C2005/F2401 '06 Lecture #23
© Copyright 2006
Deborah Mowshowitz and Lawrence Chasin Department of Biological Sciences
Columbia University New York, NY
Last Updated:
12/08/2006 11:12 AM
(A few typos fixed after lecture. No substantive changes.)
I. Wrap up of Crossing Over & Linkage
A. How will an individual Meiosis go? See diagrams in last lecture, topic V-B. Suppose you start with parental chromosomes at meiosis (say AB/ab). What haploid products (gametes or spores) will you get from a single meiosis?
We've already considered two possibilities:
1. Type 1 -- No Crossovers. If there is no crossover in an individual meiosis you get all parental products. (Handout 22B, left fork in left panel or Becker 20-16, case (b).
2. Type 2 -- One Crossover. If there is one crossover event in an individual meiosis you get1/2 parental and 1/2 recombinant products. (Handout 22B "right fork" on left panel or Becker 20-14 or 20-16, case (c).
There is a third possibility (included below, but not on handout 22B):
3. Type 3 -- Multiple Crossovers. If there are multiple crossovers in one meiosis, there are several possible outcomes. Multiple crossovers (in any one meiosis) can give either all parental products or all recombinant ones or 50 - 50. (See diagrams in last lecture.)What happens in an individual meiosis depends on whether the total # of crossovers is even or odd and whether crossovers involve same pair of chromatids (crossing over more than once) or more than one pair (a different pair of chromatids for each crossover).
Note that the diagrams in the previous lecture notes show the possible results of any one individual meiosis. If you look at the pooled results of many meiosis with multiple crossovers, you get an average of 1/2 parental and 1/2 recombinant products. In a large sample of many gametes you never get all recombinant gametes -- you never get more than 50% recombinants. (More details below.)
B. How will Many Meioses go, Overall? How does it affect RF?
1. Why use RF? RF is calculated by examining the products of many meioses, not one. RF is used as an indication of the actual incidence of crossing over because we seldom examine the results of a single meiosis. Instead, we look at the total results from many meioses.
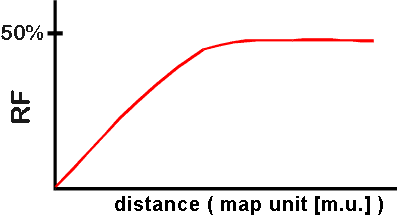
2. How will many meioses go? Suppose 2 genes (or mutations, or 'markers') are on the same chromosome. The chart below summarizes the correlation between RF, distance, type of individual meiosis, and types of gametes from a total of many meioses. The curve shows how RF changes with distance. Here are some of the possible cases:
a. If the 2 genes are very close, almost all meiosis are type 1, and almost all products are parental. As distance between the genes decreases, RF approaches a limit of zero.
b. If the 2 genes are close, but not as close, most meioses are type 1, but a few are type 2. Therefore most products are parental, but some are recombinant. RF will be small, but greater than zero.
c. If the 2 genes are farther apart (than in
previous case),
most
meioses are still type 1, but a larger percent are type 2. Therefore most
products are parental, but a larger percent (than in the previous case) are
recombinant. RF will be bigger than in the previous case. As long as there are
few or no meioses of type 3, the RF will be proportional to the distance between
the genes. See graph below -- you are in the linear part of the curve. Map
distance can be calculated from this part of the curve, as explained below.
d. If the 2 genes are far enough
apart, some meioses will be type 3.
If distance is far enough so there
are multiple crossovers, RF will not be proportional to the distance between the
genes. See graph below -- you are in the part of the curve that levels off.
(See below for why the curve levels off.)
e. If the 2 genes are very far apart,
a few meioses are type 1, but most meioses are type 2 or 3. Therefore products
are close to 1/2 and 1/2 recombinant and parental, and RF = 50%. This
means that genes far apart on the same chromosome will assort independently just
like genes on separate chromosomes [Becker 20-16, case (a) or Purves 10.8)]. In
both cases, you will get 50% recombinants and 50% parental, or RF
= 50 %.
Note: Whether genes are considered linked or not depends (by definition) on the ratio of recombinants/parentals. If the ratio is 1 (1/2 recombinants and 1/2 parentals, or RF = 50%) the genes are considered unlinked (genetically), whatever the physical relationship of the two genes. All that matters is whether or not each allele of gene A (A or a), has a 50% chance of ending up in a gamete with either allele of gene B (B or b). How it happens doesn't matter -- if it does, the genes are said to be unlinked.
Another way to see that genes far apart will assort independently: Suppose there are multiple crossovers between the genes. An odd number of crossover events will produce a recombinant; an even number of crossovers will switch it back, and produce a parental combination. If there are many crossovers, the number of even crossovers should be about equal to the number of odd crossovers, so the number of parental and recombinant combinations should be about equal. In other words, A is just as likely to end up connected to B or to b. (See picture in previous lecture -- at end, just before summary table.)
C. Summary of Relationship of RF & Map Distance
1. Curve of RF vs. Distance
a. Map Distance --
using the linear part of the curve
By definition 1% RF = 1 map unit. If the recombination
frequency between two genes is 1%, the genes are said to be "one map
unit" or 1 cM (centiMorgan) apart. RF is proportional to map distance
in the linear part of the curve.
b. Why does the curve level off as shown? As A and B get relatively far apart, multiple crossovers start to occur. The number of crossovers increases linearly with distance, but the number of detectable crossovers does not continue to increase linearly. This is because some multiple crossovers switch the A's and B's back to where they were in the first place. Only those crossovers that switch parental alleles to give new allele combinations can be detected and counted as recombinants. Multiple crossovers that switch the alleles back to the parental combination are not counted as recombinants -- they are considered parentals. If you take genetics, you will learn all the ins and outs of counting recombinants and measuring distances, but we will not go beyond this point. However you should note that the max. RF is 50%, not 100%. A single meiosis with several crossovers can produce 100% recombinant gametes, but if you look at the combined results of many meioses, you never get more than 50% recombinants overall.
2. Summary Chart -- What Happens When A-B Distance Changes?
| Distance | per meiosis | from many meioses | Overall | Linkage |
| As A-B distance declines | Type 1 -- no crossovers --most often | all parentals | RF → 0 | Approaches 100% (complete linkage) |
| As A-B dist. increases | Type 2 -- 1 crossover --more often | mostly parentals | RF is
proportional to distance |
Genes Linked (extent depends on distance) |
| As A-B dist. gets very large | Type 3 --multiple crossovers | 50/50 | RF levels off at 50% | Approaches none -- genes act unlinked |
To review the terminology and significance of crossing over, do problems 10-6 & 10-7.
D. Mapping -- How do you measure and use RF?
1. Do the Cross: Cross two double homozygotes to get a heterozygote, and then get heterozygote to go through meiosis and tally products of meiosis. If you cross AAbb X aaBB, heterozygote will be AaBb (either Ab/aB or AB/ab). If you cross two mutants with mistakes at different points in the DNA, cross will be like this:
| Parent 1 | X | Parent 2 |
----------> |
Heterozygote |
| ----x---------- |
|
----------x---- | ----x---------- | |
| ----x---------- | ----------x---- | ----------x---- |
2. Calculate RF. Once heterozygote goes through meiosis, classify haploid products of meiosis as parental or recombinant and calculate RF using formula as above.
(For many organisms, determining genotypes of products of meiosis cannot be done directly, and you have to look at the diploid organisms that are formed from the gametes. From the phenotypes of the diploid zygotes/organisms you infer the genotypes of the gametes. This is discussed in detail below -- see F.)
3. How you make a simple map.
a. The principle: RF is proportional to distance, up to a point, as explained above. Therefore, within the proper range (see below), map distances are additive, just like regular distances.
b. Units: 1% RF corresponds to 1 map unit (in the proper range). One map unit is also known as one centiMorgan or 1 cM.
c. Procedure -- An example: Suppose you want to order genes A, B and C, and you do the appropriate crosses. For example:
AB/ab --(meiosis)--> 14% Ab and aB
Bc/bC
--(meiosis)--> 4% BC and bc
Then RF between gene A and gene B is 14% and distance is 14 mu or cM; RF between B and C is 4% and distance between them is 4 mu or cM. This puts C 4 cM from B, but could be on side nearer to A or away from A. How do you tell which case it is? You need to measure the RF between A and C. It will be 10 or 18%, depending on whether order is A-C-B or A-B-C. For a typical map, see Purves 10.23.
4. Why maps are not completely additive.
a. How crossovers are counted. Double crossovers and no crossovers both → parental allele combinations in the gametes and are counted as "parentals," so RF's don't really count # switches, but approximate it -- RF's really measure the # of parental or recombinant combos in products of meiosis. (See legend to graph.)
b. When you can ignore multiple crossovers. If you stick to low values of RF and distance, in the linear part of the curve, then you can ignore multiple crossovers, and RF and distance are proportional. For most purposes, values under 25% are considered ok. If you use larger values, you have to correct for multiple crossovers. (How to do so will not be discussed here; it will be covered in genetics courses.)
To go over how to relate RF and map distance, try problem 10-11, parts A-D.
To review complementation vs crossing over and get practice making a map, try problem 11-14. (Note that in this problem, crossing over is occurring between mutations -- locations on the DNA as shown in example above -- as vs. between genes A and B.)
E. When and how does crossing over occur? Some details to review and/or notice. This is for reference; will not be covered in class.
We sometimes draw crossing over as if there were two single chromosomes (one chromatid per chromosome) involved like so:
| ------A-----------B------- | --------A-------b----- | |
|
X |
→ |
|
| ------a------------b------- | --------a--------B----- |
But sometimes we draw crossing over as if occurred when each chromosome is already doubled, and there are 2 chromatids per chromosome. (See pictures below.) Which is it?
1. Each single crossover event involves one pair of chromatids, but crossing over occurs at a stage (prophase I of meiosis) when there are 4 homologous chromatids, 2 per chromosome.
2. Crossing over happens only at meiosis (pro. I), not mitosis. Only affects next generation, not the generation in which it occurs. If crossing over occurs in the germ cells of a multi-cellular organism, the gametes of the organism are changed, but the somatic cells of the organism are unaffected.
3. Crossing over requires at least two things
a. Enzymes for pairing, cutting, and rejoining of DNA. Some of the enzymes involved are probably the same ones as for repair of damaged DNA.
b. Homologous DNA sequences.
4. Why does it occur only in meiosis? Some of the necessary enzymes for pairing, cutting and rejoining are active only in germ cells at pro. I. (Homologous DNA's are present in all 2N cells.)
5. Each crossover involves an actual cut and rejoining between two molecules. This has some consequences.
a. Crossing over is Reciprocal. Every time there is a cut and rejoin that produces, say, Ab, a reciprocal aB is also produced.
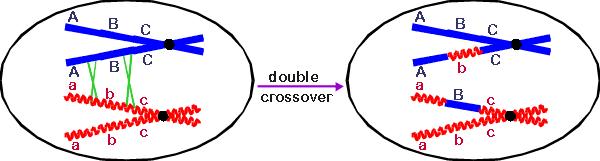
b. A double
crossover involves 2 separate events. A double crossover requires two separate cut and
rejoining events.
In the case shown below, both events involve the same pair of chromatids.
If ABC and abc crossover to give AbC and aBc, that's a double crossover -- it takes two
cut and rejoining events and is rarer than either one alone.
This has practical consequences. It
means that you can usually tell double recombinants from single recombinants,
even if you don't know the gene order, by seeing which types of recombinants
occur less frequently. This often helps to establish gene order. For
example, in this case, since the genes are in order of A-B-C, then ABc and abC
recombinants should be more common than AbC and aBc. If the order of genes were
A-C-B, then AbC -- really ACb -- would be more common than ABc --really AcB --
and so on.)
To review crossing over, map units and
the effects of double crossovers, see problem 10-8. (Note this problem is about a
haploid organism with an unfamiliar life cycle. Be sure you know the answer to
part A before continuing.)
F.
How do you count recombinants in a diploid organism?
See
handout 23A (on web only)
You can't look directly at gametes -- you need to look at zygotes. To make the results easier to analyze, you usually make one parent doubly heterozygous and one doubly homozygous recessive. (See note at ** below.) In other words, you do a test cross and analyze zygotes. (Test cross = Any cross where one parent is homozygous recessive for all genes under consideration.) Advantages of a this particular set up:
(1). You don't have to worry about crossing over in the homozygous parent. (If it occurs, it has no effect on the gametes.)
(2). Homozygous parent is doubly recessive, so you can deduce genotype of zygote (and genotype of gamete from heterozygous parent) from phenotype of offspring.
You can
classify each zygote as parental or recombinant (that is, coming from a parental or
recombinant gamete) from its phenotype. For example, in Ab/aB X aabb, suppose
you get A_B_ pheno
offspring. Then
(1) What goes in the blanks? Has to
be a and b.
(2). How was the zygote formed -- from recombinant or parental
gamete from Ab/aB? Must be AB gamete from double heterozygote parent met ab from
homozygous recessive parent.
Details of how to measure the RF in a diploid are explained on
Handout
23A = How to
measure RF's
with diploids. (http://www.columbia.edu/cu/biology/courses/c2005/2n_rf06.html)
For an example of such a cross, see Purves 10.19 &
10.22. (These are both about the same cross.) For an example of how you use the
results to make a map, see 10.24.
**Note: If you did a cross with fruit flies in intro lab, you may have set it up differently because there is no crossing over in male flies.
For problems measuring RF in diploids, see problems 10-10, 10-11E, and 10-12 to 10-14. (There are additional problems on this in 10 and 10R.)
II. Population Genetics
A. Intro. We need to shift from "How do things work?" to "How did they get that way?"1. The Question : We know how mutations occur, but why do some spread and others do not? Why is blood type O more common than B? Why is CF commoner in whites, Sickle Cell Disease (SCD) in blacks? Why do genes for drug resistance change, but gene for cytochrome c stays the same! Why is there more variation in introns than in exons? In other words, how did the particular state of affairs that now exists come to be this way?
2. The short Answer: How did we get this way? All the available data indicates it happened through evolution by natural selection. Provides answers to all questions in (1). Will fill in details below.
3. Importance of Populations. We need to look at genetics of populations, not just genetics of individuals to answer these questions. For example, how do you get from population of sensitive flies to population of resistant flies? (Mutation does it for one fly, but how does it spread?)
4. So how do you analyze change in a population? This is the next topic. First we'll consider what happens when there is no change; then how change occurs.
B. How to treat Genetics of Populations vs genetics of individuals (for diploids)
1. Consider a specific case -- if everybody is Aa, what is the genotype of the population, and will it stay that way?
a. What is the genotype of this population (= genetic structure of population)?
f(a) = f(A) = 1/2; F(Aa) = 1; f(aa) = f(AA) = 0. [f(a) means frequency of allele a, and so on.]
b. What will next (F1) generation be? Since
the only possible cross is Aa X Aa, you will get 1:2:1 (AA:Aa:aa) in the F1
generation. So after one generation, genotype of population is:
f(a) = f(A) = 1/2;
F(Aa) = 1/2; f(aa) = f(AA) = 1/4.
c. What will next (F2) generation be? Either "pot" reasoning (see below) or considering all
possible individual crosses will show you that the F2 generation will
have the same genotype as the F1 if you
assume
(1). Random mating (Choice of a mate is made at random. Therefore chance of a
particular cross, say AA X aa, depends only on frequency of parental types (AA
and aa) in population.)
(2). Large population (There are many matings and many offspring, so
gametes and zygotes made are representative of the whole population. )
(3). No selection (Everyone has equal chance of finding a mate, and same average # offspring for each type of cross
-- therefore AA, aa and Aa have an equal chance of passing on their alleles).
Note random mating is not the same as no selection.
d. What is "pot" reasoning? Assume all alleles of population are in one "pot" (usually called the gene pool) something like a lottery drum. Can think of pot or drum as full of slips; each slip has one allele written on it. In this case, there are lots of slips and 1/2 have "a", half have "A." Chance an individual will be born of genotype AA is same as chance you will pick two slips with "A" out of the pot (if you have two honest, independent, picks). In this case, chance of picking AA is 1/4, chance of picking aa is 1/4 and chance of picking Aa = 1/2. (1/4 chance of Aa + 1/4 chance of aA)
2. Genetic equilibrium. What if you start with 1/2 AA and 1/2 aa? Same as above by F1! (If there is random mating, etc.) So call 1:2:1 genetic equilibrium if start with two alleles A, a, and have 1/2 A and 1/2 a. Equilibrium is reached in 1 generation and stays that way. This is the expected result if pot with 1/2 A and 1/2 a is well mixed.
3. General case = Hardy-Weinberg Law
a. What is the
H-W law? It is the general statement (as opposed to the specific example given above) of
what proportions (of alleles and genotypes) you should have at equilibrium. Or, if you
start with two alleles not necessarily at 1/2 and 1/2, what happens?
Call f(A) = p; f(a) = q. Then p + q = 1 since every allele is either A or a. At equilibrium:
f(AA) = p2; f(aa) = q2, and f(Aa) = 2pq, and p2 + 2pq + q2 = 1, since every individual is either AA, aa, or Aa.
b. How did we get this?
You can arrive at the H-W law by considering what will happen if you
have a big pot full of slips; the fraction with A is p; the fraction with a is q; then
consider the chance of picking two slips with A, two with a, etc. as above.
c. What is the genotype of a population ?. Genotype of Population (aka "genetic structure of population") is described if know f(A), f(a) and f(AA), etc. = allele frequencies and genotype frequencies.
(1). If population is in equilibrium, entire genotype of population follows once you know p and q. If you know frequencies of alleles, you can calculate frequency of genotypes using the H-W law. (Or vice versa.) Some examples are given below.
(2). If population is NOT in equilibrium, you can still define the genotype of the population if you know f(A), f(AA) etc. However you can NOT calculate the proportions of genotypes from the allele frequencies (or vice versa) using the H-W law. You have to use the "seat-of-the-pants" method as described below.
d. What good is all this? Can use H-W law two ways.
(1). To check if population is in equilibrium.
(2). If you know population is in equilibrium, can use H-W law to figure out proportions of carriers, affected people etc.
Important: This whole business is not as trivial as it looks (if you know algebra) and not as intimidating as it looks (if you are not happy with math). This is illustrated in examples below.
C. Implications of H-W Law for Evolution
Assuming random mating, no selection and so on, frequency of A and a do not change over time -- A doesn't spread and a doesn't get lost. Even though a heterozygote has the A phenotype (If A dominant to a), allele a is passed on as well as allele A. So variation doesn't get lost -- it is not mixed in and diluted out as in blending inheritance. This is H & W (& Mendel's) big insight and is critical to evolutionary arguments. Darwin didn't know about particulate inheritance and it caused him a lot of worry -- he didn't know why variation stayed around. (Mendel knew about Darwin but not vice versa.)
D. Some examples of use of H-W
1. How to use frequencies, assuming equilibrium
Cystic Fibrosis = CF = most common genetic disease among whites. It's recessive. Person with disease is aa.
Know CF = 1/2000 live births. How many carriers (heterozygotes without symptoms) are there?
f(a)2 = f(aa) = 1/2000 = 5 X 10-4 ; therefore f(a) = √ (5 X 10-4) = about 2 X 10-2.
2pq = 2 X (1 - 2X10-2) X 2X10-2 = about 4 X 10-2 = 4/100 = 1/25. That's a lot of people.
Over 250 million people in USA, so at least 107 are carriers; therefore screening is worth it.
At the moment screening is not yet feasible in general population because several different mutations can cause CF. It's easy to screen for those who have the commonest mutation, but that picks up only about 75% of the carriers. It is relatively easy to screen for carriers in families who already have one affected individual, because in these cases the mutation involved is known.
For a similar problem on how to use the H-W see 14-1. For more practice with the H-W law, try 14-2 , 14-3, and 14-6 parts A. & B.
2. How to use the H-W law to test for equilibrium. 2 examples with MN. (M & N are surface proteins found on blood cells. M and N are coded for by two co-dominant alleles of the same gene. See problem 9-2.)
a. The method. You don't need to check each generation separately to see if we have reached equilibrium. Only need to check proportions of genotypes and alleles of the total population and see if it all fits the H-W distribution.
b. Here are two cases:
| Case 1 (real situation in US) | Case 2 (fake) |
| MM = 30% | MM = 25 % |
| MN = 50 % | MN = 60 % |
| NN = 20 % | NN= 15 % |
| f(M) = √ .3 = .55 = p | if plug in, f(M) = √ .25 = .5 |
| f(N) = √ .2 = .45 = q | f(N) = √ .15 = .4 |
| p + q = 1, ok. | p + q not = 1, not ok. |
| This population is in genetic equilibrium. | This population is not in genetic equilibrium. |
c. Is
non-equilibrium
possible?
The second example (case 2) is given to show that not every population is in genetic
equilibrium. When you first see this set up, there seem to be so many variables that it
seems impossible not to be able to get everything to fit. But case 2 illustrates that you
may have proportions of genotypes that are not compatible with equilibrium. In other
words, it is impossible (in case 2) to find values of p and q such that f(MM) = p2
etc.
d. How do you get p
and q if there is no equilibrium?
In case 2 have to use the bean counter or a "seat of the pants" method to get the
actual frequencies of M and N. You can NOT use the H-W law to get p and q.
How to do it: Figure out how many slips in the "pot" have M on
them and how many have N. One way to do this is to start with 100 people, and assume each person
contributes 2 slips to the pot for a total of 200. If person is MM, both slips have M on them,
if person is MN, half the slips have M on them, etc. In case
2, number of slips with M = 50 from MM's, and 60 from MN. So f(M) = (50 + 60)/200 etc.
Note that in case 2, the values of p and q
are the same as in case 1. However the population structure (or genotype of the
population) is NOT the same -- the genotypes are
different even though the allele frequencies are the same. (For some similar
examples, see Purves 21.6.)
For problems on how to use the H-W law to test for equilibrium, try 14-4 (A & B), and 14-14 part B.
III. How is all this related to evolution?
A. Intro: If a population is not in equilibrium, as in case 2 of MN, why not?B. Consider the assumptions behind H-W
D. If there is no genetic equilibrium, why not? What are the possible causes? Which of the assumptions listed above don't apply? Could be:
How each of these factors affects the distribution of alleles and genotypes is discussed in detail below.
E. What is Evolution?
1. One (reductionist) definition is: Evolution = change in genotype of a population. How this happens is discussed below.
2. Evolution is often divided into two aspects: Micro vs macro evolution. What's the difference?
a. Macroevolution: How do you get from 1 species → 2? Dinosaurs to birds? Are all living things descended from one common ancestor?
b. Microevolution: How do you get from light colored bears → dark colored bears? Sensitive bacteria to drug resistance bacteria? Why does one allele (say i) get more common while another (such as IB) gets rarer?
3. Current approach: We will stick mostly to microevolution, but macroevolution is thought to work in a very similar way, just over longer time periods and involving greater changes in the DNA. Next term we will work in a little about how molecular structures of eukaryotic cells imply macroevolution and common descent of all living organisms.
IV. Consider the possibilities (for causing deviations from H.W. equil.) and their consequences, 1 at a time.
A. Nonrandom Mating (NRM)
1. Definition. NRM = not mixing the pot.
The probability that A will meet a to → an Aa person is not simply proportional to
the frequencies of A and a in the pot.
2. An example:
Suppose that MM mates with NN preferentially ("opposites
attract"). Or conversely, suppose MM prefer to marry MM and NN prefer NN etc.
("birds of a feather flock together"). Either case is nonrandom mating,
and proportions of MM, NN etc.will not be as predicted by H-W, but freq. of M and N in the
pot will not change (assuming no selection = everyone is equally likely to
marry, and # kids/marriage constant -- see below). This means we don't have evolution --
no change in make up of gene pool or pot. We have a kind of equilibrium, but it is under
non standard conditions and it is not what is usually called "genetic
equilibrium." It is called non-HW equilibrium or an unusual population structure.
The population is in equilibrium, since frequencies of alleles and genotypes
don't change, but it's "non H-W" because the proportions of genotypes
don't fit the H-W law.
Note that the first possibility discussed above, "opposites attract" is one possible explanation for case 2 above.
3. How does NRM compare to selection?
NRM = selection of mate is not random with respect to genotype (=
unequal mix of pot); however all individuals are just as likely to find a mate and pass on their
alleles. There is no favoritism in who gets to reproduce. The only favoritism or choice is
on whom you chose for a partner.
Selection = nonrandom selection of alleles to be passed on (= favoring
pick of A over a or vice versa either directly or otherwise). In this case, there is
favoritism in who gets to reproduce. Ex. of selection as typically stated -- MM have more
kids on average than NN. (This case changes what's in pot in next generation.)
Nonrand.
mating alone doesn't change the proportions of M and N in the pot, but it does
affect the chance that M will meet another M (or N) and thus affects the
relative proportions of MM, NN and MN.
B. Mutation & migration
1. Mutation =
Changing slips in pot;
this is very important in the long run but doesn't drive the system in the short
run. Amount of current variety is enormous. (This shown by electrophoresis of proteins,
restrict. fragment analysis of DNA, etc. Something like 1/100 bases of people are different.)
Mutation has been going on so long that the current supply of variation is
enormous, and the variety added by ongoing mutations is small. Most 'new'
variants are not new mutations but new combinations of old mutations generated
by sexual reproduction. So in most cases,
changes in a population are likely to be due to changes in the proportions of
mutations that are already present, not to new mutations.
Another way to ask this: Does change need to wait for "right"
mutation or is the variant usually already there? Maybe, in some cases, esp. with
haploids, you do need to wait for mutation to occur. But generally thought not. (Because
of high variation levels in all existing populations.)
So big question is, why do some mutations spread while some
die out?
2. Migration
(also called gene flow) =
adding to pot from another one; effects are important but relatively obvious.
C. Small populations and/or sampling errors = statistical fluctuations that occur as a result of only picking a few alleles from the pot to pass on from generation to next = genetic drift.
1. Basic idea -- small samples are not representative of the total population. Ex: flipping coins. If flip only a few, don't get exactly 1/2 and 1/2 heads and tails. Call all effects of small sample size genetic drift = changes in allele frequencies in small pop. due to chance.
2. Types of Drift.
a. Founder effect
-- what happens when a small group goes off to start a new colony or
population. Small group of founders may not be a representative sample, just by chance.
One way to state f.e. = starting population usually has less variation than population it
came from. Founder effect means population starts with "atypical" gene pool,
relative to where it came from.
b. Bottlenecks
Bottlenecks =
severe reductions in size of population. Bottlenecks can change the
allele frequencies in two ways:
(1). Bottleneck effect. What gets through the bottleneck is atypical, so the population "starts over" with a gene pool that is different from the original population. This is similar to the f.e. as described above. (In the case of either the founder effect or a bottleneck, you "start over" with a small atypical population derived from a bigger one. In the case of the f.e., the small population leaves the bigger one and starts a new group. In the case of a bottleneck, the population stays in place but is greatly reduced in size by plague, predation, war, etc.)
(2). Statistical Fluctuations. The population remaining after the bottleneck is so small that statistical fluctuations in the future may cause significant changes in allele frequencies. (This is genetic drift in the "specific sense" as defined below.)
c. Terminology:
Genetic drift can be used two ways, in a general or specific sense.
(1).
General Sense: Genetic drift can be taken to mean any kind
of change in allele frequencies due to small sample size. This is the usual
textbook definition, and includes all the changes in small populations due to
bottlenecks, founder effects, and statistical fluctuations.
(2).
Specific sense: Genetic drift can mean the change in allele frequencies due to the
cumulative effect of statistical fluctuations from many generations of small samples
(which all just happen by chance to deviate in the same direction).
The second type of genetic drift occurs after a population
passes through a bottleneck (for the usual reasons -- plague, war, or because of founding of a
new small population.) It might be better to call the second kind of genetic drift
"a multiple generation drift effect" or some other specific term. It can be layered on top of a
founder/bottleneck effect or it can occur independently. For example, if a small
population (of founders or survivors) is typical, there is no founder or direct bottleneck
effect, but allele frequency can drift up or down due to statistical fluctuations as long
as the population remains small.
See problems 14-5 (A & B) & 14-6 (esp. C) for how to tell these various kinds of genetic drift apart.
D. Selection -- why this is clearly a major player (or chance vs selection)
1. How important is chance? Genetic drift in small populations does occur, and other effects of chance are important too (asteroids?). Is chance a major factor in change that has occurred? Or from another angle, is most of variation you can see now from species to species or individual to individual due to chance? Exact proportion is debatable, but many differences are attributed to selection.
2. Why invoke selection?
a. Most phenotypic
differences seem adaptive (= make sense, don't seem random) -- match differences in
environment, life style, etc. Variants are not randomly distributed. Examples
(1). Bears -- light colored ones with heavy fur are in icy North -- Alaska; darker ones with not-so-heavy fur are in temperate forests -- Yellowstone. Selection explains this; chance doesn't.
(2). Variations in introns vs. exons. There is more variation in intron sequences and in the 3rd position of codons than there is in exons overall. Why should this be? Because selection acts against most changes in exons that alter amino acid sequence while there is little or no selection favoring (or disfavoring) changes in introns, spacers, etc.
b. Selection works well in lab/life -- breeding of domestic plants & animals, DDT resist. flies, color of moths etc. Works with domestic dogs, pigeons, cows, corn, etc. (intentional) or drug/pesticide resistance (unintentional).
3. How does selection work?
a. Basic scheme that fits all the data is as follows:
(1). Random variation
occurs by mutation; sex reshuffles the variants. Mutation is random with respect
to function; the environment does not cause the variation to suit need.
(Mutation = changes in DNA sequence or number of copies due to mistakes in
replication, repair, crossing over or distribution.)
(2). Selection acts on
phenotype (not genotype or individual alleles). Selection is NOT random with
respect to function. Selection = differential reproduction. Different
individuals make unequal contribution to gene pool of next generation (some genes/alleles
passed on more, some less); no change in genes or individuals.
Note: If A is dominant to a, both AA and Aa will be equally "fit"
and equally likely to pass on their alleles. (This is why "a" doesn't
disappear.) This is because fitness (and therefore ability to pass on alleles)
is determined by the phenotype of the whole organism; not by the genotype or by
individual alleles.
(3). Genotype of population changes (to fit environment) in next generation (populations, not individuals
adapt)
(4). Adaptation occurs.
- Fit to environment improves (innovative selection). That's why drug resistance spreads.
- Detrimental changes are lost and working proteins, structures etc. are maintained (conservative selection). That's why cytochrome C stays the same. (Variants that don't work well are lost.)
- Changes in genotype that have no effect on phenotype (neutral mutations) are not selected for or against. That's why there is more variation in introns than in exons & and many synonymous changes in codons.
b. An alternative way to write the basic scheme: random mutation → random change in DNA → random change in phenotype → selective reproduction (not random who has the most offspring) → change in population due to conditions of life = adaptation
c. An example: Up North, light colored (& heavy furred) bears are more likely to have kids and pass on their (light) color genes (& heavy fur genes) so light color and heavy fur spread and vice versa in Yellowstone. Bear with dark fur in Artic can't catch any seals -- prey sees him coming and he goes hungry. Bear with thick fur suffers heat stroke in Yellowstone. And so on.
d. Natural Selection is a Two Step Process. Mutation provides variation and then the environment "selects" which individuals (based on their phenotypes) will be most likely to pass on their variant genes/alleles. Note this is a two step process -- first variation occurs; then selection acts on the variants in a separate step. The first step is random (with respect to function); the second step is not. The process involves both 'chance' (random mutation) & 'necessity' (nonrandom selection for function).
For some problems on the role of selection, see 14-9 to 14-12. For problems on selection vs genetic drift, see 14-4 (part C), 14-5, & 14-6 (part C). There are additional problems on population genetics in problem sets 14 & 15 (15-3 to 15-5).
© Copyright 2006 Deborah Mowshowitz and Lawrence Chasin. Department of Biological Sciences
Columbia University New York, NY
Last Updated: 12/08/06 11:12 AM