Consortium for Electric Reliability Technology Solutions
Grid of the Future
White Paper on
Review of Recent Reliability Issues and System Events
Prepared for the
Transmission Reliability Program
Office of Power Technologies
Assistant Secretary for Energy Efficiency and Renewable Energy
U.S. Department of Energy
Prepared by
John F. Hauer
Jeff E. Dagle
Pacific Northwest National Laboratory
December 9, 1999
The work described in this report was funded by the Assistant Secretary of Energy Efficiency and Renewable Energy, Office of Power Technologies of the U.S. Department of Energy under Contract No. DE-AC03-76SF00098.
Consortium for Electric Reliability Technology Solutions
Grid of the Future
White Paper on
Review of Recent Reliability Issues and System Events
Executive Summary *
1. Introduction *
2. Preliminary Remarks *
3. Overview of Major Electrical Outages in North America *
3.1 Northeast Blackout: November 9-10, 1965 [18] *
3.2 New York City Blackout: July 13-14, 1977 [19] *
3.3 Recent Western Systems Coordinating Council (WSCC) Events *
3.3.1 WSCC Breakup (earthquake): January 17, 1994 [] *
3.3.2 WSCC Breakup: December 14, 1994 [21] *
3.3.3 WSCC Breakup: July 2, 1996 [,,] *
3.3.4 WSCC "Near Miss:" July 3, 1996 [30,13] *
3.3.5 WSCC Breakup: August 10, 1996 [9,,12,13] *
3.4 Minnesota-Wisconsin Separation and "Near Miss:" June 11-12, 1997 [,] *
3.5 MAPP Breakup: June 25, 1998 [,] *
3.6 NPCC Ice Storm: January 5-10, 1998 [] *
3.7 San Francisco Tripoff: December 8, 1998 [] *
3.8 "Price Spikes" in the Market *
3.9 The Hot Summer of 1999 *
4. The Aftermath of Major Disturbances *
5. Recurring Factors in North American Outages *
5.1 Protective Controls — Relays *
5.2 Protective Controls — Relay Coordination *
5.3 Unexpected Circumstances *
5.4 Circumstances Unknown to System Operators *
5.5 Understanding Power System Phenomena *
5.6 Challenges in Feedback Control *
5.7 Maintenance Problems, RCM, and Intelligent Diagnosticians *
5.8 "Operator Error" *
6. Special Lessons From Recent Outages — August 10, 1996 *
6.1 Western System Oscillation Dynamics *
6.2 Warning Signs of Pending Instability *
6.3 Stability Control Issues *
6.4 The Issue of Model Validity *
6.5 System Planning Issues *
6.6 Institutional Issues — the WSCC *
6.7 Institutional Issues — the Federal Utilities and WAMS *
7. Focus Areas for DOE Action *
8. Summary of Findings and Implications *
Executive Summary
The objective of this White Paper is to review, analyze, and evaluate critical reliability issues as demonstrated by recent disturbance events in the North America power system. The system events are assessed for both their technological and their institutional implications. Policy issues are noted in passing, in so much as policy and policy changes define the most important forces that shape power system reliability on this continent.
Eleven major disturbances are examined. Most of them occurred in this decade. Two earlier ones — in 1965 and 1977 — are included as early indictors of technical problems that persist to the present day. The issues derived from the examined events are, for the most part, stated as problems and functional needs. Translating these from the functional level into explicit recommendations for Federally supported RD&D is reserved for CERTS White Papers that draw upon the present one.
The strategic challenge is that the pattern of technical need has persisted for so long. Anticipation of market deregulation has, for more than a decade, been a major disincentive to new investments in system capacity. It has also inspired reduced maintenance of existing assets. A massive infusion of better technology is emerging as the final option for continued reliability of electrical services. If that technology investment will not be made in a timely manner, then that fact should be recognized and North America should plan its adjustments to a very different level of electrical service.
It is apparent that technical operations staff among the utilities can be very effective at marshaling their forces in the immediate aftermath of a system emergency, and that serious disturbances often lead to improved mechanisms for coordinated operation. It is not at all apparent that such efforts can be sustained through voluntary reliability organizations in which utility personnel external to those organizations do most of the technical work. The eastern interconnection shows several situations in which much of the technical support has migrated from the utilities to the Independent System Operator (ISO), and the ISO staffs or shares staff with the regional reliability council. This may be a natural and very positive consequence of utility restructuring. If so, the fact should be recognized and the process should be expedited in regions where the process is less advanced.
The August 10, 1996 breakup of the Western interconnection demonstrates the problem. It is clear that better technology might have avoided this disturbance, or at least minimized its impact. The final message is a broader one. All of the technical problems that the Western Systems Coordinating Council (WSCC) identified after the August 10 Breakup had been progressively reported to it in earlier years, along with an expanded version of the countermeasures eventually adopted. Through a protracted decline in planning resources among the member utilities, the WSCC had lost its collective memory of these problems and much of the critical competency needed to resolve them. The market forces that caused this pervade all of North America. Similar effects should be expected in other regions as well, though the symptoms will vary.
Hopefully, such institutional weaknesses are a transitional phenomenon that will be remedied as new organizational structures for grid operations evolve, and as regional reliability organizations acquire the authority and staffing consistent with their expanding missions. This will provide a more stable base and rationale for infrastructure investments. Difficult issues still remain in accommodating risk and in reliability management generally. Technology can provide better tools, but it is National policy that will determine if and how such tools are employed. That policy should consider the deterrent effect that new liability issues pose for the pathfinding uses of new technology or new methods in a commercially driven market.
The progressive decline of reliability assets that preceded many of these reliability events, most notably the 1996 breakups of the Western system, did not pass unnoticed by the Federal utilities and by other Federal organizations involved in reliability assurance. Under an earlier Program, the DOE responded to this need through the Wide Area Measurement System (WAMS) technology demonstration project. This was of great value for understanding the breakups and restoring full system operations. The continuing WAMS effort provides useful insights into possible roles for the U.S. Department of Energy (DOE) and for the Federal utilities in reliability assurance.
To be fully effective in such matters the DOE should probably seek closer "partnering" with operating elements of the electricity industry. This can be approached through greater involvement of the Federal utilities in National Laboratory activities, and through direct involvement of the National Laboratories in support of all utilities or other industry elements that perform advanced grid operations. The following activities are proposed as candidates for this broader DOE involvement:
- National Institute for Energy Assurance (NIEA) to safeguard, integrate, focus, and refine critical competencies in the area of energy system reliability. The NIEA will be organized as a distributed "virtual organization" based upon the Department of Energy and its National Laboratories, the Federal Utilities, and energy industry groups such as the Electric Power Research Institute and the Gas Research Institute. The NIEA will provide coordination with universities and other industry organizations, and provide collaborative linkages with other professional organizations and the vendor community. The NIEA will expedite sharing and transfer of technology, knowledge, and skills developed within the Federal system. Electric utilities, grid operators, and reliability organizations such as NERC/NAERO will be supported by the NIEA as needed, and through the formation of Emergency Response Teams during unusual system emergencies.
- Dynamic Information Network (DInet) for reliable planning and operation. An advanced demonstration project building upon the earlier DOE/EPRI Wide Area Measurement System effort, plus Federal technologies for data mining, visualization, and advanced computing. Core technologies also include centralized phasor measurements, mathematical system theory, advanced signal analysis, and secure distributed information processing. The DInet itself will provide a testbed for new technology, plus information support to wide area control projects and the evolving Interregional Security Network. Focus issues for this program include direct examination and assessment of power system dynamic performance, systematic validation and refinement of computer models, and sharing of WAMS technologies developed for these purposes.
- Modeling the Public Good in Reliability Management. Exploratory research into means for representing National interests as objectives and/or constraints in the emerging generation of decision support tools for reliability management. Examples of National interests include an effective power grid for the deregulated U.S. power markets and a secure, resilient grid to protect the national interests in an increasingly digital economy. The key technical product will be a global framework for reliability management that incorporates a full range of technical, social and economic issues. Elements within this framework include determining and quantifying the full impact of reliability failures, probabilistic indicators for risk, treatment of mandates and subjective preferences toward options, mathematical modeling, and decision algorithms. To test and evaluate the principles involved, this research may include joint demonstration projects with EPRI or other developers of probabilistic tools.
- Recovery Systems for Disturbance Mitigation, to lessen the impact of system disturbances and to lessen the dependence upon preventive measures. Dynamic restoration controls, based upon real time phasor information, would reduce the violence of the event itself and steer the system toward automatic reclosure of open transmission elements. This might include temporary separation of the system into islands that are linked by HVDC or FACTS devices. If needed, operators would continue the process and restore customer services on a prioritized basis. Comprehensive information systems (advanced WAMS) would expedite the engineering analysis and repair processes needed to fully restore power system facilities.
All of these activities would take place at the highest strategic level, and in areas that commercial market activities are unlikely to address.
- Introduction
This White Paper is one of six developed under the U.S. Department of Energy (DOE) Program in Power System Integration and Reliability (PSIR). The work is being performed by or in coordination with the Consortium for Electrical Reliability Technology Solutions (CERTS), under the Grid of the Future Task.
The objective of this particular White Paper is to review, analyze, and evaluate critical reliability issues as demonstrated by recent disturbance events in the North America power system. The lead institution for this White Paper is the DOE’s Pacific Northwest National Laboratory (PNNL). The work is performed in the context of reports issued by the U.S. Secretary of Energy Advisory Board (SEAB) [,], and it builds upon earlier findings drawn from the DOE Wide Area Measurement Systems Project [,,]. Related information can also be found in the Final Report of the Electric Power Research Institute (EPRI) WAMS Information Manager Project [].
The system events are assessed for both their technological and their institutional implications. Some of the more recent events reflect new market forces. Consequently, they may also reflect upon the changing policy balance between reliability assurance and open market competition. This balance is considered here from a historical perspective, and only to the extend necessary for event assessment.
The White Paper also makes brief mention of a different kind of reliability event that was very conspicuous across eastern North America during the summer of 1999. These represented shortages in energy resources, rather than main-grid disturbances. Even so, they reflect many of the same underlying reliability issues. These are being examined under a separate activity, conducted by a Post-Outage Study Team (POST) established by DOE Energy Secretary Richardson [].
Primary contributions of this White Paper include the following:
- Summary descriptions of the system events, with bibliographies
- Recurring factors in these events, presented as technical needs
- Results showing how better information technology would have warned system operators of impending oscillations on August 10, 1996
- The progression by which market forces eroded WSCC capability to anticipate and avoid the August 10 breakup
- The progression by which market forces eroded the ability of the Bonneville Power Administration (BPA), and other Federal utilities, to sustain their roles as providers of reliability services and technology
- "Lessons learned" during critical infrastructure reinforcement by the DOE WAMS Project.
Various materials are also provided as background, or for possible use in related documents within the Project. The issues derived from the examined events are, for the most part, stated as problems and functional needs. Translating these from the functional level into explicit recommendations for Federally supported RD&D is reserved for a subsequent CERTS effort.
- Preliminary Remarks
Some comments are in order as to the approach followed in this White Paper. The authors are well aware of the risk that too much — or too little — might be inferred from what may seem to be just anecdotal evidence. It is important to consider not only what happened, but also why it happened and the degree to which effective countermeasures have since been established. New measurement systems, developed and deployed expressly for such purposes, recorded the WSCC breakups of 1996 in unusual detail [,,]. The information thus acquired provided a basis for engineering reviews that were more detailed and more comprehensive than are usually possible [,,,,,]. In addition to this, the lead author was deeply involved in an earlier and very substantial BPA/WSCC efforts to clarify and reduce the important planning uncertainties that later contributed to the 1996 breakups [,,]. The total information base for assessing these events is extensive, though important gaps remain. Some of the finer details, concerning matters such as control system behavior and the response of system loads, are not certain and they may never be fully resolved.
There are also some caveats to observe in translating WSCC experience to other regions. The salient technical problems on any large power system are often unique to just that system. The factors that determine this include geography, weather, network topology, generation and load characteristics, age of equipment, staff resources, maintenance practices, and many others. The western power system is "loosely connected," with a nearly longitudinal "backbone" for north-south power exchanges. Many of the generation centers there are very large, and quite remote from the loads they serve. In strong contrast to this, most of eastern North America is served by a "tightly meshed" power system in which transmission distances are far shorter. Differences in the problems that engineers face on these systems differ more in degree than in kind, however. Oscillation problems that plague the west are becoming visible in the east, and the voltage collapse problem has migrated westward since the great blackouts of 1965 and 1977 [,,]. Problems on any one system can very well point to future problems on other systems.
It is also important to assess large and dramatic reliability events within the overall context of observed system behavior. The WSCC breakup on July 2 followed almost exactly the same path as a breakup some 18 months earlier []. Some of the secondary problems from July 2 carried over to the even bigger breakup on August 10, and were important contributors to the cascading outage. The August 10 event was much more complex in its details and underlying causes, however. It was in large part a result of planning models that overstated the safety factor in high power exports from Canada, compounded by deficiencies in generator control and protection [,]. Symptoms of these problems were provided by many smaller disturbances over the previous decade, and by staged tests that BPA and WSCC technical groups had performed to correct the modeling situation [,].
In the end event, the WSCC breakups of 1996 were the consequence of known problems that had persisted for too long []. One reason for this was the fading of collective WSCC memory through staff attrition among the member utilities. A deeper reason was that "market signals" had triggered a race to cut costs, with reduced attention to overall system reliability. Technical support to the WSCC mission underwent a protracted decline among the utilities, with a consequent weakening of staffing and leadership. Many needed investments in reliability technologies were deferred to future grid operators.
The pattern of disturbances and other power system emergencies argues that the same underlying forces are at work across all of North America. At first inspection and at the lowest scale of detail, the ubiquitous relay might seem the villain in just about all of the major disturbances since 1965 []. Looking deeper, one may find that particular relays are obsolescent or imperfectly maintained, that relay settings and "intelligence" do not match the present range of operating conditions, and that coordinating wide area relay systems is an imperfect art. Ways to remedy these problems can be developed [,], but rationalization of that development must also make either a market case or a regulatory case for deployment of the product by the electricity industry.
At the highest scale of detail, system emergencies in which generated power is not adequate to serve customer load seem to have become increasingly common. Allegations have been made that some of these scarcities have been created or manipulated to produce "price spikes" in the spot market for electricity. Whether this can or does happen is important to know but difficult to establish. Even here better technology may provide at least partial remedies. There is an obvious role for better assets management tools, such as Flexible AC Transmission System (FACTS) technologies, to relieve congestion in the energy delivery system (to the extent that such a problem does indeed exist as a separable factor []). More abstractly, systems for "data mining" may be able to recognize market manipulations and operations research methodology might help to develop markets that are insensitive to such manipulations. This is a zone in which the search for solutions crosses from technology into policy.
Somehow, the electricity industry itself must be able to rationalize continued investments in raw generation and in all the technologies that are needed to reliably deliver quality power to the consumer [,]. Some analysts assert that reliability is a natural consequence and a salable commodity at the "end state" of the deregulatory process. While this could prove true, eventually, the transition to that end state may be protracted and uncertain. It may well be that the only mechanism to assure reliability during the transition itself is that provided by the various levels of government acting in the public interest.
A final caveat is that utility engineers are rather more resourceful than outside observers might realize. It can be very difficult to track or assist utility progress toward some technical need without being directly involved. So, before too many conclusions are drawn from this White Paper, CERTS should develop a contemporary estimate as to just how much has already been done — and how well it fits into the broader picture. It might be useful to circulate selected portions of the White Papers for comment among industry experts who are closely familiar with the subject matter.
Relevance and focus of the CERTS effort will, over the longer term, require sustained dialog with operating utilities. As field arms of the DOE, and through their involvement in reliability assurance, the Power Marketing Agencies are good candidates for this. It is highly desirable that the dialog not be restricted to just a few such entities, however.
- Overview of Major Electrical Outages in North America
This Section provides summary descriptions for the following electrical outages in North America:
- Northeast Blackout: November 9-10, 1965
- New York City Blackout: July 13-14, 1977
- WSCC Breakup (earthquake): January 17, 1994
- WSCC Breakup: December 14, 1994
- WSCC Events in Summer 1996
- July 2, 1996 — cascading outage
- July 3, 1996 — cascading outage avoided
- August 10, 1996 — cascading outage
- Minnesota-Wisconsin Separation: June 11-12, 1997
- MAPP Breakup: June 25, 1998
- NPCC Ice Storm: January 5-10, 1998
- San Francisco Tripoff: December 8, 1998
Each of these disturbances contains valuable information about the management and assurance of power system reliability. More detailed descriptions can be found by working back through the indicated references. In many cases these will also describe system restoration, which can be more complex and provide more insight into needed improvements than the disturbance itself. Together, it is not unusual for a disturbance plus restoration to involve several hundred system operations. Some of these may not be accurately recorded, and a few may not be recorded at all.
- Northeast Blackout: November 9-10, 1965 []
This event began with sequentially tripping of five 230 kV lines transporting power from the Beck plant (on the Niagara River) to the Toronto, Ontario load area. The tripping was caused by backup relays that, unknown to the system operators, were set at thresholds below the unusually high but still safe line loadings of recent months. These loadings reflected higher than normal imports of power from the United States into Canada, to cover emergency outages of the nearby Lakeview plant. Separation from the Toronto load produced a "back surge" of power into the New York transmission system, causing transient instabilities and tripping of equipment throughout the northeast electrical system. This event directly affected some 30 million people across an area of 80,000 square miles. That it began during a peak of commuter traffic (5:16 p.m. on a Tuesday) made it especially disruptive.
This major event was a primary impetus for foundation of the North American Electric Reliability Council (NERC) and, somewhat later, of the Electric Power Research Institute (EPRI).
- New York City Blackout: July 13-14, 1977 []
A lightning stroke initiated a line trip which, through a complex sequence of events, lead to total voltage collapse and blackout of the Consolidated Edison system some 59 minutes later (9:36 p.m.). The 9 million inhabitants of New York City were to be without electrical power for some 25 hours. Impact of this blackout was greatly exacerbated by widespread looting, arson, and violence. Disruption of public transportation and communications was massive, and the legal resources were overwhelmed by the rioting. Estimated financial cost of this event is in excess of 350 million dollars, to which many social costs must be added.
Several aspects of this event were exceptional for that time. One of these was the very slow progression of the voltage collapse. Another was the considerable damage to equipment during re-energization. This is one of the "benchmark" events from which the electricity industry has drawn many lessons useful to the progressive interconnection of large power systems.
- Recent Western Systems Coordinating Council (WSCC) Events
For reasons stated earlier, special attention is given to the WSCC breakups in the summer of 1996. This is part of a series (shown in Table I) that has received a great deal of attention from the public, the electricity industry, and various levels of government. In part this is because the events themselves were very conspicuous. The August 10 Breakup affected some 7.5 million people across a large portion of North America, and is estimated to have cost the economy at least 2 billion dollars. There is also a great deal of dramatic impact to news images of the San Francisco skyline in a night without lights.

Table I. Topical outages in the western power system, 1994-1998
The more severe of the WSCC breakups were true "cascading outages," in which events at many different locations contributed to final failure. The map shown in Fig. 1 shows the more important locations mentioned in the descriptions to follow.
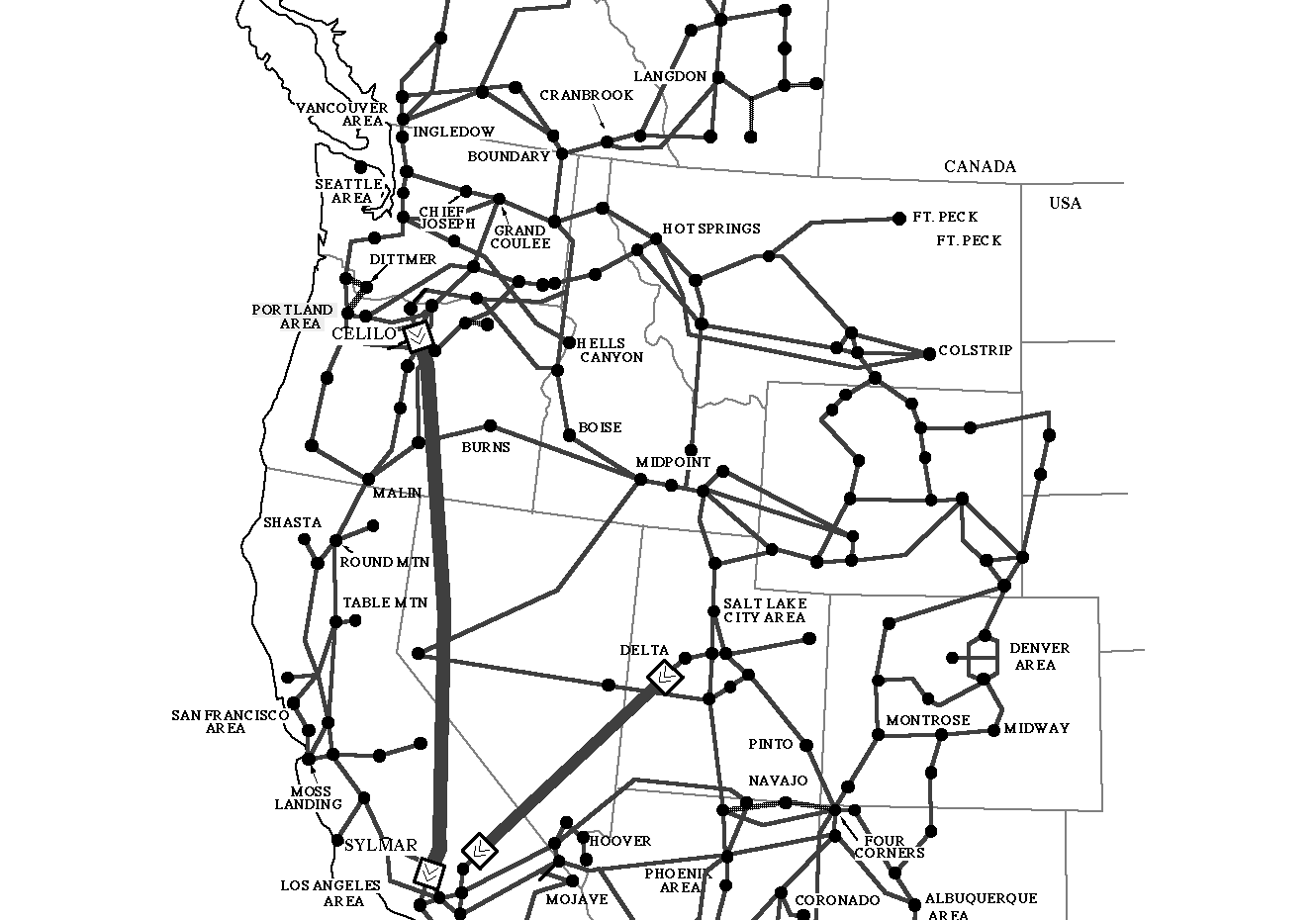
Fig. 1. General structure of the western North America power system.
- WSCC Breakup (earthquake): January 17, 1994 []
At 04:31 a.m. a magnitude 6.6 earthquake occurred in the vicinity of Los Angeles, CA. Damage to nearby electrical equipment was extensive, and some relays tripped through mechanical vibrations. Massive loss of transmission resources triggered a rapid breakup of the entire western system. Disruption in the Pacific Northwest was considerably reduced through first-time operation of underfrequency load shedding controls [], which operated through 2 of their 7 levels. There was considerable surprise among the general public, and in some National policy circles, that an earthquake in southern California would immediately impact electrical services so far away as Seattle and western Canada.
- WSCC Breakup: December 14, 1994 []
The Pacific Northwest was in a winter import condition, bringing about 2500 MW from California and about 3100 MW from Idaho plus Montana. Import from Canada into the BPA service area totaled about 1100 MW. At 01:25 a.m. local time, insulator contamination near Borah (in SE Idaho) faulted one circuit on a 345 kV line importing power from the Jim Bridger plant (in SW Wyoming). The circuit tripped properly, but another relay erroneously tripped a parallel circuit; bus geometry at Borah the forced a trip of the direct 345 kV line from Jim Bridger. Sustained voltage depression and overloads tripped other nearby lines at 9, 41, and 52 seconds after the original fault. The outage then cascaded throughout the western system, thorough transient instability and protective actions. The western power system fragmented into 4 islands a few seconds later.
Extreme swings in voltage and frequency produced widespread generator tripping. Responding to these swings, various controls associated with the Intermountain Power Project (IPP) HVDC line, from Utah to Los Angeles, cycled its power from 1678 to 2050 to 1630 to 2900 to 0 MW. This considerably aggravated an already complex problem. Slow frequency recovery in some islands indicated that governor response was not adequate. Notably, the Pacific Northwest load shedding controls operated through 6 of their 7 levels.
- WSCC Breakup: July 2, 1996 [,,]
Hot weather had produced heavy loads throughout the west. Abundant water supplies powered fairly heavy imports of energy from Canada (about 1850 MW) and through the BPA service area into California. Despite the high stream flow, environmental mandates forced BPA to curtail generation on the lower Columbia River as an aid to fish migration. This reduced both voltage support and "flywheel" support for transient disturbances, in an area where both the Pacific AC Intertie (PACI) and the Pacific HVDC Intertie (PDCI) originate. This threatened the ability of those lines to sustain heavy exports to California, and — with the northward shift of the generation center — it increased system exposure to north-south oscillations (Canada vs. Southern California and Arizona). The power flow also involved unusual exports from the Pacific Northwest into southern Idaho and Utah, with Idaho voltage support reduced by a maintenance outage of the 250 MVA Brownlee #5 generator near Boise.
At 02:24 p.m. local time, arcing to a tree tripped a 345 kV line from the Jim Bridger plant (in SW Wyoming) into SE Idaho. Relay error also tripped a parallel 345 kV line, initiating trip of two 500 MW generators by stability controls. Inadequate reserves of reactive power produced sustained voltage depression in southern Idaho, accompanied by oscillations throughout the Pacific Northwest and northern California. About 24 seconds after the fault, the outage cascaded through tripping of small generators near Boise plus tripping of the 230 kV "Amps line" from western Montana to SE Idaho. Then voltage collapsed rapidly in southern Idaho and — helped by false trips of 3 units at McNary — at the north end of the PACI. Within a few seconds the western power system was fragmented into five islands, with most of southern Idaho blacked out.
On the following day, the President of the United States directed the Secretary of Energy to provide a report that would commence with technical matters but work to a conclusion that "Assesses the adequacy of existing North American electric reliability systems and makes recommendations for any operational or regulatory changes." The Report was delivered on August 2, just eight days before the even greater breakup of August 10 1996. The July 2 Report provides a very useful summary framework for the many analyses and reports that have followed since.
- WSCC "Near Miss:" July 3, 1996 [,]
Conditions on July3 were generally similar to those of July 2, but with somewhat less stress on the network. BPA’s AC transfer limits to California had been curtailed (to 4000 MW instead of 4800 MW), and resumed operation of the Brownlee #5 generator improved Idaho voltage support. The arc of July 2 recurred — apparently to the same tree — and the same faulty relay lead to the same protective actions at the Jim Bridger plant. Plant operators added to the ensuing voltage decline by reducing reactive output from the Brownlee #5 generator. System operators, however, successfully arrested the decline by dropping 600 MW of customer load in the Boise area. The troublesome tree was removed on July 5.
- WSCC Breakup: August 10, 1996 [, ,,]
Temperatures and loads were somewhat higher than on July 2. Northwest water supplies were still abundant — unusual for August — and the import from Canada had increased to about 2300 MW. The July 2 environmental constraints on lower Columbia River generation were still in effect, reducing voltage and inertial support at the north ends of the PACI and PDCI. Over the course of several hours, arcs to trees progressively tripped a number of 500 kV lines near Portland, and further weakened voltage support in the lower Columbia River area. This weakening was compounded by a maintenance outage of the transformer that connects a static VAR compensator in Portland to the main 500 kV grid.
The critical line trip occurred at 13:42 p.m., with loss of a 500 kV line (Keeler-Allston) carrying power from the Seattle area to Portland. Much of that power then detoured from Seattle to Hanford (in eastern Washington) and then to the Portland area, twice crossing the Cascade Mountains. The electrical distance from the Canada generation to Southwest load was then even longer than just before the July 2 breakup, and the north-south transmission corridor was stretched to the edge of oscillatory instability. Near Hanford, the McNary plant became critical for countering a regional voltage depression but was hard pressed to do so. Three smaller plants near McNary might have assisted but were not controlled for this. Strong hints of incipient oscillations spread throughout the northern half of the power system.
Final blows came at 15:47:36. The heavily loaded Ross-Lexington 230 kV line (near Portland) was lost through yet another tree fault. At 15:47:37, the defective relays that erroneously tripped McNary generators on July 2 struck again. This time the relays progressively tripped all 13 of the units operating there. Governors and the automatic generation control (AGC) system attempted to make up this lost power by increasing generation north of the cross-Cascades detour. Growing oscillations — perhaps aggravated by controls on the PDCI [] — produced voltage swings that severed the PACI at 15:48:52. The outage quickly cascaded through the western system, fracturing it into four islands and interrupting services to some 7.5 million customers.
One unusual aspect of this event was that the Northeast-Southeast Separation Scheme, for controlled islanding under emergency conditions, had been removed from service. As a result the islanding that did occur was delayed, random, and probably more violent than would have otherwise been the case. Other unusual aspects include the massive loss of internal generation within areas that were importing power (e.g., were already generation deficient) and the damage to equipment. Some large thermal and nuclear plants remained out of service for several days.
- Minnesota-Wisconsin Separation and "Near Miss:" June 11-12, 1997 [,]
This event started with heavy flows of power from western MAPP and Manitoba Hydro eastward into MAIN and southward into SPP (see Fig. 2). Partly a commercial transport of lower cost power, the eastward flow was also needed to offset generation shortages in MAIN.
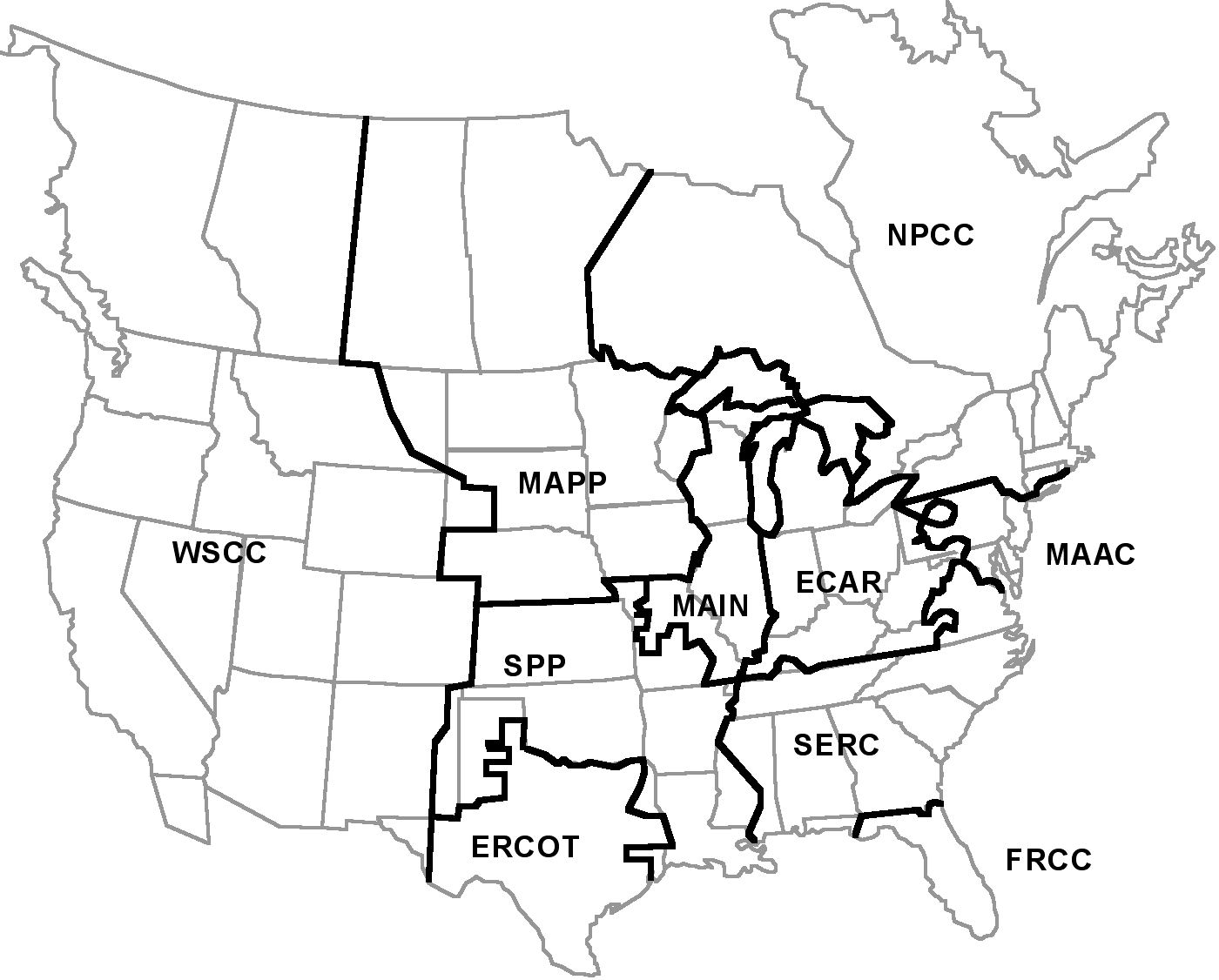
Fig. 2. Geography and Regional Reliability Councils for the North America power system (courtesy of B. Buehring, Argonne National Laboratory)
The event started shortly after midnight, when the 345 kV King-Eau Claire-Arpin-Rocky Run-North Appleton line from Minneapolis — St. Paul into Wisconsin opened at Rocky Run. Apparently this was caused by a relay that acted below its current setting, due to unbalanced loads or to a dc offset. This led to a protracted loss of the Eau Claire — Arpin 345 kV line, which could not be reclosed because of the large phase angle across the open breaker at Arpin. This produced a voltage depression across SW Wisconsin, eastern Iowa, and NE Illinois plus heavily loading of the remaining grid. Regional operators maneuvered their generation to relieve the situation and, some two hours later, the line was successfully reclosed. Later analysis indicates that the MAPP system "came within a few megawatts of a system separation," which might well have blacked out a considerable area []
- MAPP Breakup: June 25, 1998 [,]
This event started under conditions that were similar to those for June 11, 1997. Power flows from western MAPP and Manitoba Hydro into MAIN and SPP were heavy but within established limits. There was also a severe thunderstorm in progress, moving eastward across the Minneapolis—St. Paul area.
The initiating event occurred at 01:34 a.m., when a lightning stroke opened the 345 kV Prairie Island — Byron line from Minneapolis—St. Paul into Iowa and St. Louis. Immediate attempts to reclose this line failed due to excessive phase angle. As for the June 11 event, the operators then undertook to reduce the line angle by maneuvering generation. Another major event occurred before the line was restored, however. At 02:18 a.m., the storm produced a lightning stroke that opened the heavily loaded King-Eau Claire 345 kV line toward Wisconsin and Chicago. A cascading outage then rippled through the MAPP system, separating all of the northern MAPP system from the eastern interconnection and progressively breaking it into three islands. The records show both out-of-step oscillations between asynchronous regions of the system, and other oscillations that may not be explained as yet. Apparently there were also some problems with supplemental damping controls on the two HVDC lines from N. Dakota into Minnesota. The separated area spanned large portions of Montana, North Dakota, South Dakota, Minnesota, Wisconsin, Manitoba, Saskatchewan, and northwest Ontario.
The length of time between these two "contingencies" — some 44 minutes — is important. NERC operating criteria state that recovery from the first contingency should have taken place within 30 minutes (either through reduced line loadings or by reclosing the open line). MAPP criteria in effect at the time (and since replaced by those of NERC) allowed only 10 minutes. Criteria are not resources, though, and the operators simply lacked the tools that the situation required. Apparently they had brought the line angle within one or two degrees of the (hardwired) 40° closure limit, and a manual override of this limit would have been fully warranted. There were no provisions for doing this, however, so they were forced to work through a Line Loading Relief (LLR) procedure that had not yet matured enough to serve to the needs of the day. Other sources indicate that major improvements have been make since.
Though modeling results are not presented, the Report for this breakup is otherwise very comprehensive and exceptionally informative. As a measure for the complexity of this breakup, the Report states that "WAPA indicated that their SCADA system recorded approximately 10,000 events, alarms, status changes, and telemetered limit excursions during the disturbance." The Report then mentions some loss of communications and of SCADA information, apparently through data overload.
The Report also states that "The Minnesota Power dynamic system monitors which have accurate frequency transducers and GPS time synchronization were invaluable in analyzing this disturbance and identifying the correct sequence of events in many instances," even though recording was piecemeal and overall monitor coverage for the system was quite sparse. These insights closely parallel those derived from WSCC disturbances.
- NPCC Ice Storm: January 5-10, 1998 []
During this period a series of exceptionally severe ice storms struck large areas within New York, New England, Ontario, Quebec, and the Maritimes. Freezing rains deposited ice ranging in thickness to 3 inches, and were the worst ever recorded in that region. Resulting damage to transmission and distribution was characterized as severe (more than 770 towers collapsed).
This event underscores some challenging questions as to how, and how expensively, physical structures should be reinforced against rare meteorological conditions. It also raises some difficult questions as to how utilities should plan for and deal with multiple contingencies that are causally linked (not statistically independent random events).
The main lessons, though, deal with system restoration. Emergency preparedness, cooperative arrangements among utilities and with civil authorities, integrated access to detailed outage information, and an innovative approach to field repairs were all found to be particularly valuable. The disturbance report mentions that information from remotely accessible microprocessor based fault locator relays was instrumental in quickly identifying and locating problems. Implied in the report is that the restoration strategy amounted to a "stochastic game" in which some risks were taken in order to make maximum service improvements in least time — and with imperfect information on system capability.
- San Francisco Tripoff: December 8, 1998 []
Initial reports indicate that this event occurred when a maintenance crew at the San Mateo substation re-energized a 115 kV bus section with the protective grounds still in place. Unfortunately, the local substation operator had not yet engaged the associated differential relaying that would have isolated and cleared just the affected section. Other relays then tripped all five lines to the bus, triggering the loss of at least twelve substations and all power plants in the service area (402 MW vs. a total load of 775 MW). Restoration was hampered by blackstart problems, and by poor coordination with the California ISO.
Geography contributed to this event. Since San Francisco occupies a densely developed peninsula, the present energy corridors into it are limited and it would be difficult to add new ones. It is very nearly a radial load, and thereby quite vulnerable to failures at the few points where it connects to the main grid. The situation is well known, and many planning engineers have hoped for at least one more transmission line or cable into the San Francisco load area.
- "Price Spikes" in the Market
The new markets in electricity have experienced occasionally severe "price spikes" as a result of scarcity or congestion. The reliability implications of this are not clear. Some schools of thought hold that such prices provide a needed incentive to investment, and represent "the market at its best." Others suspect that, in some cases at least, the scarcity or congestion have been deliberately produced in order to drive prices up. In either event, the price spikes themselves may well be indicators for marginal reliability. These matters will be examined more closely in other elements of the CERTS effort.
- The Hot Summer of 1999
Analogous to the winter ice storms of 1998, protracted "heat storms" struck much of eastern North America during the summer of 1999 [,,]. Several of these were unusual in respect to their timing, temperature, humidity, duration, and geographical extent. Past records for electrical load were broken, and broken again. Voltage reductions and interruption of managed loads were useful but not sufficient in dealing with the high demand for electrical services. News releases reported heat related deaths in Chicago, outages in New York City, and rolling blackouts in many regions.
Unlike the other reliability events already considered here, these particular incidents did not involve significant disturbances to the main transmission grid. One of most conspicuous factors was heat-induced failure of aging distribution facilities, especially in the highly urbanized sections of Chicago [] and New York City []. Sustained hot weather also caused many generators to perform less well than expected, and it lead to sporadic generator outages through a variety of indirect mechanisms.
The most conspicuous problem was a very fundamental one. For many different reasons, a number of regions were confronted — simultaneously — by a shortfall in energy resources. Operators in some systems saw strong but unexpected indications of voltage collapse. The general weakening of the transmission grid hampered long distance energy transfers from areas where extra generation capacity did exist, and it severely tested the still new emergency powers of the central grid operators. These events have raised some very pointed questions as to what constitutes adequate electrical resources, and whether the new market structures can assure them. These matters are now being addressed by the DOE, NERC, EPRI, and various organizations. DOE Energy Secretary Richardson has established a Post-Outage Study Team (POST) for this purpose [].
The 1999 heat storm events also point toward various technical problems:
- Forecasting. Historical experience and short-term weather forecasts underestimated both the severity of the hot weather and the degree to which it would increase system loads.
- Planning practices.
- The widespread weather problems, compounded by complexities of the new market, produced patterns of operation that system planners had not been able to fully assess in advance.
- Market pricing encourages increased reliance upon very remote generation. Energy production and transport are now vulnerable to new contingencies far outside the service area.
- Planning models displayed several weaknesses:
- The proximity of system voltage collapse seems to have been rather greater than models indicated. Simplified representation of air conditioning loads is believed to be a factor in this.
- Generator capabilities and performance were less than models indicated. This is especially noticeable for gas fired combustion turbines, which also seem to self-protect more readily than models indicate.
- The overall impact of hot weather on forced outage rates seems to have been underestimated.
- In real time, some operators lacked resources that would have let them anticipate and/or manage the emergencies better. Newer technologies for monitoring of cable systems would have been very helpful [].
- Better recordings for operational data would have facilitated after-the-fact improvements in system planning, and to the system itself.
- Maintenance scheduling. Several of these events occurred while key generation was undergoing scheduled maintenance between seasonal load peaks, or during a forced extension of such maintenance.
- Maintenance practices raise difficult issues in risk management. The maintenance process itself can pose a threat to the system, both by removing facilities from service and by sometimes damaging those facilities. Some newer types of high power distribution cables seem especially vulnerable to this.
Counterparts to these technical problems have already been seen in the main-grid reliability events of earlier Sections, for systems further west. They have also been seen in earlier reliability events in the same areas. Many technical aspects of the June 1999 heat storm [] experienced by the Northeast Power Coordinating Council (NPCC) are remarkably similar to those of the cold weather emergency there in January 1994 [].
The 1999 heat storm events offer many contrasting performance examples for grid operation systems and regional markets during emergency conditions. Performance of the NPCC and its member control areas during the generation shortage of June 7-8 seems notably good. Had this not been so, the emergency could have been devastating to highly populated regions of the U.S. and Canada. That this did not happen is due to exemplary coordination among NPCC and the member control areas, within the framework of a relatively young market that is still adapting to new rules and expectations. The information from this experience should be valuable to regions of North America where deregulation and restructuring are less advanced.
- The Aftermath of Major Disturbances
The aftermath of a major disturbance can be a period of considerable trial to the utilities involved. Their response to it can be a major challenge to their technical assets, and to the reliability council through which they coordinate the work. The quality of that response may also be the primary determinant for immediate and longer-term costs of the disturbance.
Most immediately, there is the matter of system restoration (electrical services and system facilities). This will almost certainly involve an engineering review, both to understand the event and to identify countermeasures. Such countermeasures may well involve revised procedures for planning and operation, selective de-rating of critical equipment, and installation of new equipment. The engineering review may also factor into high level policies concerning the balance between the cost and the reliability of electrical services.
If restoration proceeds smoothly and promptly then the immediate costs of the disturbance will be comparatively modest. These costs may rise sharply as an outage becomes more protracted, however. There is an increased chance that abnormally loaded equipment must either sustain damage or protect itself by tripping off. (This is the classic mechanism by which a small outage cascades into a large one.) Some remaining generation may just deplete their reserves of fuel or stored energy. Also, loads that have already lost power differ in their tolerance for outage duration. Spoilage of refrigerated food, freezing of molten metals, and progressive congestion of transportation systems are well known examples of this.
In most cases electrical services are restored within minutes to a few hours at most. Full restoration of system facilities to their original capability may require repairs to equipment that was damaged during the outage itself, or during services restoration. The 1994 earthquake and the New York City blackout of 1977 demonstrate how extensive these types of damage may be. Long-term costs of an outage accumulate during the repair period, and the repairs themselves may be much less expensive than those of new operating constraints for the weakened system.
Full repairs do not necessarily lead to full operation. New and more conservative limits may be imposed in light of the engineering review, or as a consequence of new policies. To an increasing extent, curtailed operation may also result from litigation or the fear of it [,,]. This consideration is antithetical to the candid exchange of technical information that is necessary to the engineering review process, and to an effective reliability council based upon voluntary cooperation among its members.
- Recurring Factors in North American Outages
The outages described in this Section span a period of more than thirty years. Even so, certain contributing factors recur throughout these summary descriptions and the more detailed descriptions that underlie them. There are ubiquitous problems with
- Protective controls (relays and relay coordination)
- Unexpected or unknown circumstances
- Understanding and awareness of power system phenomena (esp. voltage collapse)
- Feedback controls (PSS, HVDC, AGC)
- Maintenance
- "Operator error"
The more important technical elements that these problems reflect are discussed below, and in later Sections. Human error is not listed, simply because — at some remove — it underlies all of the problems shown.
Disturbance reports and engineering reviews frequently state that some particular system or device "performed as designed" — even when that design was clearly inappropriate to the circumstances. Somewhere, prior to this narrowly defined design process, there was an error that led to the wrong design requirements. It may have been in technical analysis, in the general objectives, or in resources allocation — but it was a human error, and embedded in the planning process [,].
- Protective Controls — Relays
Disturbance reports commonly cite relay misoperation as the initiator or propagator of a system disturbance. Sometimes this is traced to nothing more than neglected maintenance, obsolescent technology, or an inappropriate class of relay. More often, though, the offending relay has been "instructed" improperly, with settings and "intelligence" that do not match the present range of operating conditions. There have been many problems with relays that "overreach" in their extrapolation of local measurements to distant locations.
Proper tools and appropriate policies for relay maintenance are important issues. More important, though, is the "mission objective" for those relays that are critical to system integrity. Most relays are intended to protect local equipment. This is consistent with the immediate interests of the equipment owner, and with the rather good rationale that intact equipment can resume service much earlier than damaged equipment.
But, arguing against this, there have been numerous instances where overly cautious local protection has contributed to a cascading outage. Deferred tripping of critical facilities may join the list of ancillary services for which the facilities owner must be compensated [].
- Protective Controls — Relay Coordination
Containing a sizeable disturbance will usually require appropriate action by several relays. There are several ways to seek the needed coordination among these relays. The usual approach is to simulate the "worst case" disturbances and then set the relays accordingly. Communication among the relays is indirect, through the power system itself. The quality of the coordination is determined by that of the simulation models, and by the foresight of the planners who use them.
In the next level of sophistication of relay coordination, some relays transmit "transfer trip" signals to other relays when they recognize a "target." Such signals can be used to either initiate or block actions by the relays that receive them. Embellished with supervisory controls and other "intelligence," the resulting network can be evolved into a wide area control system of a sort used very successfully in the western power system and throughout the world.
Direct communication among relays makes their coordination more reliable — in a hardware sense — but correctness of the design itself must still be addressed. Apparently there are difficulties with this, both a-priori and in retrospect. Relays, like transducers and feedback controllers, are signal processing devices that have their own dynamics and their own modes of failure. Some relays sense conditions (like phase imbalance or boiler pressure) that power system planners cannot readily model. Overall, the engineering tools for coordinating wide area relay systems seem rather sparse.
Beyond all this, it is also apparent that large power systems are sometimes operated in ways that were not foreseen when relay settings were established. It is not at all apparent that fixed relay settings can properly accommodate the increasingly busy market or, worse yet, the sort of islanding that has been seen recently in North America. It may well be that relay based controls, like feedback controls, will need some form of parameter scheduling to cope with such variability. The necessary communications could prove highly attractive to information attack, however, and precautions against this growing threat would be mandatory [,].
Several of the events suggest that there are still some questions to be resolved in the basic strategy of bus protective systems, or perhaps in their economics. In the breakup of December 14, 1994, it appears that "bus geometry" forced an otherwise unnecessary line trip at Borah and lead directly to the subsequent breakup. In the San Francisco tripoff of December 8, 1998, a bus fault there tripped all lines to the San Mateo bus because the differential relay system had not been fully restored to service. An "expert system" might have advised the operator of this condition, and perhaps even performed an impedance check on the equipment to be energized.
- Unexpected Circumstances
Nearly two decades ago, at a panel session on power system operation, it was stated that major disturbances on the eastern North America system generally occurred with something like six major facilities already out of service (usually for maintenance). The speaker then raised the question "What utility ever studies N-6 operation of the system?"
This pattern is very apparent in the events described above, and in many other disturbances of lesser impact. WSCC response, in the wake of the August 10 breakup, is an announced policy that "The system should only be operated under conditions that have been directly studied." Implicit in the dictum is that the studies should use methods and models known to be correct. Too often, that correctness is just take for granted.
One result of this policy is that many more studies must be performed and evaluated. To some extent, study results will affect maintenance scheduling and possibly delay it. Dealing with unscheduled outages, of the sort that occur incessantly in a large system, is made more difficult just by the high number of combinations that must be anticipated. The best approach may be to narrow the range of combinations by shortening the planning horizon. This would necessarily call for powerful simulation tools, with access to projected system conditions and with special "intelligence" to assist in security assessment.
In the limit, such tools for security assessment would draw near-real-time information from both measurements and models taken from system itself. They might also provide input to higher level tools, for reliability management, that advise the future grid operator in his continual balancing of system reliability against system performance.
- Circumstances Unknown to System Operators
There are many instances where system operators might have averted some major disturbance if they had been more aware of system conditions. An early case of this can be found in the 1965 Northeast Blackout, when operators unknowingly operated above the unnecessarily conservative thresholds of key relays. More recently, just prior to the August 10 breakup, it is possible that some utilities would have reshaped their generation and/or transmission had they known that so many lines were out of service in the Portland area. The emerging Interregional Security Network, plus various new arrangements for exchange of network loading data, are improving this aspect of the information environment.
Operator knowledge of system conditions may be of even greater value during restoration. The alacrity and smoothness of system restoration are prime determinators of disturbance cost, and the operators are of course racing to brace the system against whatever contingency may follow next. Restoration efforts following the 1998 NPCC Ice Storm and the 1997-1998 MAPP events seem typical of recent experience. The need for integrated information and "intelligent" restoration aids is apparent, and the status of relevant technology should be determined. Analogous problems exist for load management during emergencies at distribution level [].
In the past, it has commonly happened that critical system information was available to some operators but not to those who most needed it. Inter-utility sharing of SCADA data, together with inclusion of more data and data types within SCADA, have considerably improved this aspect of the problem. The new bottleneck is "data overload" — information that is deeply buried in the data set is still not available to the operators, or to technical staff.
Alarm processing has received considerable attention over the years, but continual improvements will be needed (note the 10,000 SCADA events recorded by WAPA for the 1998 MAPP breakup). Alarm generation itself is an important topic. The August 10 Breakup demonstrates the need for tools that dig more deeply into system data, searching out warning signs of pending trouble. (The potential for this is shown in a later Section.) Such tools are also needed in the security assessment and reliability management processes.
Information shortfalls can also be a serious and expensive handicap to the engineering review that follows a major disturbance. Much of this review draws upon operating records collected from many types of device (not just SCADA). At present the integration of such records is done as a manual effort that is both ad hoc and very laborious. Data is contributed voluntarily by many utilities, in many dissimilar formats. For cascading outages like those in 1996, the chance that essential data will be lost from the recording system — or lost in the recording system — are quite substantial. The following examples are instructive in this respect:
- Loss of the "Amps line," from western Montana into southeastern Idaho, was a decisive event in the WSCC breakup of July 2, 1996. The engineering team reviewing the event did not discover that this line had been lost until some 20 days after the breakup, however. In the meanwhile, lead-time and critical engineering resources were expended in a struggle with the wrong problem.
- Loss of generation was a decisive causative factor in the August 10 breakup. The list of generators actually lost was still incomplete three months later.
- The best analyses to date indicate that the performance of feedback controls in the Pacific Southwest was another decisive factor in the August 10 breakup. Surviving records of this performance are fragmented at best, and it is rumored that many of the records taken were overstored or otherwise lost.
Countermeasures to such problems are discussed further in [,,]. Chief among these are a system-wide information manager that assures reliable data retention and access, and an associative data miner for extracting pertinent information from the various data bases. It is assumed that these would include text files (operator logs and technical reports) as well as numerical data.
- Understanding Power System Phenomena
There is a tendency to underestimate the complexity of behavior that a large power system can exhibit. As a system increases in size, or is interconnected with other systems nearby, it may acquire unexpected or pathological characteristics not found in smaller systems []. These characteristics may be intermittent, and they may be further complicated by subtle interactions among control systems or other devices [,,]. This is an area of continuing research, both at the theoretical level and in the direct assessment of observed system behavior.
Some phenomena are poorly understood even when the underlying physics is simple. Slow voltage collapse is an insidious example of this [,,,] and there are numerous accounts of perplexed operators struggling in vain to rescue a system that was slowly working its way toward catastrophic failure. The successful actions taken on July 3 show that the need for prompt load dropping has been recognized, and recent WSCC breakups demonstrate the value of automatic load shedding thorough relay action. Even so, on August 10 the BPA operators were not sufficiently aware that their reactive reserves had been depleted, they had few tools to assess those reserves, and load shedding controls were not in wide use outside the BPA service area.
Large scale oscillations can be another source of puzzlement, to operators and planners alike. Observations observed in the field may originate from nonlinear phenomena, such as frequency differences between asynchronous islands or interactions with saturated devices []. It is very unlikely that any pre-existing model will replicate such oscillations, and it is quite possible that operating records will not even identify the conditions or the equipment that produced them. Situations of this kind can readily escalate from operational problems into serious research projects.
Similar problems arise even for the apparently straightforward linear oscillations between groups of electrical generators. WSCC planning models have been chronically unrealistic in their representation of oscillatory dynamics, and have progressively biased the engineering judgement that underlies the planning process and the allocation of operational resources. Somewhere, along the way to the August 10 breakup, the caveats associated with high imports from Canada were forgotten. One partial result of this is that both planners and operators there have been using just computer models, and time-domain tools, to address what is fundamentally a frequency domain problem requiring information from the power system itself. Better tools — and better practices — would provide better insight.
Disabling of the north-south separation scheme suggests a lack of appreciation for the value of controlled islanding in a loosely connected power system.. Once they are in progress, the final line of defense against widespread oscillations is to cut one or more key interaction paths, and this is what controlled islanding would have done. Without this, on August 10 the western system tore itself apart along random boundaries, rather than achieving a clean break into predetermined and self sufficient islands. Future versions of the separation scheme should be closely integrated into primary control centers, where the information necessary for more advanced islanding logic is more readily available. Islanded operation should also be given more attention in system planning, and in the overall design of stability controls.
- Challenges in Feedback Control
There are two types of stability control in a large power system. One of these uses "event driven" feedforward logic to seek a rough balance between generation and load, and the other refines that balance through "response driven" feedback logic. Fig. 3 indicates this relationship and the quantities involved.
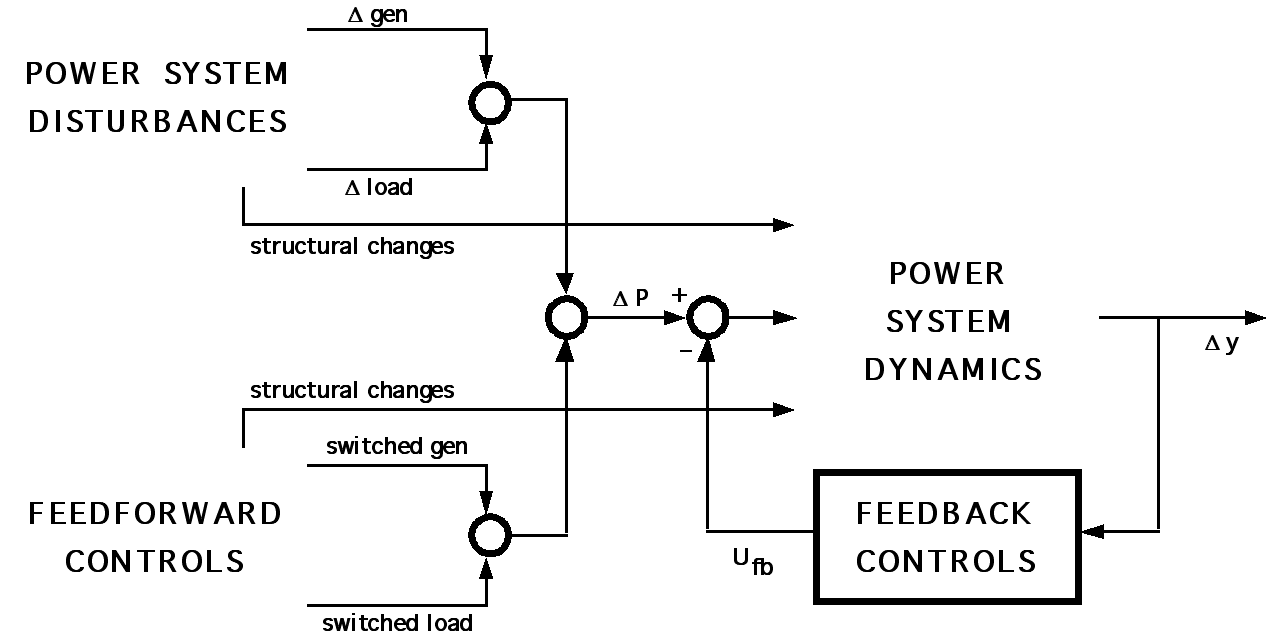
Fig. 3. General structure of power system disturbance controls
The feedforward controls are generally rule based, following some discrete action when some particular condition or event is recognized. Typical control actions include coordinated tripping of multiple lines or generators, controlled islanding, and fast power changes on a HVDC line. Due to the prevalence of relay logic and breaker actuation, these are often regarded as special protective controls. Another widely used term is remedial action scheme, or RAS.
RAS control is usually armed, and is sometimes initiated, from some central location. Though this is not always the case, most RAS actuators are circuit breakers. Since this is a two-state device, the underlying hardware can draw upon relay technology, with communication links that are both simple and very reliable.
Feedback controls usually modulate some continuously adjustable quantity such as prime mover power, generator output voltage, or current through a power electronics device. Signals to and from the primary control logic are too complex for reliable long distance communication with established technologies. Newer technologies that may change this are gaining a foothold. At present, however, the established practice is to design and operate feedback controls on the basis of local signals only. As in the case of relays (Section 5.2), communication among such controllers is indirect and through the power system itself.
Some of the disturbance events demonstrate that this does not always provide adequate information. Particularly dramatic evidence of this was provided by vigorous cycling of the IPP HVDC line during the WSCC breakup of December 14, 1994. Less dramatic problems with coordination of HVDC controls might also be found in the August 10 Breakup and in the MAPP breakup of June 25, 1998.
The lesson in this is that wide area controls need wide area information. Topology information, or remote signals based upon topology, are the most reliable way to modify or suspend controller operation during really large disturbances (e.g., with islanding). Such information would also allow parameter scheduling for widely changing system conditions. Other kinds of supplemental information should be brought to the controller site for use in certification tests, or to detect adverse interactions between the controller and other equipment []. The information requirements of wide area control are generally underestimated, at considerable risk to the power system.
Though their cumulative effects are global to the entire power system, most feedback controls there are local to some generator or specific facility. Design of such controls has received much attention, and the related literature spans at least three decades. Despite this, the best technology for generator control is fairly recent and not widely used. Observations of gross system performance imply that, whatever the reason, stability support at the generator level has been declining over the years. EPRI’s 1992 report concerning slow frequency recovery [] is reinforced by the WSCC experience reported in [] and []. In the WSCC, ambient "swing" activity of the Canada-California mode has been conspicuous for decades and has progressively become more so. This strongly suggests that WSCC tuning procedures for power system stabilizer (PSS) units may not address this mode properly. Modeling studies commonly show that — under specific known circumstances — the stability contribution of some machines can be considerably improved. There are a lot of practical issues along the path from such findings to an operational reality, however.
Much or most of the observed decline in stability support by generator controls is attributed to operational practices rather than technical problems. It can be profitable to operate a plant very close to full capacity, with no controllable reserve to deal with system emergencies. Even when such reserves are retained it can still be profitable, or at least convenient, to obtain "smooth running" by changing or suspending some of the automatic controls. In past years the WSCC dealt with this through unannounced on-site inspections []. Engineering review of 1996 breakups argue that this was not sufficient. There must be some direct means by which the grid operator can verify that essential controller resources are actually available (and performing properly). Prior to this, it is essential that the providing of such resources be acceptable and attractive to the generation owners. Unobtrusive technology and proper financial compensation are major elements in this.
The emerging challenge is to make controller services as reliable as any other commercial product []. If this cannot be done then new loads must be served through new construction, or with less reliability.
- Maintenance Problems, RCM, and Intelligent Diagnosticians
Many of the outages suggest weaknesses in some aspect of system maintenance. Inadequate vegetation control along major transmission lines is an conspicuous example, made notorious by the 1996 breakups. There have also been occasional reports of things like corroded relays, and there are persistent indications that testing of relays in the field is neither as frequent nor as thorough as it should be. Apparently the relays that prematurely tripped McNary generation on August 10, 1996, had been scheduled for maintenance or replacement for some 18 months.
The utilities have expressed significant interest in new tools such as reliability centered maintenance (RCM) and its various relatives. A risk in this is that "maintenance just in time" can easily become "maintenance just too late." Some power engineers have expressed the view that preventive maintenance of any kind is becoming rare in some regions, and that the situation will not improve very much until utility restructuring is more nearly compete. There is not much incentive to perform expensive maintenance on an asset that may soon belong to someone else. Other engineers contest this assertion, or claim that such situations are not typical. The clear fact is that maintenance is a difficult but critical issue in corporate strategy.
The need for automated "diagnosticians" at the device level has been recognized for some years, and useful progress has been reported with the various technologies that are involved. These range from sensing of insulation defects in transformers through to generator condition monitors and self-checking logic in the "intelligent electronic devices" that are becoming ubiquitous at substation level. In the direct RCM framework we find browsers that examine operating and service records for indications that maintenance should be scheduled for some particular device or facility. Tracking such technologies is becoming difficult. The technologies themselves tend to be proprietary, and the associated investment decisions are business sensitive.
The need for automatic diagnosticians at system level is recognized, though not usually in these terms. Conceptualization of and progress toward such a product has been rather compartmentalized, with different institutions specializing in different areas. Real-time security assessment is perhaps the primary component for a diagnostician at this level. EPRI development of model based tools for this has shown considerable technical success (summarized in []), and the DOE/EPRI WAMS effort points the way toward complementary tools that are based upon real time measurements [-,,]. The latter effort has also shown the value of intelligent browser that would expedite full restoration of system services after a major system emergency. It seems likely that these various efforts will be drawn together under a Federal program in Critical Infrastructure Protection (CIP).
- "Operator Error"
This is a term that should be reserved for cases in which field personnel (who might not actually be system operators) do not act in accordance with established procedures. Such cases do indeed occur, with distressing frequency, and the effects can be very serious. The appropriate direct remedies for this are improved training, augmented by improved procedures with built-in cross checks that advise field personnel of errors before action is taken. Automatic tools for this can be useful, but — as shown by the balky reclosure system in the 1998 MAPP breakup — no robot should be given too much authority.
Deeper problems are at work when system operators take some inappropriate action as a result of poor information or erroneous instructions. (This may be an operational error for the utility, but it is not an operator’s error.) Sections 5.3 through 5.5 discuss aspects of this and point toward some useful technologies.
This technology set falls well short of a full solution. It will be a very long time before any set of simple recipes will anticipate all of the conditions that can arise in a large power system, especially if the underlying models are faulty. Proper operation is a responsibility shared between operations staff (who are not usually engineers) and technical staff (who usually are). Key operation centers should draw upon "collaborative technologies" to assure that technical staff support is available and efficiently used when needed, even though the supporting presonnel may be at various remote locations and normally working at other duties. Such resources would be of special importance to primary grid operators such as an ISO.
There is also a standing question as to how much discretionary authority should be given to system operators. Drawing upon direct experience, the operator is likely to have insights into system performance and capability that complement those of a system planner. In the past — prior to August 10 — the operators at some utilities were allowed substantial discretion to act upon that experience while dealing with small contingencies. Curtailing that discretion too much will remove a needed safety check on planning error.
- Special Lessons From Recent Outages — August 10, 1996
If we are fortunate, future students of such matters will see the WSCC Breakup of August 10 1996 as an interesting anomaly during the transition from a tightly regulated market in electricity to one that is regulated differently. The final hours and minutes leading to the breakup show a chain of unlikely events that would have been impossible to predict. Though not then recognized as such, these events were small "contingencies" that brought the system into a region of instability that WSCC planners had essentially forgotten. Indications of this condition were visible through much of the power system. Then, five minutes later, a final contingency struck and triggered one of the most massive breakups yet seen in North America.
Better information resources could have warned system operators of impending problems (Section 6.2), and better control resources might have avoided the final breakup or at least minimized its impact (Section 6.3). The finer details of these matters have not been fully resolved, and they many never be. The final message is a broader one.
All of the technical problems that the WSCC identified after the August 10 Breakup had already been reported to it in earlier years by technical work groups established for that purpose [,]. In accordance with their assigned missions, these work groups recommended to the WSCC general countermeasures that included and expanded upon those that were adopted after the August 10 Breakup. Development and deployment of information resources to better assess system performance was well underway prior to the breakup, but badly encumbered by shortages of funds and appropriate staff.
The protracted decline in planning resources that lead to the WSCC breakup of August 10, 1996 was and is a direct result of deregulatory forces. That decline has undercut the ability of that particular reliability council to fully perform its intended functions. Hopefully, such institutional weaknesses are a transitional phenomenon that will be remedied as a new generation of grid operators evolves and as the reliability organizations change to meet their expanding missions.
- Western System Oscillation Dynamics
Understanding the WSCC breakups of 1996 requires some detailed knowledge of the oscillatory dynamics present in that system, and of the way that those dynamics respond to control action. This Section provides a brief summary of such matters.
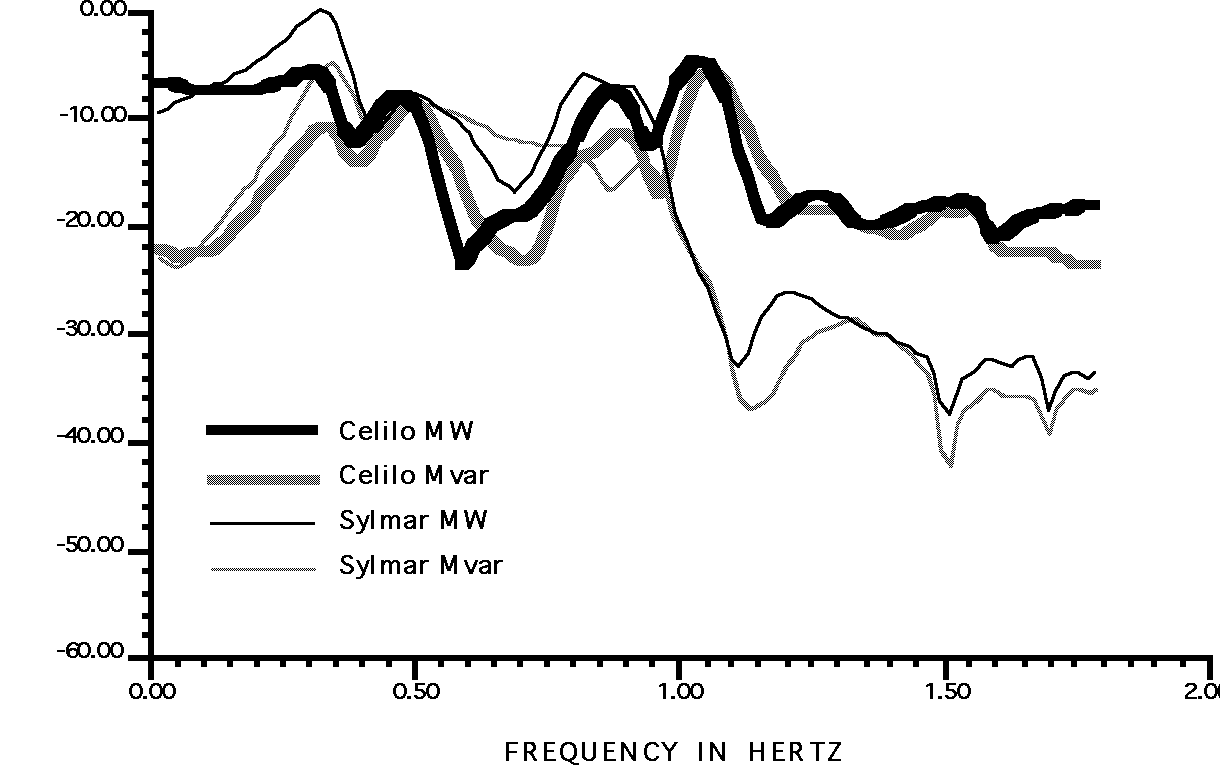
Fig. 4. Gain response of PACI line power to complex power injections at terminals of the PDCI
The more important interarea modes of the western power system are visible in Fig. 4. The data there show response of the Pacific AC Intertie to real and reactive power injections at the Celilo and the Sylmar terminals of the Pacific HVDC Intertie. These results were generated with a simulation model that had been calibrated against system disturbances of the early 1990’s, and seem realistic.
The figure supports the following observations:
- At 0.33 Hz: (the Canada — California, or "AC Intertie" mode)
- response to Sylmar MW is 6 dB (i.e., twice) stronger than that for any other injection. Changes in this would substantially affect response to PDCI real power modulation.
- response to Sylmar Mvar is strong, and can be expected to change substantially with Sylmar conditions.
- a reactive power device (such as an SVC) near Sylmar would have about the same "leverage" as a real power device (resistor brake or storage unit) near Celilo.
- At 0.45 Hz: (the Alberta mode)
- the response components are essentially the same for all injections.
- single-component modulation of an SVC, resistor brake, or storage unit would all be equally effective for damping of the associated mode, if located near Celilo or Sylmar.
- Near 0.7 Hz: (the 0.7 Hz mode cluster)
- there are indications of perhaps five modes between 0.75 Hz and 0.95 Hz.
- response to MW injections near Celilo approaches that for Mvar injections near Sylmar, but may address different modes (and different generator groups).
- Near 1.03 Hz: (the Grand Coulee mode)
- response to MW or Mvar injections near Celilo are essentially the same.
- there is no response to injections near Sylmar.
Just about any of these modes could become troublesome under the right circumstances. Interactions through HVDC controls are a leading candidate for this. Only two of these modes have actually been troublesome, however. One of these is the PACI mode, which in earlier times was a notorious source of unstable oscillations in the range of 0.32 Hz to about 0.36 Hz. There have also been destabilizing controller interactions with one or more modes near 0.7 Hz [,]. WSCC monitor coverage at that time was not sufficient to identify the particular mode involved. However, model studies point toward "the" 0.7 Hz mode that extends from northern California to Arizona, with linkages into Canada and other regions [,].
Starting somewhere near 1985, model studies gave strong warnings that, under stressed network conditions, this 0.7 Hz mode would produce severe oscillations for certain disturbances (especially loss of the PDCI). This perceived threat curtailed power transfers on the Arizona-California energy corridor, and it adversely impacted WSCC operation in a number of other ways as well. This enigmatic mode also inspired several damping control projects to mitigate it, and has produced a vast literature on the subject.
These same model studies also had a strong tendency to understate the threat of 0.33 Hz oscillations between Canada and California, on the PACI. So, on August 10, most WSCC engineers were looking in the wrong direction.
- Warning Signs of Pending Instability
The direct mechanism of failure on August 10 was a transient oscillation exacerbated by voltage instability. Maximum power imports from Canada were being carried on long transmission paths that, in former years, had been a proven source of troublesome oscillations. For most of that summer the paths had been weakened somewhat by curtailed generation on the lower Columbia River (called the "fish flush"). On August 10 the path was further weakened through a series of seemingly routine outages. Review of data collected on the BPA WAMS system argues that, buried within the measurements streaming into and stored at the control center, was the information that system behavior was abnormal and that the power system was unusually vulnerable. Prototype tools for recognizing such conditions had been developed under the WAMS effort but were not yet installed. Similar information was also entering local monitors at other utilities, but most of it was not retained there.
Operating records like Fig. 5 and Fig. 6 suggest that better tools might have provided system operators with about six minutes warning prior to the event that triggered the actual breakup. Had the warning been clear enough, and had sufficient operating resources been provided, this would have been more than ample time for reducing network stress through emergency transfer reductions. Short of this, special stability controls might have been invoked to reduce the immediate impact of the breakup. A useful final resort would have been to manually activate the Northwest-Southwest separation scheme once the nature of the final oscillations became apparent.

Fig. 5. Oscillation buildup for the WSCC breakup of August 10, 1996.
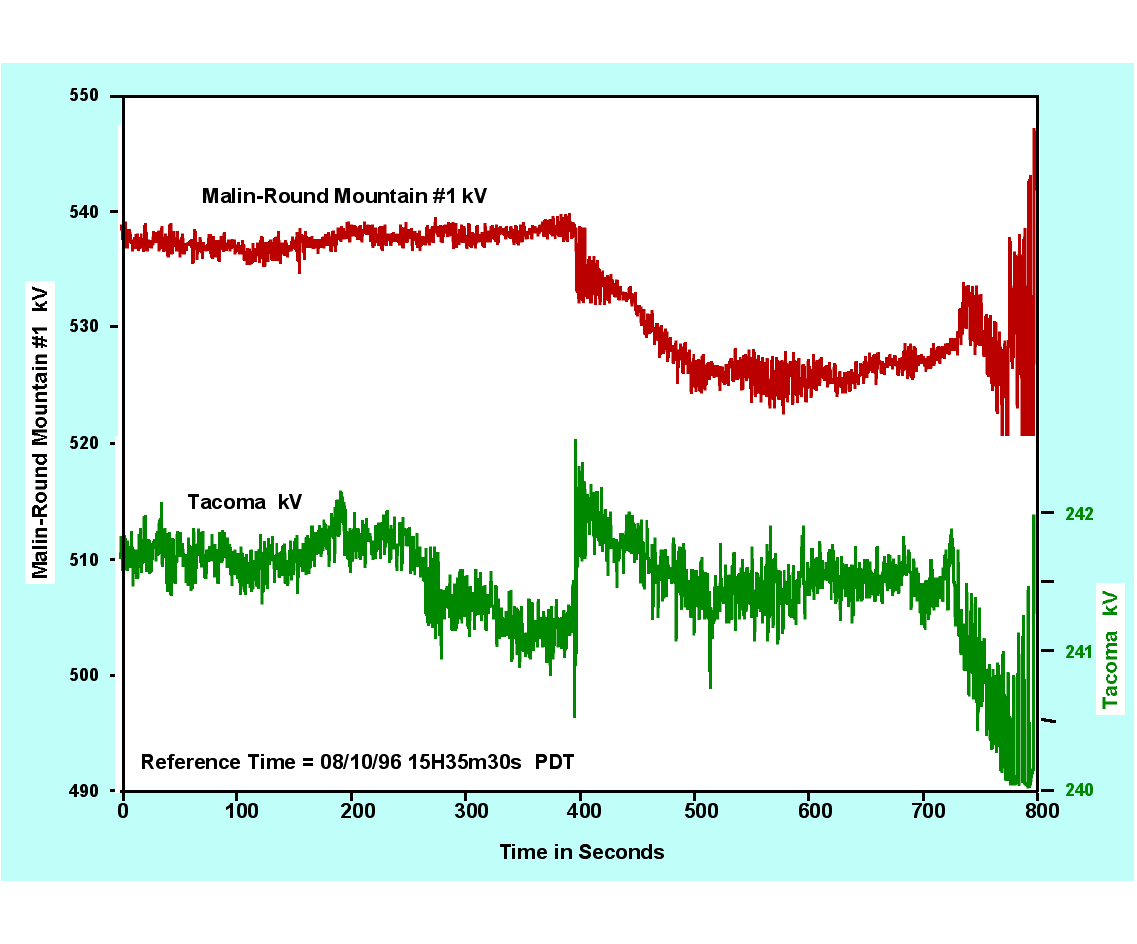
Fig. 6. Voltage changes for the WSCC breakup of August 10, 1996.
A problem, of course, was that such procedures were not then in place. Furthermore, the warning signs apparent to visual examination were not definite enough to justify such actions under the policies of the time. Stronger evidence can be found through modal analysis, however. Table II shows that frequency of the Canada-California mode was within the normal range at 10:52 AM, and that the damping was well above the 4.0% threshold that signals dangerous behavior in WSCC modes. The table also indicates that mode frequency and damping were both low just after the John Day-Marion line tripped, but that the frequency recovered to 0.276 Hz. This may have been a "near miss" with respect to system oscillations. Mode frequency and damping dropped to the same low values after the Keeler-Allston line tripped, and this time they did not recover (note ringing at 0.252 Hz). Unstable oscillations followed, and these severed the PACI transmission to California some 80 seconds later. Manual initiation of the North-South separation scheme about 30 seconds into the oscillations would have been very helpful — had that been possible.
PACI mode before August 10, 1996
Date/Event Frequency Damping
12/08/92 (Palo Verde trip) 0.28 Hz 7.5 %
03/14/93 (Palo Verde trip) 0.33 Hz 4.5 %
07/11/95 (brake insertion) 0.28 Hz 10.6 %
07/02/96 (system breakup) 0.22 Hz 1.2 %
PACI mode on August 10, 1996
Time/Event Frequency Damping
10:52:19 (brake insertion) 0.285 Hz 8.4%
14:52:37 (John Day-Marion) 0.264 Hz 3.7%
15:18 (ringing) 0.276 Hz
15:42:03 (Keeler-Allston) 0.264 Hz 3.5%
15:45 (ringing) 0.252 Hz
15:47:40 (oscillation start) 0.238 Hz -3.1%
15:48:50 (oscillation finish) 0.216 Hz -6.3%
Table II. Observed behavior of the PACI mode
While the results are less quantitative, even so straightforward a tool as Fourier analysis can be a useful indicator of changes in system behavior. Fig. 7 shows that tripping of the Keeler-Allston line produced strong changes the spectral "signature" for ambient activity on the Malin-Round Mountain circuits. This subject is pursued farther in the WAMS Reports [,] and in the associated working documents.
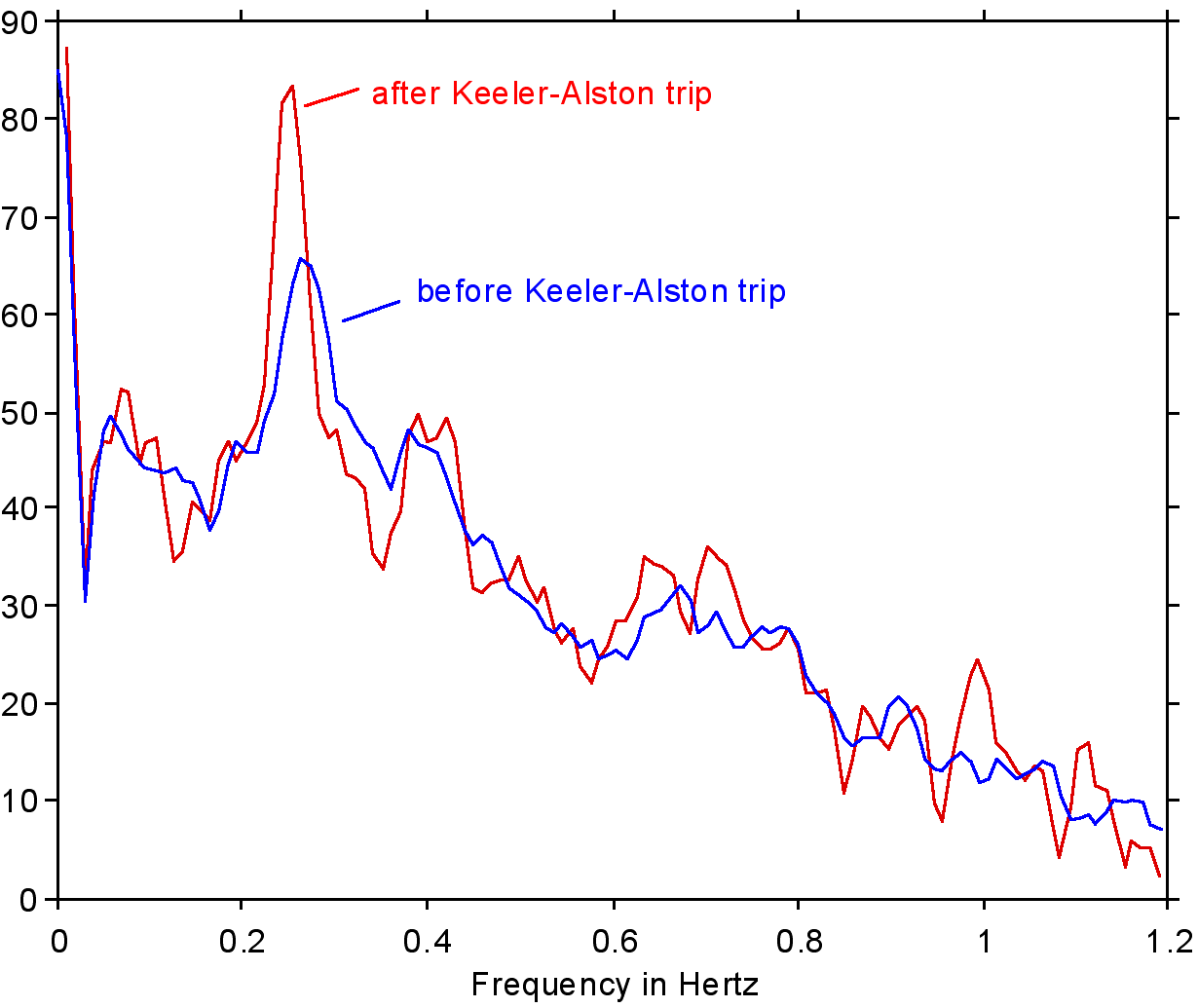
Fig. 7. Autospectra for Malin-Round Mountain line power
There are also indications that warnings were embedded in lower-speed powerflow data acquired on SCADA systems. For example, BPA operator accounts mention that voltage changed more that usual when reactive devices were switched. It is also reported that subsequent model studies have validated bus voltage angles as a reliable indicator of transfer limits. These angles are now measurable through the expanding WSCC phasor measurement network, so such a result would be very important.
- Stability Control Issues
The western power system employs many layers and kinds of stability control to deal with the contingencies that threaten it. As with any power system, local relaying provides the first layer of defense. The usual objective here is to protect some nearby device. Deeper layers of protection place progressively increasing emphasis upon protection of the overall system. Possible actions there range from locally controlled load shedding through to controlled separation of the system into self-sufficient islands [,]. Other discrete controls may bypass or insert network elements such as capacitors, reactors, or resistor brakes, and still others may trigger some preset action by a feedback control system. The August 10 Breakup clearly demonstrated the value of such remedial action systems. It also suggests that they should be used more widely, and that they should be better coordinated.
The implications for feedback controls are less clear, largely because their performance during the breakup was not recorded very well. The actions of discrete RAS controls are logged by an extensive system of digital event recorders, and controller effects are usually apparent in powerflow measurements at one or more control centers. In contrast to this, performance monitoring for feedback control is more data intensive and is usually done at the controller site. By 1996 very few utilities had installed competent equipment for this purpose.
WSCC engineers have sought to fill in this missing information indirectly, through model studies. A problem in this is that the models themselves are often faulty, or at least not validated. Unrealistic models are a major source of planning errors that lead to the breakup itself (Section 6.5 below). The available measurements are not comprehensive enough to fully resolve the many uncertainties in this situation.
This is particularly evident for the very powerful controls on the Pacific HVDC Intertie. Reference[] and the written Discussions that accompany it show at least two schools of thought concerning PDCI involvement in the August 10 oscillations. Arguing from their model plus small phase differences in measured ac/dc interaction signals, the BPA authors find that PDCI "mode switching" produced nonlinear oscillations which reduced system stability. After deriving a different model, discussors at Powertech Labs conclude that the August 10 oscillations were a linear phenomenon that was not affected very much by PDCI behavior.
The Powertech conclusion agrees with numerous model studies that are summarized in [- ]. Despite considerable search, the earlier WSCC effort found no case in which standard PDCI controls had a significant effect upon system damping for the class of disturbances usually studied. Such controls did affect the division of north-south power swings between the ac and the dc paths, and this interaction between the paths could be minimized by (hypothetical) controls that would fix PDCI voltage at the Sylmar converter. Such control would also decouple the PDCI from power swings on the nearby IPP line from Utah, and would make PDCI power less sensitive to moderate ac disturbances near Sylmar. None of these studies involved a disturbance exactly like the one on August 10, however, and the models were necessarily different.
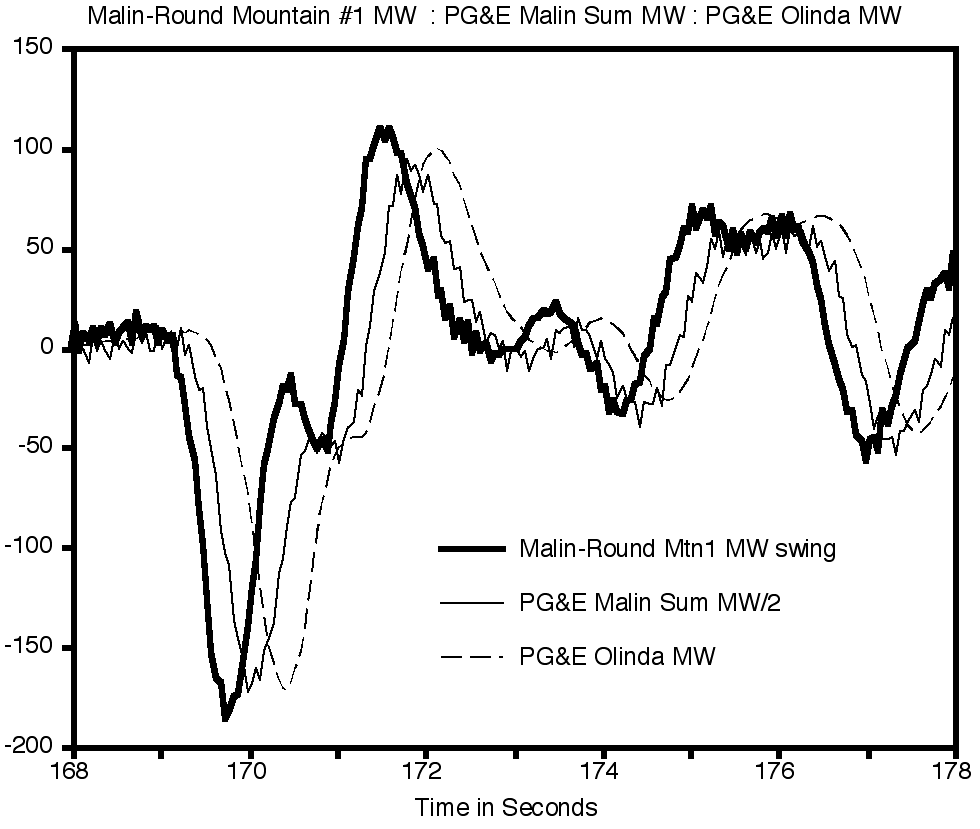
Fig. 8. Time response of Malin area transducers for insertion of Chief Joseph dynamic brake on August 10, 1996
The differences in signal phase that are used in the BPA analysis were recorded on an analog measurement system in which the delay from one channel to the next can be as much as 0.5 second (see Fig. 8). In the worst case, this would produce apparent phase differences close to those used in the analysis. Whether that analysis is supported by additional measurements has not been determined. PDCI involvement in the August 10 oscillations seems an open issue. To resolve it, all observational data should be reviewed, and the analysis should be adjusted for whatever measurement artifacts may be found. Future tests involving the PDCI may be helpful in this.
Due to a shortage of measurements, there is a similar uncertainty concerning performance of the large SVC units near Sylmar (at Adelanto and Marketplace). It is reported that both of these units tripped off sometime during the oscillations.
Using a model that is somewhat different from BPA’s, Powertech finds that the August 10 oscillations could have been avoided through simple readjustments to power system stabilizer (PSS) units on a small number of key generators in the Southwest and/or in Canada (see [] for details). The leverage that these machines have over the PACI mode is well known from system disturbances and from modal analyses. Whether it is practical to make these changes is a controversial issue of long standing, however, and one that may challenge WSCC practices in PSS tuning. This very important matter is far from resolved.
These analyses have highlighted the potential benefits of enhanced damping control, at levels that range from generator excitation control to HVDC and FACTS. Realizing this potentiality is no small challenge. Good summaries of recent progress in such matters are available in [,,].
- The Issue of Model Validity
Fig. 9 demonstrates that, prior to the August 10 breakup, standard WSCC planning models could be very unreliable predictors of oscillatory behavior. This is a difficult problem of long standing, and the utilities there had expended considerable effort in attempts to reduce it [,,]. Its potential for leading planners to poor decisions is readily apparent.
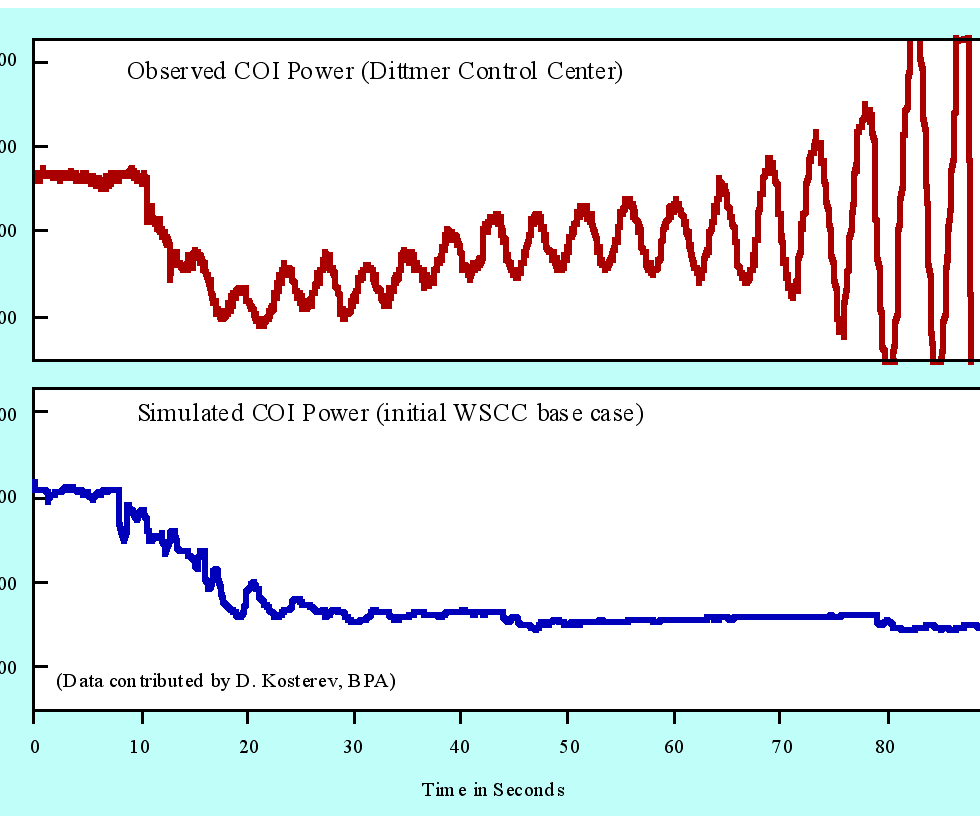
Fig. 9 Power swings on total California-Oregon Interconnection (COI) for WSCC breakup of August 10, 1996. Standard WSCC model vs. WAMS monitor data
Many factors are known to influence the oscillation damping in power system models. Load modeling has been a perennial source of difficulty in this regard. Poor load modeling can also affect model realism in other ways, and in other time frames.
The usual practice in transient stability studies is to represent loads as static, accompanied by some algebraic law that approximates their sensitivity to changes in applied voltage (and sometimes frequency). This representation does not capture the inertial effects of motor loads. Even when the damping is correct, this can produce errors in mode frequencies and in the transient behavior of system frequency. In [] this was partly compensated by absorbing motor load inertia into the inertia of local generators. It was also recognized that this would not fully capture the dynamic effects of such loads, and mention is made of a WSCC effort to model them explicitly. Reference [] indicates that this is now being done. When accompanied by other changes described there, this produces a model response that is outwardly quite similar to that recorded on WAMS monitors for the August 10 breakup.
The Powertech discussors to this paper show that a similar match can be achieved with static loads and a different set of model adjustments. This lack of uniqueness in calibrating planning models against measured data has been encountered by the WSCC many times before. Perhaps the first instance was when default parameters for generator damper windings were extracted from a test insertion of the Chief Joseph dynamic brake in 1977. A good initial match was found with parameters that were not physically realistic. An equally good match was found with realistic parameters, and WSCC planners used them for several years thereafter.
A similar lack of uniqueness was found in the many hundreds of calibration studies that are summarized in [], and the criterion of physical realism was progressively applied to narrow the range of candidate models. It is also necessary to match against a comprehensive set of measured signals, and to use a full range of tools in assessing the differences between measured and modeled behavior. The sharpest of these will be frequency domain tools.
Even when all this is done, there is a very good chance that a model "calibrated" against one disturbance will not match other disturbances very accurately. It is necessary to calibrate against many disturbances, using data from key locations across the power system. Also, because disturbances are fairly infrequent and not always very informative, it is also necessary to calibrate against staged system tests and against background ambient behavior. The WSCC utilities, through their special needs in this area, are making good progress with the necessary WAMS facilities. Efficient and unambiguous procedures for model calibration remain an unsolved need, however.
- System Planning Issues
The engineering of large power systems is conducted in many different time frames, and with a wide variety of tools. The core tools for determining safe transfer capability are of three kinds:
- Powerflow
- Voltage stability
- Dynamic stability (sometimes called angle stability)
Though not common in other parts of North America, dynamic stability is a serious transmission constraint in the Western system. It is also a fairly subtle constraint, with some nuances that are not visible to conventional planning processes.
Power system analysis in North America tends to be very compartmentalized. With respect to dynamic analysis, the compartments are populated by a large number of planners who analyze power system models and by a far smaller number of engineers who directly analyze the system itself. Most of this direct analysis is performed at generator level, using methods and skills that are not commonly found among system planners [,].
Direct analysis at full system level is a recognized necessity for the WSCC. There are few organizational paradigms for this, however, and there is no accepted term that clearly denotes the activity. One of the few examples that does exist is the Systems Analysis Group that BPA once maintained for such work [,,]. This was, in effect, an advanced technology staff that supported both system planning and system operations. Today this unit might be considered part of system planning, but in an extended sense that would include measurement based analysis. For convenience the activity itself will be termed systems analysis, wherever it might actually reside within the organizational structure.
Fig. 10 indicates the earlier BPA paradigm for systems analysis. The block labeled as Criteria & Models for Systems Engineering is the primary location for decisions and delivered products. Included among these are
- Evaluation of power system dynamics
- Refinement of planning models and planning practices
- Engineering of major control systems
Reference [] indicates the software tools then in use at BPA. At that time (1987) relied upon its own technology for all of the functions indicated in Fig. 10, and had adapted various National Laboratory software packages for use in power system control. Much of this technology has since been donated to the electricity industry via EPRI [] and through the usual processes of technology diffusion. The controller design software has largely been displaced by Matlab™ toolsets [].
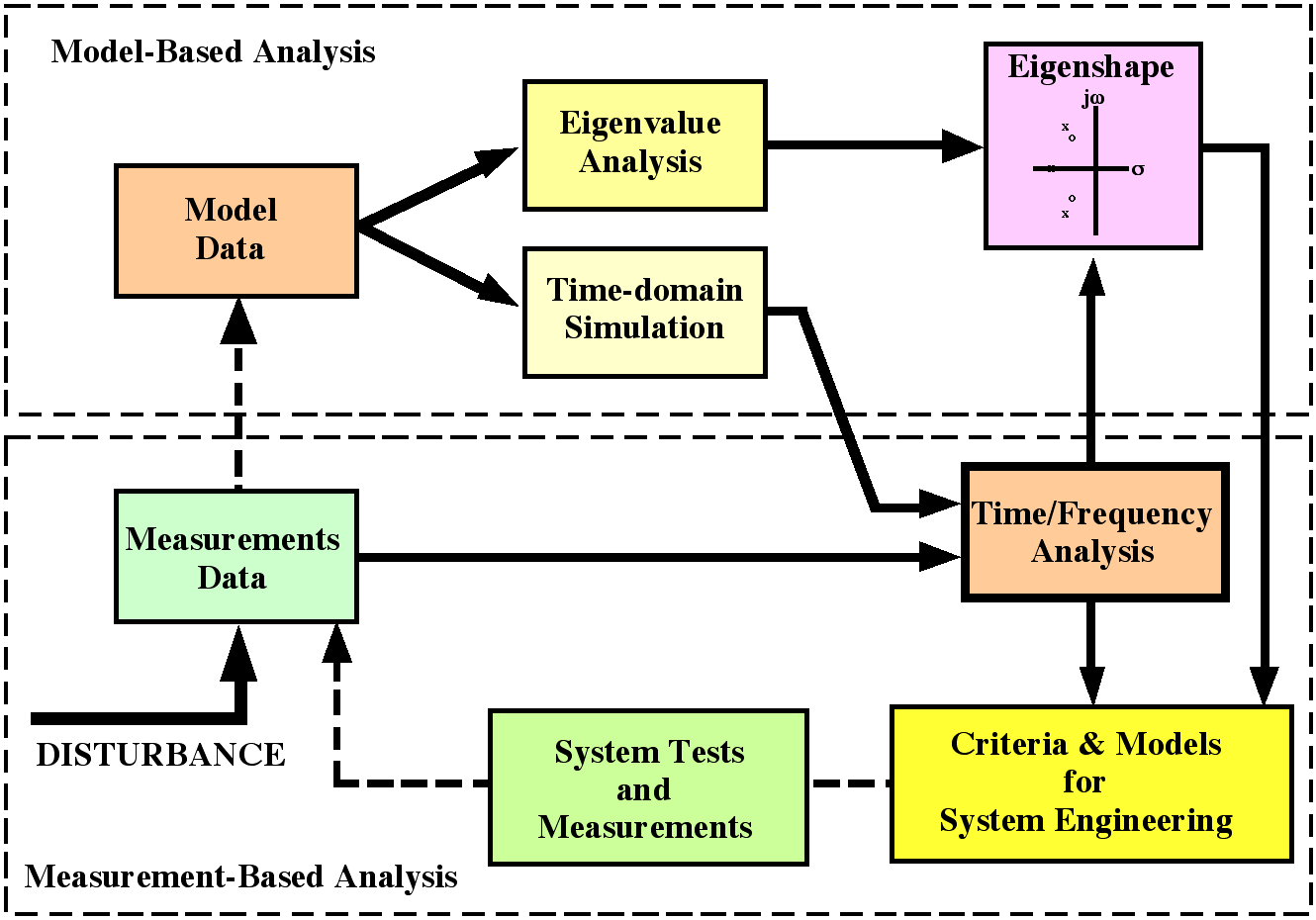
Fig. 10. Major functions in analysis and control of power system dynamics
A similar paradigm for systems analysis was recommended to the WSCC in 1990 by a special task force (termed an Ad Hoc Work Group, or AHWG). The WSCC established this particular AHWG in 1988, for the express purpose of dealing with a range of concerns expressed in []. The general thrust of these concerns was that the risk of 0.7 Hz oscillations was exaggerated by poor modeling, and that various proposed efforts to suppress such oscillations through feedback dampers might be unnecessary and could be dangerous to the power system.
In 1990 this AHWG presented findings and recommendations to the WSCC, and these were accepted by the WSCC Technical Studies Subcommittee (TSS) []. The technical recommendations are repeated below as a partial template for enhancing the reliability of power system modeling and control:
- Power system monitors should be installed at key locations around the Western system.
- Owners of facilities which are identified in the report as participating in poorly damped modes around 0.7 Hz are encouraged to review the [model] representation of these machines.
- In order to validate the planning models under highly stressed system conditions, it will be necessary to compare measured and modeled system response under these conditions. Future [system] tests to accomplish this task are highly recommended.
- A greater effort should be made by the WSCC to encourage the development and use of frequency domain analysis stools for evaluating system stability performance.
- Procedures should be set up to insure that major controllers around the WSCC system are properly designed, commissioned, operated, and monitored.
The AHWG was twice rechartered as the System Oscillation Work Group (SOWG) with expanded responsibilities []. Like the recommendations listed above, the charter for these task forces remains topical in the light of subsequent events:
- Coordinate the collection of test and disturbance data from monitors, and perform analysis on these data.
- Perform additional validation studies to calibrate the system planning models against actual system response.
- Provide assistance to the System Review [Work Group] and other TSS Work Groups for improving models/data used in conducting system studies.
- Monitor and promote the development of tools which could aid the analysis and mitigation of system oscillations.
- Conduct workshops/seminars and provide consultations, as necessary, to educate the WSCC members in the use of frequency analysis programs such as MASS, PEALS, Prony, etc.
- Enhance/refine tools for direct modal analysis of system oscillation records (i.e., output analysis).
- Encourage the application of frequency domain methods for power system analysis by the individual utilities. Monitor and report their application experiences to the WSCC.
- Provide technical review of proposed controllers which can have significant impact on system damping.
The SOWG effort was very active during its six year tenure, and it delivered an exceptional amount of material to the TSS. Reporting was piecemeal, however, and SOWG presented no consolidated reports of overall findings for the second and third phases. Reference [] was written to partially fill this void, and it was widely distributed through the WSCC prior to presentation in May 1996.
With respect to WSCC modeling, SOWG determined that
- Damping for 0.35 Hz oscillations (Canada — California) is sometimes much less than modeled.
- Damping for 0.7 Hz oscillations (N. California — Arizona) is usually better than modeled.
- Modeling for prime movers is quite optimistic, and affects damping estimates.
These problems were traced to undermodeling of key generation and transmission resources, simplistic load models, improper data, occasional software errors, and a general tendency toward uncritical acceptance of computer results. Appropriate countermeasures were identified, demonstrated, and recommended to the WSCC planning community.
Implementation of these countermeasures was slow and piecemeal, but important progress had been made when time ran out on August 10. Simulation codes had improved, BPA and EPRI codes for modal analysis were in general use at several utilities, and WSCC monitor facilities had been greatly enhanced under the DOE/EPRI WAMS effort. Anticipating future oscillation problems, BPA had commissioned the development of a PDCI model that was validated for use with EPRI’s eigenanalysis tools []. WSCC modeling practices remained much the same, however.
Fig. 9 demonstrates that the modeling problems noted earlier by SOWG still existed in 1996. Consistent with earlier warnings, it also argues that the "optimism" of such models had lead planning engineers to overestimate the safety factor for heavy imports of power from Canada. The engineering reviews that followed this breakup event produced findings and countermeasures that were essentially a subset of the earlier ones by SOWG.
The differences between the two sets of recommendations are important for their technical and their institutional implications. Before the August 10 breakup SOWG envisioned a high technology systems engineering approach, with frequency domain tools used both in planning and in direct analysis of system behavior. Model refinement would be an ongoing process, lead by a "virtual" staff of experts among the utilities. The WAMS effort, recognizing that the utilities were losing those experts, extended the "virtual techstaff" to include regionally involved National Laboratories and universities. Subsequent events have demonstrated the value of this broader support base.
Countermeasures actually adopted by the WSCC following the breakup are far more dependant upon model studies, and they contain far less provision for assuring model validity. Though used in forensic analysis of the breakup, frequency domain tools have been dropped from the recommended inventory of planning assets. The recently adopted WSCC software for planning studies does not include such tools, and very few utilities have staff with experience in frequency domain analysis. This will make model validation very difficult, and it will limit the planner’s understanding of system dynamics to what is immediately evident in time domain simulations. This does not include the small signal phenomena that produce adverse side effects in feedback control.
The central question, then, is less "what technologies are needed in system planning" than "what functions and what level of technology will be used in system planning." Operating utilities, the WSCC, and NERC itself have reduced their emphasis upon dynamic analysis. It has been reported that the newly formed Interregional Security Network (ISN) has no tools for this, and that its operational staff contains no engineers []. Provisions for continued technical support to regional reliability organizations like the WSCC are not yet clear.
- Institutional Issues — the WSCC
The protracted decline in planning resources that lead to the WSCC breakup of August 10, 1996, documents the way that deregulatory forces have undercut the ability of that particular reliability council to sustain essential competencies through voluntary mechanisms. Those same forces are at work across all of North America, and are probably eroding the effectiveness of other reliability councils there.
In the end event, the WSCC breakups of 1996 were the consequence of problems that had persisted for so long that they were either underestimated or effectively forgotten. A superficial reason for this was loss of the utility personnel who had usually dealt with such matters. A deeper reason was that "market signals" had triggered a race to cut costs, with minimal attention to the consequences for overall system reliability. Technical support to the WSCC mission underwent a protracted decline among the utilities, with a resultant weakening of work group staffing and leadership.
Even more so than EPRI, the WSCC is a voluntary organization that depends upon involved members to contribute technical work. The WSCC does not have a full in-house staff of high level experts. Most expertise is provided by work groups that, collectively, draw together a "critical mass" of technical skills and operational involvement. Participation in such a group, like participation in the WSCC itself, is optional. There is no assurance that utilities will retain personnel that are qualified for this, or will make them available when needed. The WSCC would find it very difficult to repeat the SOWG effort of earlier years.
Once launched, work group activities can be difficult to sustain. Key individuals may change jobs, or find that they have insufficient time for work group involvement. The work group chair usually serves a two-year term, and the special costs that attend this function make it unattractive to utility budget managers. Such factors undercut continuity of the effort, even at the work group level.
These problems become more severe at higher levels. It is notable that, during its six year tenure, no member of the permanent WSCC staff was ever present at a SOWG meeting. SOWG findings were volumous, unusually technical, and interlaced with field operations. Much of this was unfamiliar to most members of the Technical Studies Subcommittee, and to WSCC staff. The extent to which the TSS assessed SOWG findings and forwarded them to higher WSCC levels for consideration is not a matter of record. However, considering its modest size and technical composition, the WSCC staff by itself is not well equipped to assure continuity in the multitude of diverse efforts that are involved in a large power system. The primary WSCC mission is to coordinate, not to lead, and it is staffed accordingly.
It should also be recognized that, in a voluntary organization, the need for consensus tends to discourage candor (especially in written reports). This imposes yet another impediment to communication, to well focused decisions, and to continuity of effort. It is also another argument for increasing the authority – and the technical competence – of regional reliability organizations.
- Institutional Issues — the Federal Utilities and WAMS
The progressive decline of WSCC reliability assets that preceded the 1996 breakups did not pass unnoticed by Federal utilities in the area. Under an earlier Program, the DOE responded to this need through a technology demonstration project that was of great value for understanding the breakups. Examination of this Project provides useful insights into possible roles for the DOE and the Federal utilities in reliability assurance.
There are four Federal utilities that provide electrical services within the western power system. These are the Bonneville Power Administration (BPA), the Western Area Power Administration (WAPA), the U.S. Bureau of Reclamation (USBR), and the U.S. Corps of Engineers (USCoE). All of these have unique involvement, experience, and public service responsibilities. The two Power Marketing Agencies (BPA and WAPA) have been lead providers of reliability services and technology since their inception.
In 1989 BPA and WAPA joined the DOE in an assessment of longer-term research and development needs for the future electric power system [,]. These field agencies of the DOE conveyed a strong concern that market forces attending "the transition" to a deregulated electricity markets were a major disincentive to what are now called reliability investments, and that reliability assets were undergoing a protracted and serious decline. A considerably enhanced information infrastructure, defined broadly to include human resources and collaboration technologies, was seen as the most immediate critical path need for improving both system reliability and assets management.
The rationale for this Federal involvement was based upon the problems underlying reference [], and upon observed weakening of the infrastructure to deal with them. A personal perspective dating from the 1991-1992 era summarized the infrastructure decline as follows:
- The U.S. is facing a serious and growing shortage of advanced engineering resources that are essential to the effective development and operation of large power systems. It is particularly visible in the areas of power system dynamics and control.
- This shortage will increase for many years, even if a high-level response were to start immediately.
- Power system problems are reaching levels of technical complexity where appropriately skilled utility staff is thinly spread, diminishing, and unlikely to be replaced. This will progressively reduce utility effectiveness in planning, conducting, contracting, or advising associated R&D efforts.
- A shortage of technically knowledgeable industry advisors will also diminish the effectiveness of R&D efforts at EPRI, and shift their overall leadership toward the EPRI contractor.
- There will be a continuing trend toward the concentration of "high tech" power engineers at progressively fewer technology centers, where (multidisciplinary) staff and other resources can be maintained at the levels necessary to effective R&D operations. This aggravates utility staffing problems, and it further dilutes the utility perspective in R&D programs.
- Utilities are loosing important elements of their institutional memory through staff attrition. Federal agencies with utility operations share in this, often at a higher level and at a higher indirect cost to the industry.
- The most immediately effective countermeasure to these problems lies in regional consortia of Federal agencies that exercise power utility operations, in association with regionally involved National Laboratories and universities.
The final "bullet" would, during the transition, draw upon the National Laboratories for infrastructure reinforcement in areas such as technology access, advanced systems engineering, and some aspects of emergency response. It is one of many linkages between WAMS and CERTS.
These matters were pursued further under the DOE Initiative for Real Time Control and Operation [,]. Within this Initiative, BPA and WAPA proposed a demonstration effort that would immediately reinforce reliability assets in the WSCC, and provide a template for similar action in other power systems. The core of this was the System Dynamic Information Network (WeSDINet) Project to
- Develop and install an advanced-technology information network for measuring and monitoring of western system dynamics.
- Research and develop advanced, production grade mathematical tools for extracting dynamic information from power system measurements.
- Apply the above resources — collectively referred to as WesDINet — to directly examine overall dynamics of the western power system.
The dynamic phenomena to be examined range from power flow control and slow voltage collapse to transient stability, interarea oscillations, and control system interactions. Some major objectives in this were to resume and expand the SOWG effort, to establish the information base for next generation control systems, and to greatly expand the technical support base for reliability assurance.
The first WeSDINet Task was approved and funded as the Wide Area Measurement System Project. Many of the elements in the WeSDINet proposal are now being examined or supported by the DOE, EPRI, CERTS, and other organizations. An expanded version of the collaborative infrastructure recommended for WAMS/WeSDINet is now being considered by the DOE and EPRI as a National Consortium for Power System Reliability.
As intended, WAMS has indeed provided a template for meeting the information needs of the future power system. It can also be argued that the monetary investment in WAMS was recaptured fully during the summer of 1996. WAMS data was a highly valuable information source for the extensive engineering reviews that followed the July 2 and August 10 breakups. On August 10 WAMS information was also used more directly when, within minutes of the breakup, WAMS records were reviewed as a guide to immediate operating decisions in support of WSCC system recovery. Had the other WeSDINet Tasks been funded the August 10 breakup might well have been avoided. As it was, the WAMS task itself came close to making displays like those of Fig. 5 through Fig. 7 available to BPA operations staff in real time.
The immediate question is not whether the Federal government should be directly involved in power system reliability. The DOE is already involved, and to good effect. A more pressing question is whether the reliability services customarily provided by the Federal utilities should be further reduced, or withdrawn entirely. They, like nearly all utilities now, are hard pressed to rationalize or sustain such activities in a new business environment where public service is an unfunded mandate. The time for averting a full loss of the essential competencies they provide in reliability assurance may be very short.
- Focus Areas for DOE Action
The general thrust of this White Paper has been to identify functional needs in the assurance of power system reliability. A fairly broad set of power system events has been examined for their reliability implications. Where possible, the chain of evidence has been tracked backwards from what happened to how it happened and where it might have been avoided. This lead from things so simple as defective relays to National policy, market dynamics, and the immutable law of unintended consequences.
An important next step in the CERTS effort is to identify options by which DOE can reinforce power system reliability, both at the institutional level and in technology RD&D. It is for National Policy to determine, from the things that the DOE can do, which things the DOE should do. A proper determination must assess the likely consequences of the choices available. These consequences depend very much upon the structure and the dynamics of future markets — and thus upon National Policy. This circularity in an attempt at linear reasoning demonstrates that reliability, costs, market dynamics, institutional roles, policy issues, and technology values are all linked together in the energy future. Those linkages should be determined and respected. Other CERTS White Papers address this.
There are many specific technologies that would be useful in meeting the functional needs that are identified in this particular White Paper. References [,,,] and the various WAMS report materials are also good sources for candidate technologies. A list of useful technologies is not enough, however. Technologies that are deserving of DOE support should have high strategic value in the more probable energy futures, and a low probability of timely deployment without that support. Technologies that can be readily developed and that have obvious high value will likely be developed by commercial vendors, or by the operating utilities themselves. Even then the present uncertainties concerning institutional roles may make the development and deployment too late to avert pending reliability problems. Transfers of DOE technology, or other forms of DOE participation, may be needed just to reduce costs and to assure an adequate rate of progress in reinforcing critical infrastructure.
To be fully effective in this the DOE should probably seek closer "partnering" with operating elements of the electricity industry. This can be approached through greater involvement of the Federal utilities in Laboratory activities, and through direct involvement of the Laboratories in support of all utilities or other industry elements that perform advanced grid operations. The following activities are proposed as candidates for this broader DOE involvement:
- National Institute for Energy Assurance (NIEA) to safeguard, integrate, focus, and refine critical competencies in the area of energy system reliability. The NIEA will be organized as a distributed "virtual organization" consisting of the Department of Energy and its National Laboratories, the Federal Utilities, and energy industry groups such as the Electric Power Research Institute and the Gas Research Institute. The NIEA will provide coordination with universities and other industry organizations, and provide collaborative linkages with other professional organizations and the vendor community. The NIEA will expedite sharing and transfer of technology, knowledge, and skills developed within the Federal system. Electric utilities, grid operators, and reliability organizations such as NERC/NAERO will be supported by the NIEA as needed, and through the formation of "SWAT Teams" during unusual system emergencies.
- Dynamic Information Network (DInet) for reliable planning and operation. An advanced demonstration project building upon the earlier DOE/EPRI Wide Area Measurement System (WAMS) effort, plus Federal technologies for data mining, visualization, and advanced computing. Core technologies also include centralized phasor measurements, mathematical system theory, advanced signal analysis, and secure distributed information processing. The DInet itself will provide a testbed for new technology, plus information support to wide area control projects and the evolving Interregional Security Network. Focus issues for this program include direct examination and assessment of power system dynamic performance, systematic validation and refinement of computer models, and sharing of WAMS technologies developed for these purposes.
- Modeling the Public Good in Reliability Management. Exploratory research into means for representing National interests as objectives and/or constraints in the emerging generation of decision support tools for reliability management. Examples of National interests include an effective power grid for the deregulated US power markets and a secure, resilient grid to protect the national interests in an increasingly digital economy. The key technical product will be a global framework for reliability management that incorporates a full range of technical, social and economic issues. Elements within this framework include determining and quantifying the full impact of reliability failures, probabilistic indicators for risk, treatment of mandates and subjective preferences toward options, mathematical modeling, and decision algorithms. To test and evaluate the principles involved, this research may include joint demonstration projects with EPRI or other developers of probabilistic tools.
- Recovery Systems for Disturbance Mitigation, to lessen the impact of system disturbances and to lessen the dependence upon preventive measures. Dynamic restoration controls, based upon real time phasor information, would reduce the violence of the event itself and steer the system toward automatic reclosure of open transmission elements. This might include temporary separation of the system into islands that are linked by HVDC or FACTS devices. If needed, operators would continue the process and restore customer services on a prioritized basis. Comprehensive information systems (advanced WAMS) would expedite the engineering analysis and repair processes needed to fully restore power system facilities.
All of these activities would take place at the highest strategic level, and in areas that commercial market activities are unlikely to address.
- Summary of Findings and Implications
The conclusions in this White Paper are based upon eleven major disturbances to the North America power system. Most of them occurred in this decade. Two earlier ones — in 1965 and 1977 — are included as early indictors of technical problems that are a natural consequence of interconnecting large power systems into even larger ones. These problems continue to the present day.
Primary contributions of this White Paper include the following:
- Summary descriptions of the system events, with bibliographies
- Recurring factors in these events, presented as technical needs
- Results showing how better information technology would have warned system operators of impending oscillations on August 10, 1996
- The progression by which market forces eroded WSCC capability to anticipate and avoid the August 10 breakup
- The progression by which market forces eroded the ability of BPA, and other Federal utilities, to sustain their roles as providers of reliability services and technology
- "Lessons learned" during critical infrastructure reinforcement by the DOE WAMS Project.
Various materials are also provided as background, or for possible use in related documents within the Project. The issues derived from the examined events are, for the most part, stated as problems and needs. Translating these into explicit recommendations for Federally supported R&D is reserved for a subsequent effort.
The strategic challenge is that the pattern of technical need has persisted for so long. Anticipation of market deregulation has, for more than a decade, been a major disincentive to new investments in system capacity. It has also inspired reduced maintenance of existing assets. A massive infusion of better technology is emerging as the final option for continued reliability and adequacy of electrical services [,]. If that technology investment will not be made in a timely manner, then the fact should be recognized and North America should plan its adjustments to a very different level of electrical service.
It is apparent that technical operations staff among the utilities can be very effective at marshaling their forces in the immediate aftermath of a system emergency, and that serious disturbances often lead to improved mechanisms for coordinated operation. Such activities are usually coordinated through the regional reliability council, though smaller ad hoc groups sometimes arise to expedite special aspects of the inter-utility coordination that is needed. In the longer run, it is the effectiveness of such institutions that most directly affect system reliability.
It is also apparent that a reliability council is rather more effective at responding to a present disaster than at recognizing and managing the risks that precede it. Immediate problems on the system are tangible, and the institutional missions are clear. Responsibilities for the future power system are much less clear. It is unusual for an RRC to have a full staff of advanced technical experts. Instead, new or urgent problems are met by a utility task force that, collectively, draws together a "critical mass" of technical skills and operational involvement. Participation in such a task force, like participation in the RRC itself, is voluntary — and there is no assurance that utilities will have appropriate staff available. The protracted decline in planning resources that lead to the WSCC breakup of August 10, 1996, documents the way that deregulatory forces have undercut the ability of that organization to sustain essential competencies through the voluntary mechanisms of former times. The market forces that caused this pervade all of North America. Similar effects should be expected throughout, though the symptoms will vary by region and time frame.
The August 10 Breakup also demonstrates that better information resources could have warned system operators of impending problems in the final hours and minutes, and that better control resources might have avoided the final breakup or at least minimized its impact. The finer details of these matters have not been fully resolved, and they many never be. The final message is a broader one. All of the technical problems that the WSCC identified after the August 10 Breakup had already been reported to it in earlier years, along with an expanded version of the same countermeasures. Development and deployment of recommended information technology was also underway before the breakup, but proceeding slowly. The actual breakup reflects a coincidence of many chance factors, facilitated by a gradual fragmenting and loss of the collective WSCC memory.
Hopefully, such institutional weaknesses are a transitional phenomenon that will be remedied as a new generation of grid operators evolves, and as the reliability organizations acquire the authority and staffing consistent with their expanding missions. This will provide a more stable base and rationale for infrastructure investments. It will still leave difficult issues in the accommodation of risk and the management of reliability. Technology can provide better tools for this, but it is National policy that will determine if and how such tools are employed []. That policy should consider the deterrent effect that new liability issues pose for the pathfinding uses of new technology or methods in a commercially driven market [,].
The progressive decline of WSCC reliability assets that preceded the 1996 breakups did not pass unnoticed by Federal utilities in the area. Under an earlier Program, the DOE responded to this need through a technology demonstration project (WAMS) that was of great value for understanding the breakups. Had the WAMS Project started somewhat earlier, or had it been funded in its original broad form, the August 10 breakup might have been avoided entirely. The continuing WAMS effort provides useful insights into possible roles for the DOE and the Federal utilities in reliability assurance. An expanded version of the collaborative infrastructure pioneered under WAMS is now being considered by the DOE and EPRI as a National Consortium for Power System Reliability. Such efforts have also been undertaken by CERTS, and under a Federal program in Critical Infrastructure Protection.
June 1999 Heat Wave — NPCC Final Report. Presented to the NPCC Executive Committee Sept. 1, 1999. Available at http://www.npcc.org/.
REFERENCES