Sanskrit Computing Research
"If you don't need a new technique,
what you're saying is probably not new."
![]() -- Philip Glass
-- Philip Glass
Introduction
- Despite strong end-user communities and scholarly interest, electronic resources for Indo-Tibetan research have remained scarse for a variety of reasons. Consequently, the compilation of large e-text corpora and lexical resources has lagged behind other language groups.
- Two key areas that I have devoted time to in an effort to overcome these lacunae are: Devanagari and Tibetan OCR, and Sanskrit-Tibetan lexicon construction. I have discussed some of my work in these areas, below.
Devanagari OCR
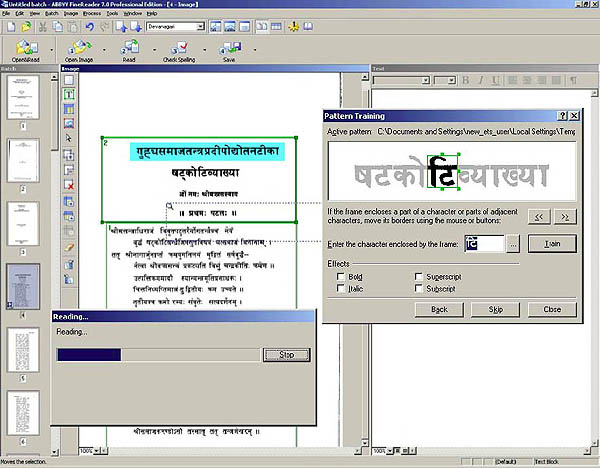
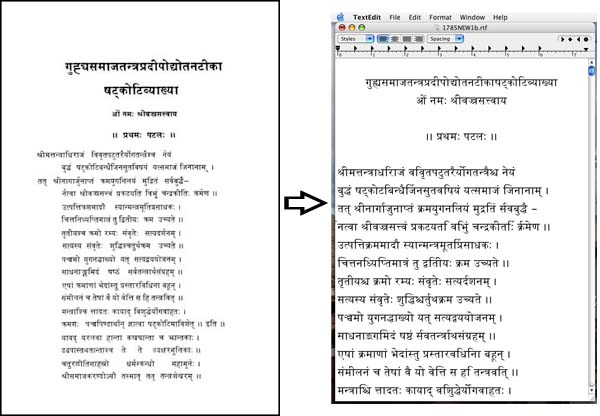
- Because Indo-Tibetan Buddhist religion and philosophy is heavily textually grounded, a key resource in contemporary research is searchable e-text. While there are several on-going efforts to manually key Tibetan and Sanskrit texts, "Optical Character Recognition" (OCR) technology for Tibetan and Devanagari scripts has lagged behind in this field. To this end, I have been training commercially available software (ABBYY FineReader) at the task of Devanagari OCR for several years (and hope to train the software for Tibetan in the future).
-
The end result of this effort has been a system that offers 90-95% accuracy (testing and evaluation is still on-going)
at the task of Devanagari OCR, producing Unicode e-text. Although the software has certain systemic weaknesses, it is hoped that these issues will be resolved in a future version of the program, thereby improving the accuracy. Nonetheless, in the meantime, the system
offers a viable means of rapidly producing Sanskrit e–text for research purposes.
-
After some additional training, it is my intention to make the recognition files freely available to scholars and researchers.
Tibetan-Sanskrit Lexicons
- While many key dictionaries for Sanskrit and Tibetan have been published over the past 150 years,
migration of these resources into an electronic environment has been slow.
- Working in conjunction with Robert Chilton of the Asian Classics Input Project (ACIP), I have been working on
processing one of these resources, Lokesh Chandra's Tibetan-Sanskrit Dictionary, for import into an electronic
lexicon for both general reference purposes and the refinement of a larger Tibetan Machine Translation lexicon (a subset of this data has been published in: A Tibetan Verb Lexicon).
- Lokesh Chandra's original dictionary has been scanned, and also electronically keyed by ACIP staff.
- I have written a series of post-processing programs to automatically tag the dictionary for importing into a database.
Although this work is on-going, a preliminary sample of the resulting data is given below:

| <entry> | ||||
| <headword>KA</headword> | ||||
| </entry> | ||||
| <entry> | ||||
| <headword>KA</headword> | ||||
| <sense> | ||||
| <term lang="skt" scr="rom-dev">stambha</term> | ||||
| <term lang="skt" scr="rom-tib">STAM BHA</term> | ||||
| <citation> | ||||
| <citeRef>bo.ca.5.40kha</citeRef> | ||||
| </citation> | ||||
| </sense> | ||||
| </entry> | ||||
| <entry> | ||||
| <headword>KA KA</headword> | ||||
| <altheadword>K'A KA</altheadword> | ||||
| <sense> | ||||
| <term lang="skt" scr="rom-dev">ka#ka</term> | ||||
| <term lang="skt" scr="rom-tib">K'A KA</term> | ||||
| <citation> | ||||
| <citeRef>s*a.da#</citeRef> | ||||
| </citation> | ||||
| </sense> | ||||
| </entry> | ||||
| <entry> | ||||
| <headword>KA KA NI</headword> | ||||
| <sense> | ||||
| <senseNo>1</senseNo> | ||||
| <term lang="skt" scr="rom-dev">kapardaka</term> | ||||
| <term lang="skt" scr="rom-tib">KA PAR DA KA</term> | ||||
| <citation> | ||||
| <citeRef>s*a.da#</citeRef> | ||||
| </citation> | ||||
| </sense> | ||||
| <sense> | ||||
| <senseNo>2</senseNo> | ||||
| <term lang="skt" scr="rom-dev">ka#kan%i</term> | ||||
| <term lang="skt" scr="rom-tib">K'A KA nI</term> | ||||
| <citation> | ||||
| <citeRef>ma.vyu.9375</citeRef> | ||||
| </citation> | ||||
| <term lang="skt" scr="rom-dev">ka#kin%i#</term> | ||||
| <term lang="skt" scr="rom-tib">K'A KI n'I</term> | ||||
| <citation> | ||||
| <citeRef>s*a.da#</citeRef> | ||||
| </citation> | ||||
| </sense> | ||||
| </entry> | ||||
Having secured distribution rights from Lokesh Chandra, it is the intention of ACIP to distribute this data (in both romanization and Unicode script) for the benefit of the research community.