Herbert S. Terrace, director
Here is a brief list of some recently completed experiments. Click on the experiment name for more info.
Metacognition: Matching to Sample MetaMTSS (using confidence judgements) Linear Configurational Learning Shared Mechanisms of Ordinal Judgement Conditional Spatial Discrimination
|
|
This experiment builds on previous numerical research with nonhuman primates. Our goal was to expand the range of numerosities on which rhesus macaques (Macaca mulatta) have been trained previously and to determine how a monkey represents those values. Results were compared to those of human subjects to compare enumeration mechanisms used on this task. Three primary questions this task addresses are:
Monkeys were presented with stimuli composed of geometric figures that differed in size, shape, and color. Cues including shape, color, element configuration, cumulative surface area, and element density were progressively eliminated to ensure reliance on numerosity rather than secondary cues. Additionally, stimulus elements were heterogeneous in color and shape. The sample was shown in a random location on a blue background. Touching the sample extinguished it, and following a one second delay, the test screen displayed the target and distractors on a green background. Correct responses were followed by a banana-flavored food pellet, a change in the color of the monitor, and a distinct sound. Incorrect responses were followed by a different distinct sound and a 4 second time out during which the screen was dark. Monkeys were tested with two stimulus continua: values 1-9 followed by values 1-15. Human subjects were tested with the same stimulus parameters as those of the monkeys, with the exception of a response time restriction to limit reaction times to the range of monkey reaction times. |
|
In an experiment closely related to Numerical Matching to Sample (above), we have been training two monkeys on another Matching to Sample (MTS) paradigm wherein they learn through trial and error to associate numerosity with the corresponding Arabic numeral. Once the training is complete, we will test the subjects to see if the Arabic numerals have not just taken on the discrete numerical value but have also taken on the corresponding ordinal properties.
|
|
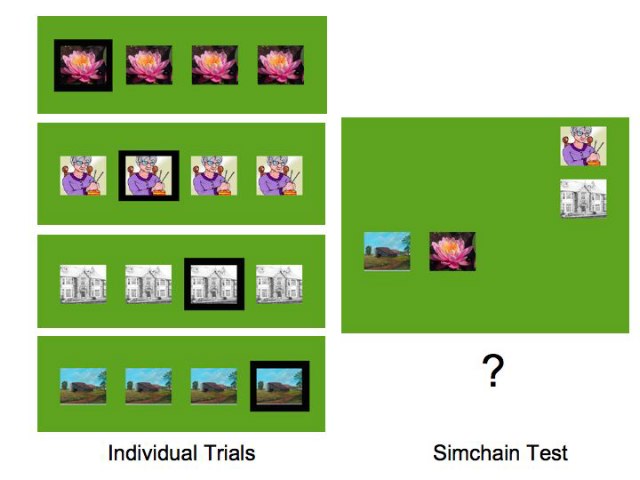
How far ahead do monkeys plan when they are executing a Simultaneous Chaining (simchain) list? To determine how many steps ahead the monkeys think, we began this two-part experiment in early 2009. Four monkeys were trained on a five-item simchain list, wherein they had to learn to respond to pictures A, B, C, D, and E in the correct order on every trial, despite the pictures appearing in different locations on the screen on each trial. We then began the first phase of testing. During probe trials, the physical position on the screen of two pictures shifted after a correct response to A, so, for example, C suddenly appeared where B used to be and vice versa. We believed that if we saw consistent errors to C on the second item, i.e., to the location where B used to be, that would show evidence of planning ahead. Indeed, that is what we found. As a counterpart to this shifting paradigm, we have begun to test planning ahead with the help of a masking paradigm. Here, after a correct response to A, the remaining items are covered with a grey mask and the monkey must complete the list in the correct order without being able to see the items. As the items are touched in the correct order, they are unmasked. Responses to items out of sequence end the trial.
|
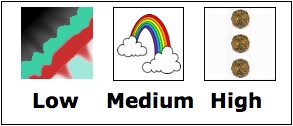
Metacognition: Matching to Sample with 3 Risk Choices The ability to make judgments on one's own knowledge is called metacognition, and for a long time was thought to be a uniquely human ability. In this experiment, we're not just looking for evidence of metacognition in monkeys but for the ability to appropriately choose the level of confidence they have in their judgments. Two monkeys have a history of succeeding in metacognition experiments and have since learned to distinguish three icons that relate to three levels of risk: low, medium, and high. In order that they may lose as well as receive rewards, they have a token hopper on the side of the screen that starts out with some tokens. When they receive enough tokens, they receive banana flavoured pellets.
The paradigm on which they are being tested is Matching to Sample (MTS), with varying numbers of distractors on both the sample and test screens. By increasing the number of distractors, we can make a trial more difficult. Blinking lines around the sample indicate that it's the correct picture and, as in other MTS tasks, during test the monkey must choose the same picture. Currently the monkeys are being tested on a retrospective paradigm, which means they make their confidence judgments after they have chosen the target picture. They choose from one of the three icons to indicate their level of confidence - essentially "betting" on how well they think they did - and are rewarded or punished accordingly. If they bet high and are correct, they win several tokens; if they bet high and are incorrect, they lose several tokens (and thus the opportunity for a pellet). If they choose the medium risk icon, they will win or lose a smaller number of pellets. If they bet low, they receive a pellet whether they're right or wrong. We hypothesize that when there are fewer distractors and therefore the test is easier, they will choose the high risk icon more often because they will be more likely to gain several pellets. Likewise we expect them to choose low or medium risk more often when there are more distractors and the test is harder. |
|
Using a basic Matching to Sample (MTS) paradigm, we've trained monkeys to distinguish between various categories, namely, birds, flowers, felines, and people. When the trial begins, a sample picture appears that the monkey has to touch, and after a brief delay a test screen appears with the target picture (that is, a picture that is the same category as - but not identical to - the sample) and 1, 2 or 3 distractors drawn from the other categories. In the next phase of the experiment, we will transition from a MTS paradigm to a Simultaneous Chaining (simchain) paradigm in order to determine whether category information can acquire ordinal properties. That is, can we train the monkeys to associate a particular place within a list based on category alone? To test this, we will present exemplars of all four categories at once and reinforce responses made to the correct picture in the correct position. One monkey may learn to always respond birds-felines-people-flowers, while another may be trained on people-felines-birds-flowers, for example. More than just examining the limits of learning categories, we want to see whether there is meaningful transfer of information from one paradigm to another.
|
Before testing the monkeys on a metacognitive task involving arbitrary pictures, we tested them on judgments of psychophysical tasks, such as identifying the longest line in an array. Then we used a working memory task (matching to successive sample), where the monkeys saw a series of pictures and then had to choose the familiar one from an array of pictures (only one of which they had actually seen before). Before finding out if they were right or wrong, the monkeys made a confidence judgement, or a "bet". If they chose high risk, they would earn 3 tokens following a correct response, and lose 3 tokens following and incorrect response. If they chose low risk, though, they were guaranteed one token. Each time the monkey accumulated a certain amount of tokens, they were given a food reward.
The results of this experiment will be published in Psychological Science in early 2007. For a video of Ebbinghaus doing this task, go to Videos.
|
|
Sequences contain two types of information, order and item information. The simultaneous chaining paradigm has already proven that monkeys are capable of remembering both types of information in long-term memory. However, studies looking at short term memory have yet to prove that monkeys can remember both. Individually, item information and order information has been proven for short term memory but whether the monkeys have the capacity necessary to remember both using short-term memory has been inconclusive. In HintRecall we provide list-items simultaneously and use hints to reveal the order of the list. Monkeys are required to press the item that is flashing, at which time the next item in the list begins to flash. Once they have gone through the list during the presentation phase of the trial they are then give a test. List items are displayed again without any hint to order. Subjects are required to press the items in the order given them during the presentation phase of the trial in order to receive reinforcement. The list varies from trial to trial so no long-term memory is required. This test requires short-term memory of both item and order information. |
|
Cognitive imitation was demonstrated in rhesus macaques that were trained on a serial task in which arbitrarily selected photographs had to be touched in a particular order. The position of the photographs varied randomly from trial-to-trial to prevent subjects from learning lists as particular motor sequences. List-naïve monkeys learned new lists more rapidly when they could observe an experienced monkey execute the list than when they had to learn lists in isolation, by trial-and-error. Control conditions ruled out social facilitation and computer feedback as explanations of that difference. This suggests a qualitative difference between the mechanisms underlying cognitive and motor imitation |
Linear Configurational Learning We know that monkeys are great at learning lists. How they mentally represent those lists is unclear. Previous tasks show distance effects for 2-item subsets derived from one or more lists on which they were trained (D'Amato & Colombo, 1988; Terrace, Son & Brannon, 2003). The general result was that accuracy of responding increased and reaction time decreased as the ordinal distance between the test items increased. Such distance effects suggest that list items were represented spatially along a linear continuum. To investigate this hypothesis, we used monkeys (Macaca mulatta) with experience on the simultaneous chaining paradigm. On the original simultanous chaining paradigm, subjects received primary reinforcement if and only if they had responded, in a particular order, to an array of 4 photographs that were displayed simultaneously on a touch-sensitive video monitor. To insure that subjects couldn’t learn the required sequence as a motor plan, the position of the list items varied randomly from trial to trial. In the current paradigm we used the same procedure with a few modifications. A simultaneous chain was displayed in one of four different configurations: linear (vertical [top to bottom] and horizontal [left to right] where the spatial position matches the list order), probe linear (horizontal or vertical but spatial position does not match order position), and simchain (random spatial position). If subjects represented list items spatially, they might be able to use the hint provided on those trials on which the required sequence could be executed by following a spatial rule. Our results to date show that, on 4-item lists, monkeys benefited from trials on which they could respond to the list in a linear manner. Positive transfer from linear trials to trials on which the spatial location of list items varied randomly support the hypothesis that subjects do indeed organize list items along a spatial continuum. This is the first step in a series of experiments targeted towards determining if presentation of a list with matching spatial and order positioning will increase the rate of acquisition and retention of a serial list. |
|
Do animals remember who cooperated with them and who competed with them in the past? Anecdotal evidence suggests that his is so. However, any attempt at experimentally determining whether they have this capability has failed to draw conclusive results. This study will enable rhesus macaques to demonstrate this ability in a naturalistic but highly controlled social situation. It is naturalistic in that two macaques will be involved in the social interaction, unlike other studies that have utilized human experimenters as part of the dyad. Experimental control is maintained by minimizing the number of possible responses and having one subject directly influence the outcome of the other. By determining the reward contingency of each trial for of the other monkey, each subject has the opportunity to choose to compete or cooperate with the other. |
Shared Mechanisms of Ordinal Judgment Do monkeys represent all ordinal lists in the same way? In this experiment we investigate whether knowledge acquired using different methods of training can be readily transferred to a different ordinal task. Monkeys are trained on the transitive inference task where they infer the order of a list of pictures through trial and error through the presentation of adjacent pairs. Once they acquire the lists we present all of the pictures from a list simultaneously. For half the lists we will reinforce the same order the monkeys learned during training (the congruent condition), but for the other half we will reinforce a different order (the incongruent condition). We expect that the monkeys will benefit by transitive inference training in the congruent condition because we believe there is an underlying mechanism of ordinal representation shared by both experimental paradigms (simultaneous and pair-wise presentation of stimuli). |
Conditional Spatial Discrimination
The spatial conditioning task investigates whether rhesus macaques can transfer a spatial representation to a sequential representation. Monkeys will be presented with arrays of stimuli (AAAA, BBBB, CCCC, DDDD) in which each stimulus has a predetermined ordinal value. This stimulus presentation is purely spatial, with the position of the target being the only cue regarding the overall sequence order. After training monkeys to respond to the correct spatial position for each stimulus, subjects will be presented with a list containing each stimulus. Of primary interest is whether monkeys can transfer learned spatial positional information to ordinal positional information in the context of list learning. |
|
The serial probe recognition task is used to examine the characteristics of lists in working memory. Of primary interest is whether results show a Serial Position Effect (SPE), which is characterized by primacy (better memory for items at the beginning of the list) and recency (better memory for items at the end of the list) effects, and comparatively poorer memory for items in the middle of the list. In monkey subjects, memory strength can be measured by both accuracy and reaction time.
During a serial probe recognition trial, the monkey sees a series of sample stimuli (arbitrary pictures), presented successively. Following a delay, the monkey is shown a probe and two icons, a “yes” icon, and a “no” icon. The probe is either one of the sample stimuli just shown, or a novel stimulus. If the stimulus is one of the previously presented stimuli, the monkey should respond by touching the “yes” icon; if it is a novel stimulus, the monkey should respond by touching the “no” icon. Correct responses are followed by a banana-flavored food pellet, a change in the color of the monitor, and a distinct sound. Incorrect responses are followed by a different distinct sound and a time out during which the screen is dark. Our monkeys have worked up to long sample lists and significant delays between sample list presentation and the probe. Results thus far do not indicate a traditional SPE. Accuracy for early list items is poor, accuracy for later list items is good, and accuracy for intermediate list items is intermediate. Thus, in terms of accuracy, monkeys show an effect of recency, but no effect of primacy. For a video clip of Coltrane doing SPR, go to Videos. |




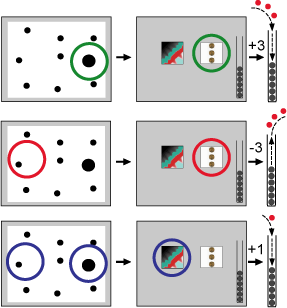
 We concluded that the monkeys were effectively able to monitor their memory, as their risk-accuracy correlation was positive (and became stronger with each transfer to a new task). This correlation is a measure of how often they chose high risk following a correct response, and low risk following an incorrect one.
We concluded that the monkeys were effectively able to monitor their memory, as their risk-accuracy correlation was positive (and became stronger with each transfer to a new task). This correlation is a measure of how often they chose high risk following a correct response, and low risk following an incorrect one.