C2006/F2402 '05 OUTLINE OF LECTURE #10
(c) 2005 Dr. Deborah Mowshowitz, Columbia University, New York, NY. Last update 02/23/2005 03:53 PM .
Handouts: 10A-C.
10A -- Regulatory Elements & Picture of a typical Eukaryotic Gene (not on web).
10B--
Alternative splicing; 10 C --
Regulation of intracellular Fe levels + cell cycle info (not on web).
Extra copies of
all handouts are in boxes on 7th floor of Fairchild.
I. Introduction to Regulation of Eukaryotic Gene Expression See notes of previous lecture.
II. Major features of gene regulation in Eukaryotes See notes of previous lecture.
III. Details of transcription in eukaryotes (as vs. prokaryotes) See Becker Ch 19, pp 640-644 (651-655).
A. More of everything needed for transcription in eukaryotes.
1. Multiple RNA Polymerases (see last lecture).
2. More Regulatory Sequences & Regulatory Proteins -- An Overview & Some terminology
a. Control elements/sequences -- Two types: cis & trans acting. (See table on handout 10A.)
Cis acting = affects only the DNA molecule on which it occurs. Usually is a DNA sequence that binds some regulatory protein.
Trans acting = affects target DNA sequences anywhere in the cell. Codes for a regulatory molecule (usually a protein) that binds to a target DNA sequence (The term "trans acting" can be used to refer to the protein or to the gene for the protein.)
In euk. the # of different types of cis and trans acting control elements is larger.
b. Regulatory Proteins -- Two Types. Regulation can be "+" or "-" depending on the function of the protein. Negative control seems to be more common in prok.; positive control in euk. (See table on handout 10A)
B. Details of regulatory sites in the DNA. Prokaryotes have promotors and operators. What sequences do eukaryotes have in the DNA that affect transcription? (The following discussion refers mostly to regulation of transcription by RNA pol II. See texts esp. Becker for details about promotors etc. for pol I & III.) See Purves Fig. 14.13 (14.15) or Becker fig.21-21 or handout 10A for structure of regulatory sites for a typical protein coding gene. Three types of regulatory sites:
1. Core Promotor
a. Structure. Usually divided into
(1). "Start" = Point where transcription actually begins (usually marked with bent arrow)
(2). Binding sites: Part where basal TF's and RNA polymerase binding starts -- often includes short sequence called a TATA box. Close to start (usually about 25 bases before start).
b. Numbering. Position of bases is counted from the start of transcription. For example:
(1). +10 = 10 bases downstream from start = 10 bases after start of transcription. (Downstream = Going toward the 3' end on sense strand = in direction of transcription)
(2). -12 = 12 bases upstream from start = 12 bases before reaching start of transcription. (Upstream = Going toward 5' end on sense strand = in opposite direction from transcription)
(3). +1 = first base in transcript; one that gets a cap.
2. Proximal Control Elements (Proximal = Near).
a. Location: Near core promotor and start of transcription; usually "upstream" (on 5' side of start of transcription.) Usually includes regulator elements up to -100 or -200 (bases).
b. Terminology: Sometimes considered part of core promotor.
c. Function -- binding of appropriate proteins promotes or inhibits transcription. Identified by effects of deletions. Sequence and mechanism of action varies.
3. Distal Control Elements (Distal = Far)
a. Two kinds: Enhancers & silencers. These control elements can decrease (silencers) or increase transcription (enhancers).
b. These can be quite far from the gene they control (in either 5' or 3' direction = upstream or downstream) and work in both orientations (see Becker fig. 21-22), unlike promotors.
c. Mechanism of action -- DNA thought to loop around and silencer/enhancer helps stabilize (or block) binding of TF's directly or indirectly to core promotor. (See Becker fig. 21-23 or Purves 14.13 (14.15) and section on regulatory TF's below.)
4. Terminology & Misc. Details -- this is for reference; may not be discussed in class.
a. Boxes = short sequences that are found in regulatory regions (ex: TATA box)
b. Consensus sequences = sequence containing the most common base found at each position for all sequences of that type. Any individual version of sequence is likely to be different from the consensus at one or more positions. (Ex: TATAAAA = consensus sequence for TATA box)
c. For multicellular organisms, term "operator" is not used for site/DNA sequence where a regulatory protein sits. Why? Because no polycistronic mRNA & no operons in higher eukaryotes. (Are some in unicellular euk.)
C. Details of regulatory proteins or TF's = transcription factors
1. Basal TF's. Needed to start transcription in all cells. (See Purves fig. 14.12 (14.14) or Becker fig. 19-14.)
a. Many basal TF's needed.
b. Basal TF's for RNA pol. II.
(1). Terminology: Basal TF's for pol II are called TFIIA, TFIIB, etc.
(2). Major one is TFIID; it itself has many subunits. Most studied subunit is TBP (TATA binding protein -- See Becker fig. 19-15.) Recognizes TATA box when there is one.
(3). Other polymerases have TF's too, but TF's for pol II are of major interest, since pol II --> mRNA
c. Basal TF's bind first to core promotor, and then RNA pol binds to them. Takes a lot of proteins to get started. RNA polymerase does not bind directly to the DNA.
2. Regulatory or Tissue Specific TF's -- used only in certain cell types or at certain times. See Becker fig. 21-24.
a. Bind to areas outside the core promotor -- usually to enhancers or silencers (distal control elements) but sometimes to proximal control elements
b. When regulatory TF's bind, can decrease or promote transcription.
(1). Activators. TF's called activators if bind to enhancers and/or increase transcription.
(2). Repressors. TF's called repressors if bind to silencers and/or decrease transcription.
(3). Co-activators. Proteins that connect TF's to each other (but don't bind directly to the DNA) are often called co-activator (or co-repressor) proteins.
c. Co-ordinate control. A group of genes can all be turned on of off at once in response to the same signal (heat shock, hormone, etc.). These genes do not need to be near each other -- they just have to have the same control elements. See Purves 14.14 (14.16).
(1). Common control elements: All genes turned on in the same cell type and/or under the same conditions have the same control elements -- therefore these genes all respond to the same TF's. Result is multiple mRNA's, all made in response to same signal (s).
(2). Compare to situation in prokaryotes:
|
|
Prokaryotes | Multicellular Eukaryotes |
|
Co-ordinately controlled genes are |
Linked |
Unlinked |
|
Messenger RNA is |
Polycistronic (1 mRNA/operon) |
Moncistronic (1 mRNA/gene) |
|
Operons? |
Yes |
No |
|
Control elements are found |
Once per operon |
Once per gene |
| Control can be positive or negative but is more often | Negative --repressors needed to turn gene off | Positive -- activators needed to turn gene on. |
d. Structure & Function of regulatory TF's is modular
(1). Each TF has multiple domains.
(a). Each TF has a DNA-binding domain -- specific for particular sequence(s) and/or gene(s)
(b). Each TF has a transcription regulation domain (also called trans acting domain or in many cases transcription activating domain) -- determines effects of DNA binding by given TF (activation vs inhibition of transcription)
(c). TF's that are hormone receptors also have a hormone-binding domain.
(d). TF may have additional domains, such as dimerization domain. Many TF's must dimerize to work. (Monomer is inactive.) Some form dimers with other molecules of the same protein (result is a homodimer) and some form dimers with a different protein (result is a heterodimer).
(2). Modules (domains) can be switched -- Recombinant DNA methods can be used to make hybrid TF's. This has many uses in research; some examples are in later problem sets.
(3). How do regulatory TF's act?
(a) By binding to control elements with their DNA-binding domains, and(b) Binding to other proteins with their transcriptional regulation domains. "Other proteins" can be basal TF's or other regulatory TF's (or to co-activator or co-repressor proteins)
(4). Types of DNA-binding domains. These are often classified by the structural motifs in the DNA binding region. Some common motifs (secondary structural elements) found in DNA binding domains are listed below for reference only (FYI). For pictures, see Purves 14.15 or (p. 273 in 6th ed) or Becker fig. 21-25.
Zinc finger
Leucine zipper
Helix-loop-helix
Helix-turn-helix.
To review transcription, try problems 4-16 and 4-17 A.
IV. Domains & Motifs in General -- This section is included for reference
A. Terminology: The terms "domain" and "motif" are sometimes used interchangeably. Strictly speaking they are different -- A domain is considered a unit of tertiary structure, while a motif is considered a unit of secondary structure.
1. Domains. A domain refers to a discrete, locally folded unit of tertiary structure. It usually has a particular function (DNA binding, kinase, intracellular, etc.) and it may contain one or more motifs or unusual structures. Domains are sometimes referred to by their functions (such as DNA binding) or by their structures (for example, SH2). It is assumed that domains of common structure have common functions, but not necessarily vice versa. (All DNA binding domains do not have the same structure -- see above.) Domains are usually named after the first protein in which they are found.
2. Motifs. A motif refers to a region with a particular combination of secondary structural elements such as alpha helices, beta sheets, loops, turns, etc. A certain motif (such as a zinc finger) always has the same 3D structure.
B. Significance of Domains
1. Common structure implies common function. Existence of domain(s) of known function in a new protein is often used to deduce function(s) of the newly discovered genes/proteins. This is an important tool in analysis of results from the human genome project.
2. Common structure implies common origin. (FYI)
a. Same domains turn up again and again in different proteins (in different combinations). How did same domain end up in different places?
b. Domains & exons: Often one domain (in protein) corresponds to one exon (or group of exons) in DNA
c. Origin: Modular nature of proteins & genes (see a & b above) implies new genes may arise from reshuffling of old modules, not only from duplication and divergence of entire genes. One mechanism for reshuffling of exons & domains could occur as follows:
Two, nonhomologous genes pair up (by mistake). Recombination occurs in introns --> new combination of exons --> protein with new combination of preexisting functional modules (domains) encoded by separate exons.
To review transcription, try problems 4-16 and 4-17 A.
V. Regulation at Splicing -- Alternative Splicing
A. There are two ways to get a collection of similar proteins
1. Gene families -- multiple, similar genes exist due to duplication and divergence of genes. Example: the globin genes constitute a family. Different family members code for myoglobin, beta-chains, alpha-chains, delta-chains, etc.
2. Alternative splicing etc (See C below) -- only one gene, but primary transcript spliced in more than one way.
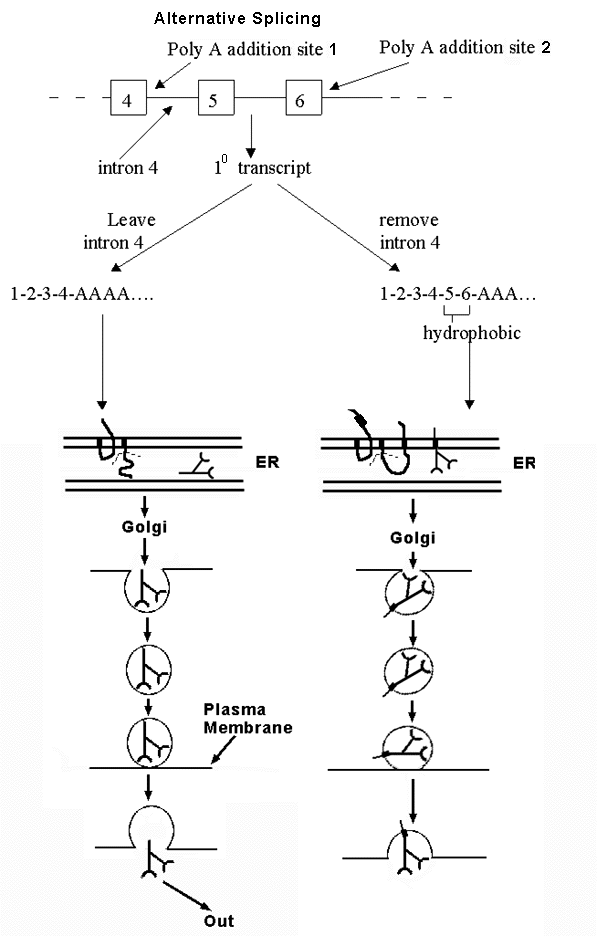
B. An example of alternative splicing -- see handout 10 B and Becker fig. 21-31 -- how to get either soluble or membrane-bound antibody from alternative splicing of the same transcript. (See Purves 14.20 for another example.)
1. Antibody can be membrane bound or secreted. Fate of antibody depends on whether peptide has a stop transfer sequence or not.
a. If has stop transfer: locks into membrane of ER and goes thru Golgi etc. to plasma membrane; stays in membrane.
b. If has no stop transfer: enters lumen of ER, goes thru Golgi etc. and then is secreted.
2. Gene has two alternative polyA addition sites. Which one is used determines final location of protein.
a. Option 1: If one (at end of exon 4) is used, protein contains no hydrophobic stop transfer sequence, and protein is secreted.
b. Option 2: If other one (at end of exon 6) is used, protein contains hydrophobic sequence encoded by exons 5 & 6, and protein stays in plasma membrane.
3. mRNA can be spliced and/or poly A added in two alternate ways. Location of protein (antibody) depends on whether splicing of intron 4 or poly A addition happens first. Think of it as a competition. Either
a. Poly A adding enzymes get there before the spliceosome. In that case, poly A is added to site near end of exon 4, and rest of intron 4 (and rest of gene) is never transcribed, or
b. The spliceosome gets there first. In that case, Intron 4 is transcribed and spliced out before poly A can be added. (In this case, poly A is added at the end of exon 6 instead.)
4. Why are 2 forms of antibody needed?
a. Membrane-bound form of antibody: serves as receptor for antigen = trap to detect when antigen is present. Binding of antigen (ligand) to antibody (receptor) serves as trigger to start secreting antibody.
b. Secreted (soluble) form: binds to soluble antigen in body fluids and triggers destruction of antigen in multiple ways.
C. The general Principle -- You can get many different proteins from a single gene by the processes listed below. Therefore biologists are interested in proteomics (study of all proteins made in a cell) not only genomics (study of entire DNA or gene content).
1. Starting transcription at different points
2. Ending transcription (adding poly A) at different points
3. Splicing out different sections (exons as well as introns) of the primary transcript -- alternative splicing.
To review regulation so far, try problems 4-9 to 4-11. To review the details of alternative splicing, try problem 4-12.
VI. Regulation at translation.
A. How to control rate of translation? In principle:
1. Can regulate half life of mRNA (control rate of degradation). In prokaryotes most mRNA's have a short 1/2 life; in eukaryotes this is not necessarily so. Different mRNA's have very different half lives. (Note: proteasomes degrade only proteins NOT RNA's. )
2. Can regulate rate of initiation of translation (control how effectively translation starts)
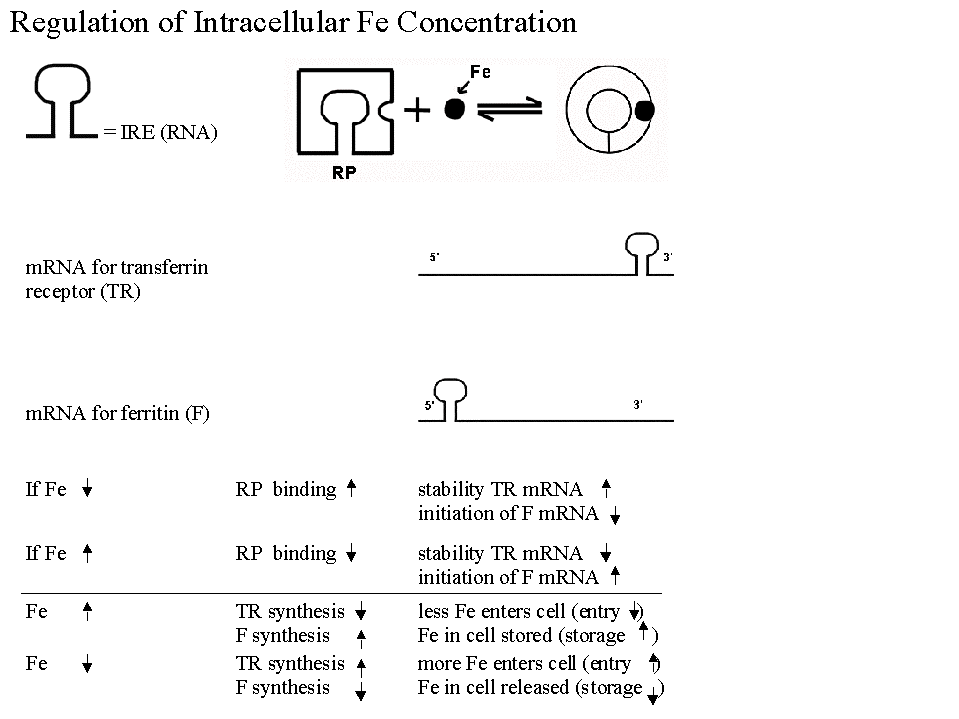
B. Most Famous Example of Regulation of Translation. Regulation of synthesis of Ferritin & Transferrin Receptor (& intracellular iron levels). See handout 10C & figs. 21-33 & 21-34 in Becker.
1. In best known example, have a regulatory protein with following properties:
a. Effect on degradation: Protein controls half-life of one message by binding to sequence at 3' end and blocking degradation.
b. Effect on initiation: Protein controls usage of a different message by binding to sequence at 5' end and blocking initiation of translation.
c. Protein is allosteric and has two forms -- binding of a small molecule effector (Fe in this case) determines which form protein is in, and therefore what effect(s) it will have.
d. Is this like repression? System is similar in many respects to induction/repression but regulator protein acts on a sequence in the mRNA (called an IRE - iron response element) instead of on DNA. Comparison to induction/repression:
|
Similarities |
Differences |
|
IRE = cis-acting site like an operator |
This RP binds to sequence on mRNA NOT to DNA |
|
RP = trans-acting regulatory protein like a repressor = allosteric protein with an allosteric effector (Fe) |
Binding of RP affects translation, NOT transcription. |
2. What are the important features of this system for cell function?
a. Works to stabilize intracellular iron levels
b. System is self-correcting -- Deviations in either direction (if iron is too high or too low) are corrected back to standard.
c. There are two opposing correcting factors or processes, not just one. (There are mRNA's for two proteins -- ferritin & transferrin receptor, and the two proteins have opposing effects, either raising or lowering intracellular iron levels.)
3. Negative Feed Back. A self-correcting system like this one is called a negative feedback system. More examples (& features) of negative feedback will be discussed when we get to homeostasis.
VII. Post Translational Regulation. Don't forget: regulation occurs after translation too -- after proteins are made, they can be modified. Many examples of post translational modification have already come up and more will be discussed below.
A. Proteins can be modified covalently either reversibly (for ex. by phosphorylation and dephosphorylation), or permanently (for ex. by removal of N-terminal met., addition of sugars -- glycosylation, etc.)
B. Proteins can be activated or inhibited by reversible noncovalent binding of other factors -- small molecule allosteric effectors, other proteins such as calmodulin, etc.
C. Proteins can be selectively destroyed.
1. Half Lives Vary. Not all proteins have the same half life.
2. Proteasome: Major factor in regulation of protein turn over is control of addition of ubiquitin leading to destruction by proteasome. (See NY Times Article from lecture 9, or Becker 21-36 or Purves 14.22 (14.21).)
3. Significance: Important example of a family of proteins that all have a short half life = cyclins; control progression through cell cycle. Different cyclins control G1 to S, G2 to M etc. Cyclins are made as needed and degraded immediately after use.
To review post-transcriptional &/or post-translational regulation, try problem 4-13.
V. Regulation of the Cell cycle -- See notes of Next Time.
Next Time: Finish Translational Regulation & do Regulation of Cell Cycle, then Introduction to Signaling. Bring Handout 10C.
{kind=link}
{kind=link}