
DB2's exploitation of the mutual takeover mode has the same basic characteristics as that for the hot standby mode. In this mode, one processor can failover the single-partition database instance, or the partitions of a partitioned database, of a failed processor while running another instance or other partitions of a partitioned database configuration. As with the hot standby configuration, the installation path, the instance directory, and the database must be mutually accessible by each processor which may be involved in failover processing. The installation and instance paths can either be on a shared filesystem or mirrored on separate filesystems.
When utilizing the mutual takeover mechanism, for instance failover, the instances must be defined in such a manner that both instances can be run on the same processor at the same time. For detailed information on the actual installation requirements and instance creation, refer to HACMP for AIX, Version 4.2: Installation Guide, SC23-1940.
Each of the following examples has a sample script stored, on AIX-based installations, in sqllib/samples/hacmp.
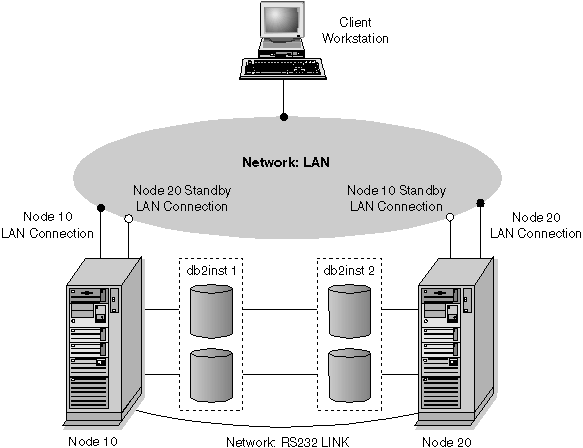
In order to illustrate a mutual instance failover, we will use the simple case of a HACMP system with two processors known as "node10" and "node20".
Figure 68. Instance Failover Example
In this example, we have two instances "db2inst1" and "db2inst2": both are instances created from a single installation path on a shared filesystem. Instance "db2inst1" is created with a path of
/u/db2inst1
and instance "db2inst2" is created with a path of
/u/db2inst2
Both of these paths are on a shared filesystem accessible to both processors. Each instance has a single database, with a unique path, again on a shared resource accessible by both processors.
Both instances are accessed via remote clients over the TCP/IP protocol: "db2inst1" uses the service name "db2inst1_port" (port number 5500) and "db2inst2" uses the service name "db2inst2_port" (port number 5550). Remote clients accessing the "db2inst1" instance have this instance cataloged in their node directory using "node10" as the host name. Remote clients accessing the "db2inst2" instance have this instance cataloged in their node directory using "node20" as the host name. Under normal operating conditions, "db2inst1" is executing on "node10" and "db2inst2" is executing on "node20". If "node10" were to fail, the failover script will start "db2inst1" on "node20" and the external IP address associated with "node10" will be switched over to "node20". Once the instance has been started by the failover script and the database restarted, the remote clients accessing this instance can connect to the database within this instance as if it were executing on "node10".
Sample script:
Mutual failover of partitions in a partitioned database server environment requires that the failover of the partition occur as a logical node on the failover processor. If we have two partitions of a partitioned database server running on separate processors of a two processor HACMP cluster configured for mutual takeover, the partitions must failover as logical nodes. The default partition at each node must be defined as logical node 0, this means that when a partition fails over from one processor to another it will start as a logical node which does not have any direct remote communication protocol listeners. As such, the partition cannot be used as a coordinator node.
One other important consideration when configuring a system for mutual partition takeover concerns the local partition database path. When a database is created in a partitioned database environment, it is created on a root path which is not shared across the partitioned database servers. For example, consider the following statement:
CREATE DATABASE db_a1 ON /dbpath
This statement is executed under instance "db2inst" and creates the database db_a1 on the path /dbpath. Each partition creates its actual database partition on its local /dbpath filesystem under /dbpath/db2inst/nodexxxx where xxxx represents the node number. With HACMP failover it will attempt to mount the /dbpath filesystem which is already being used by the other processor. As such, the failover script must mount the filesystem under a different logical point and set up a symbolic link from that filesystem to the appropriate /dpath/db2inst/nodexxxx path.
The following example shows a portion of the db2nodes.cfg file before and after the failover. In this example, node number 2 is running on processor 1 of the HACMP machine which has a hostname of "node201" and the netname is the same. Node number 3 is running on processor 2 of the HACMP machine which has a hostname of "node202" and again the netname is the same. The failover script will execute the command between the before and after definitions.
Before:
1 node101 0 node101
2 node201 0 node201 <= HACMP
3 node202 0 node202 <= HACMP
4 node301 0 node301
db2start nodenum 2 restart hostname node202 port 1 netname node202
After:
1 node101 0 node101
2 node202 1 node202 <= HACMP
3 node202 0 node202 <= HACMP
4 node301 0 node301
After the failover, any remote clients trying to directly access node number 2 as the coordinator will have to re-catalog the node entry for the database to point to the failover node. It is not recommended that you use a mutual failover scenario for coordinator nodes. If you require redundancy with your coordinator node, you should you use the hot standby mode.
Sample script: