot be produced. )
Diagram of tube, spin (top view), the subsequent distribution of molecules ...
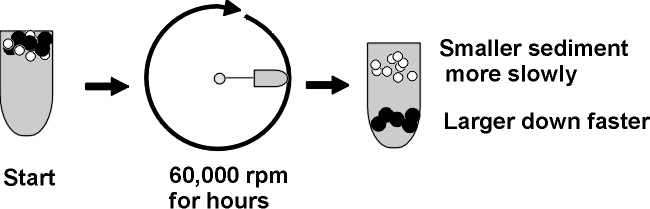
A mixture of molecules will be subject to two
main forces in the ultracentrifuge
as it starts to spin (ignoring buoyant force):
Causing sedimentation is the centrifugal
force = m(omega)2r = (which is proportional to the
mass or MW of a protein).
m = mass, omega = angular velocity, and r = distance from the
center of rotation.
Opposing sedimentation = friction = foV.
fo = frictional coefficient, a
constant for any particular protein, it is minimum for a sphere, higher for less
compact shapes like cigars or pancakes.
V = velocity of the molecule as it moves away from the center
of rotation of the centrifuge.
Soon after accelerating (i.e., V increasing), V increases to a point where no further acceleration takes place, as the forces on the molecule are balanced. It continues to sediment, but at a constant velocity. Like a skydiver.
Now at this point, at this velocity:
Centrifugal Force = Frictional force
(there's no net force, no
acceleration, but constant velocity; a body in motion with no net force on it
tends to stay in motion)
So at this point (soon achieved): M(omega)2r = foV
And: V = m(omega)2r/fo,
where f = a frictional coefficient dependent on
shape
(to visualize the effect of shape on friction, compare the velocity of a falling
feather vs. a tiny pebble of equal weight, dropped in the fluid of air).
Higher f = more friction.
If assume a spherical shape, then we can estimate a MW (Assume fo, and then measure V and r, so we can solve for m, or the MW)
On the other hand, if we know the MW, we can get information about shape (via fo).
Sedimentation velocity is often expressed as a sedimentation coefficient, s, which takes the centrifugation conditions into account s = V/(omega)2r, and so m = sfo. S is also expressed in Svedberg units, or Svedbergs, One Svedberg unit is 10^-13 seconds. This definition allows one to talk about s values of 4 to 200 rather than more complicated numbers. {Q&A}
So ultracentrifugation separates proteins on the basis of MW and shape. It is a gentle procedure (non-denaturing, can be carried out at nice low temperature (say 4 deg C, which tends to stabilize proteins) and in the presence of a buffer at pH 7 and physiological levels of salts).
You can recover your protein by punching a hole in the bottom of the centrifuge tube, and collecting the solution in a series of tubes as it drips out the bottom. Each tube can then be examined, or assayed, for the presence of the protein to be purified. For this purpose you need to be able to detect the protein in the midst of the other proteins. For example, if you were purifying Anfinsen's ribonuclease, you could measure the ability of the tube contents to catalyze the breakdown of RNA to its monomers.
How about separation on the basis of the net charge of a protein. We separated amino acids on the basis of charge in paper electrophoresis. For proteins, the solid supporting material is a gel, not paper:
To review denaturation, renaturation, and ultracentrifugation, try problem 2-6 (skip B) and 2-15. To review tertiary & quaternary structure, try problems 2-3D & 2-5.
GEL ELECTROPHORESIS:
There are two types -
( Native gel electrophoresis)
First: native
gel electrophoresis
acrylamide (a monomer in this chemistry) in aqueous solution ---> polyacrylamide (P.A.G.E.). The result is a network of polymer fibers, which form a gel, with the consistency ~ Jello.
Usually a vertical apparatus is used, with an anode and a cathode. Apply the protein mixture to the top of a slab of this gel.
Apply voltage (~200 v).
The gel consists of a tight fiber network, so proteins have trouble migrating, negotiating their way through the tangled fibers.
Their rate of migration depends on two
properties:
Their net charge and their "size" (which is
proportional to MW if spherical)
Molecules with the most charge (net) (of a sign opposite to that of the far
electrode) migrate to the far electrode fastest. Molecules that are
smallest (i.e., lowest MW) can worm their way through the gel fibers fastest.
So the smallest and most highly charged wins the race.
After the electrophoresis has been stopped, molecules will be distributed along
the gel length according to these two characteristics (MW and net charge).
[Note that molecules with a charge opposite to the near electrode, will migrate
up and off the gel, into the buffer reservoir and be lost. Trial and error
will dictate how you setup the electrophoresis if you do not know the charge on
the protein you are trying to isolate.]
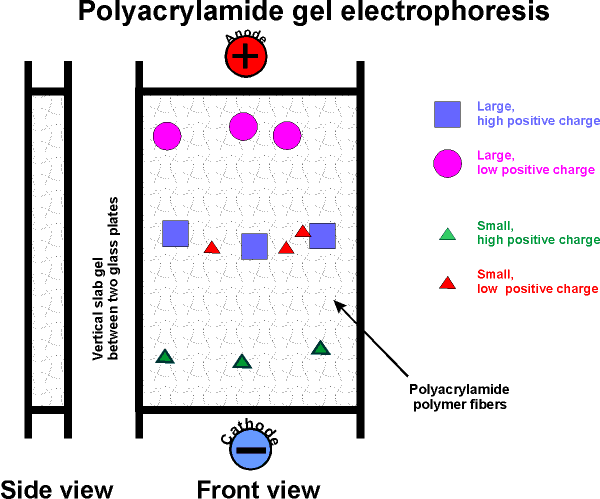
(SDS gel electrophoresis)
Second, a more widely used variation of gel
electrophoresis: SDS PAGE.
Add sodium dodecyl sulfate, SDS (or SLS): CH3-(CH2)11- SO4-
[sulfate is similar in structure to phosphate, and is a strong acid]. Like a phospholipid, SDS has a highly polar end and a highly hydrophobic body.
Might you expect SDS to denature a protein? Yes. It's a detergent and a powerful denaturant. It binds all over the protein, coating every protein with a uniform negative charge. SDS is put into in the gel when you form it and into the electrophoresis buffer. Now run SDS-PAGE. Where should the anode be placed? Does it matter? Yes, the protein is coated with negative charge now so anode is always at the bottom.
Under these denaturing conditions, the polypeptides exist as a random coils, which then migrates solely on the basis of their size, which is the equivalent of a sphere for all polypeptides. Larger molecules have more difficulty finding their way through the polyacrylamide fibers. So the lowest MW wins.
One must remember to reduce the disulfides with mercaptoethanol first (usually), so as to have a truly random coil to compare.
If you run standards of known MW, you can determine the MW of your protein by comparison, and this is a very common way to assign a MW to a polypeptide. However, it is not always completely accurate, as some proteins probably do bind a bit more SDS than others.
If you don't yet know what a protein does, you can just call it by its molecular weight, from SDS gels: e.g., p53, a famous protein whose absence is associated with cancer was named this way, and the name has stuck even though quite a lot is known about its function (p in p53 stands for protein, so you have names like p27, p100 etc.). {Q&A}
To review the use of gel electrophoresis, try problem 2-7.
(Gel filtration)
Want to know the MW of a protein in its
native, even quaternary structure?
For this we could use molecular sieve chromatography, or Sephadex, or gel filtration (these are all ~synonymous).
You start with plastic beads in a glass column with a support screen on the bottom.
Add your protein mixture to the top. Elute with a buffer. The beads are riddled with channels of a specified size. If a protein is smaller than the channel size, it enters, explores, diffuses out finally, having wasted its time in the race to the bottom of the column. Larger proteins can't fit in to the channels, don't waste their time, and win the race. Intermediate sizes waste some time but less than the smaller proteins. So larger molecules come out (elute) first, and the smallest come out last. Here again, you would collect the eluted proteins in a series of tubes, and then assay each tube for the presence of the protein being purified. If you calibrate the column by noting the behavior of spherical proteins of known size, you can determine the MW of your protein by comparison, if it is also spherical. If is is not spherical it will appear to have a higher molecular weight than its true MW (imagine a pancake being excluded from a channel while a sphere of the same MW gets in).
Other methods include ion exchange chromatography, which also takes advantage if the net charge on a protein, and affinity chromatography, which takes advantage of the surface properties of a protein. One can purify a particular protein away from all other proteins in 4-5 such steps. For more on protein separation techniques, see the protein separation handout.
Here are some images of laboratory ultracentrifuge , slab gel electrophoresis, gel filtration apparatuses. {Q&A}
To review separation methods & protein structure, try problems 2-3E, 2-6B, & 2-8.
Now having discussed protein structure, we turn to back to protein function.
ENZYMES
The ability to bind a specific small molecule is exploited by proteins when they carry out one their main functions: to act as catalysts that bring about chemical transformations of the small molecules they bind. These protein catalysts are called enzymes. Enzymes represent perhaps the single largest category of proteins, with respect to function. Since they are responsible for virtually all the chemical conversions going on in the cell, it is difficult to overestimate the central role they play in life.
(Catalysis)
Enzymes function as
catalysts. So let's define a catalyst.
Consider the purely chemical reaction between hydrogen gas and iodine gas:
H2 + I2 --> 2 HI + energy
This reaction goes spontaneously to the right because H2 and I2 are higher energy compounds than HI. That is, H2 and I2 are less stable than the combination of these 4 atoms in the form 2HI) :
[In the energy diagram below, the ordinate (y-axis) is free energy of the components, change in free energy (delta G) is the only thing that can be measured, and free energy here is the energy needed to pull apart the atoms (highest bond strengths will be lowest on the ordinate, as it will mean more energy has to be put in to raise the atoms to their free, separated, state)].
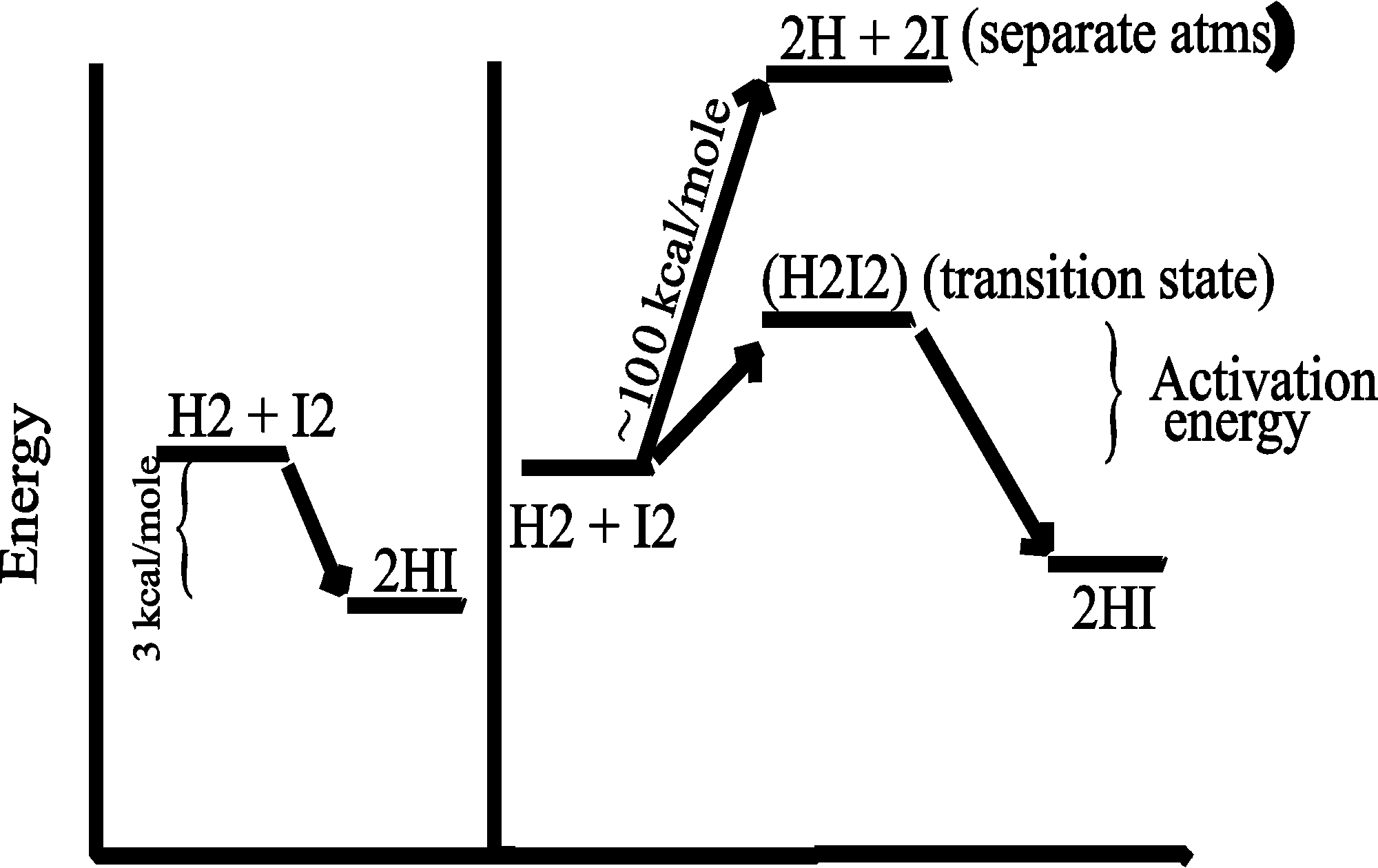
SO if you could invest the energy to separate the atoms, and then let them fall back to HI's, you would get more energy out (3 kcal/mole difference). This is a characteristic of a spontaneous chemical reaction: spontaneous means the reaction can proceed in the direction indicated (left to right) with the release of energy. In contrast, reactions that do not release energy, but require energy input, are not spontaneous.
ENERGY RELEASING reactions are called
EXERGONIC. ENERGY-REQUIRING reaction are
ENDERGONIC.
{Q&A} See
[Purves6ed 6.5; 7th 6.3]
Despite the fact that this is an exergonic reaction, it does not proceed very
readily. This failure to react is the case for many such energy releasing
reactions: e.g., burning paper (cellulose + oxygen reaction) can release much
energy, but left to itself in air paper only slowly browns.
We can understand this failure to react if you consider that you'd need to get the atoms apart before you can rearrange them, and it takes a lot of energy to break those covalent bonds. Actually, you do NOT need to take the atoms completely apart:
(Activation energy)
To get this transformation to proceed, you
just need to get to what is called a transition state (TS). If the two molecules (H2
and I2) collide at a sufficiently
high velocity, then all four of the atoms involved in the collision can temporarily form bonds to each other, and this complex then
has a chance to resolve itself into 2 HI (or back in to H2
+ I2):
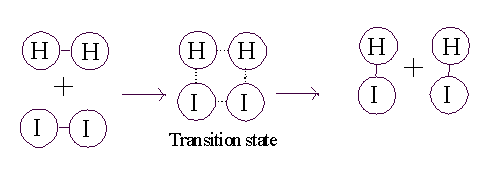
So for the reaction to proceed, you only need to produce a transition state, and the energy needed to get to a transition state is called the ACTIVATION ENERGY.
See [Purves6ed 6.11a; 7th 6.8a], [Purves6ed 6.11b; 7th 6.8b], [Purves6ed 6.11c; 7th 6.8c] and [Purves6ed 6.12; 7th 6.9].
CATALYSTS ACT BY REDUCING THE ACTIVATION ENERGY. See [Purves6ed 6.14]; 7th 6.11. Without a catalyst, you need a forceful collision to get to the TS. Very few molecules can muster it. But, for our reaction here, if we add a third substance, if we add some powdered platinum, the reaction proceeds almost instantly. The platinum can bind both reactants, so that many of the hydrogen and iodine gas molecules find themselves as neighbors on the surface of the platinum. More like bedfellows, as they can be closely packed. So closely, that they can form a transition state right there on the surface of the platinum particle:
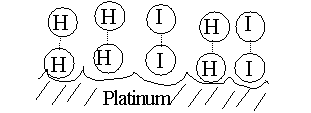
The platinum makes it easier to get to a transition state, no forceful collision is required, the two participants (reactants) just bind close together on the common binding surface. And binding to the Pt also weakens the H-H bond and the I-I bond, making it easier to now form the H-I bond. The CATALYST IS NOT ALTERED, it just speeds up the reaction. The catalyst does not change the situation with respect to the spontaneity of the reaction (energy releasing character, or DIRECTIONALITY, refer back to energy diagram), it just speeds things up. {Q&A}
[See animation (2 MB file though... probably not worth the wait unless you are connected to the CU network)].
Chemical catalysts such as Pt can speed things up 10,000 fold, so they are important in the chemical industry.
(Enzyme specificity)
Proteins act as catalysts
in a way similar to that described for platinum last time; they providing a
surface that facilitates the formation of a transition state complex for the
reactants by bringing together the reactants (or
substrates as the reactants that bind to such a protein are
called). They also often influence the bonds in the substrates to facilitate the
formation of new bonds. THEY DO NOT INFLUENCE THE DIRECTION OF THE REACTION,
ONLY THE RATE. (Look back at the energy diagram: one cannot reverse the
thermodynamic facts of life, the direction of the reaction is determined by the
relative energy levels of the reactants and products in the diagram). Such
biological catalysts are called enzymes.
Most enzymes are proteins, and a large fraction of proteins are enzymes. But
RNA, a nucleic acid, can also act as an enzyme catalyst, although so far few
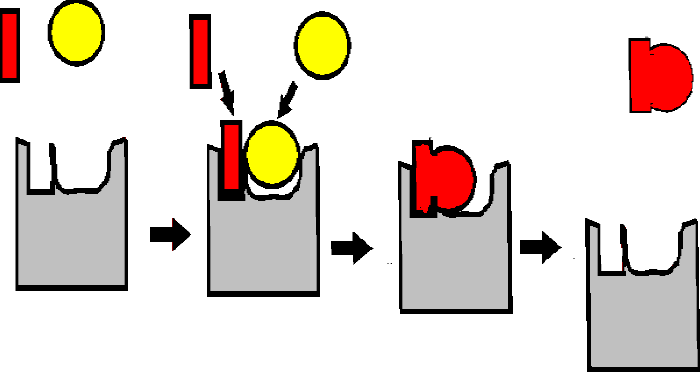
such reactions have been identified. The surface pocket in the enzyme where the
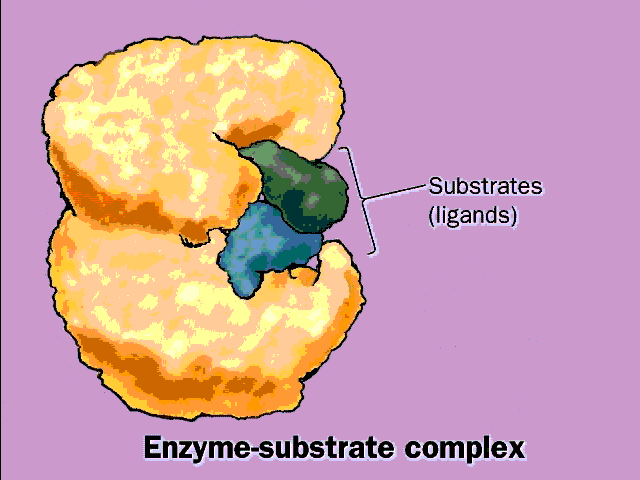
chemical transformation of the substrates takes place is called the
ACTIVE SITE of the enzyme. See
picture, and
[Purves6ed 6.15a; 7th 6.12a].
Unlike the Pt catalysts, which can bind many different kinds of molecules, protein surfaces can act with great specificity with respect to their substrates, being tailored to the charge, the shape, and/or the hydrophobicity of the substrates. See [Purves6ed 6.13; 7th 6.10]. The surface pocket provides the specificity:
(Remember the ala and gly binding protein models surfaces we just discussed as simplified models of how such specificity can be achieved...)
For example, Pt will also catalyze the hydrogenation of C=C double bonds. It will do this for any C=C bond, including those double bonds we first met in the description of unsaturated fatty acids, making peanut butter or margarine. Whatever fat you try, works.
(Substrates &
products)
But consider an enzyme, let's say the
enzyme succinic dehydrogenase that catalyzes the hydrogenation of the
unsaturated dicarboxylic acid fumaric acid (or fumarate,
for short) [are you getting all these terms?]
succinic dehydrogenase
HOOC-HC=CH-COOH ---------------------------------------> HOOC-CH2-CH2-COOH
+ 2H
fumaric acid
succinic acid
Note the enzyme name, an indication that enzymes do not alter the direction of the reaction: here it is named for the reverse reaction (a dehydrogenation), which it also catalyzes. Compounds that are NOT substrates for this enzyme include:
1-hydroxy-butenoate: HO-CH=CH-COOH (OH instead of one of the carboxyls)
cis-fumarate (called maleate):
maleic acid: HOOC-CH=CH-COOH (H's on the central C's here are cis (on the same side of the C=C double bond); in fumarate the H's are trans (on opposite sides of the C=C double bond):

Thus the 3-D structures of the small molecules, as well as of the proteins, are critical. They must be the right shape to fit. So unlike chemical catalysts, enzymes are highly specific about the reactions they catalyze because they are highly specific about the substrates they bind. See animation (This is a 4 MB download),
In summary, enzymes bind SUBSTRATES with great specificity, and they lower the activation energy for the chemical reaction that converts these substrates into PRODUCTS, thus greatly speeding up these reactions. It is the 3-dimensional shape of the pockets, usually at the surface of the proteins, that provides this specificity.
The texts give several examples of how specific enzymes act as catalysts.
© Copyright 2006 Lawrence Chasin and Deborah Mowshowitz
Department of Biological Sciences Columbia University
New York, NY
{kind=link}
{kind=link}
{kind=link}
![Purves6ed 3.9; 7th 3.11]](purves6/figure03-09.jpg){kind=link}
![[Purves6ed 3.7]](purves6/figure03-07.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![[Purves6ed 6.5; 7th 6.3]](../purves6/figure06-05.jpg){kind=link}
![[Purves6ed 6.11a; 7th 6.8a]](../purves6/figure06-11a.jpg){kind=link}
![[Purves6ed 6.11b; 7th 6.8b]](../purves6/figure06-11b.jpg){kind=link}
![[Purves6ed 6.11c; 7th 6.8c]](../purves6/figure06-11c.jpg){kind=link}
![[Purves6ed 6.12; 7th 6.9]](../purves6/figure06-12.jpg){kind=link}
![[Purves6ed 6.14]](../purves6/figure06-14.jpg){kind=link}
{kind=link}
![[Purves6ed 6.15a; 7th 6.12a]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure06-15a.jpg){kind=link}
![[Purves6ed 6.13; 7th 6.10]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure06-13.jpg){kind=link}