
The IMPORT and EXPORT utilities may be used to transfer data between DB2 databases, and to and from DRDA host databases.
DataPropagator Relational (DPROPR) is another method for moving data between databases in an enterprise.
The following topics provide more information:
Compatibility considerations are most important when loading or importing/exporting data between Intel-based and UNIX-based platforms.
If you are working with typed tables in a hierarchy, you can move the hierarchy in addition to the data from a source database to a target database. When the REPLACE option is used when moving data between hierarchies, you can only replace the data for an entire hierarchy, not individual subtables.
For more information, see the following topics:
PC/IXF is the recommended format for transferring data between DB2 databases. PC/IXF files allow the Load utility or the Import utility to process numeric data, normally machine dependent, in a machine independent fashion. For example, numeric data is stored and handled differently in Intel** and other hardware architectures.
To provide compatibility of PC/IXF files between all products in the DB2 family the EXPORT utility creates files with numeric data in Intel format, and the IMPORT utility expects it in this format.
| Note: | Depending on the hardware platform, DB2 products convert numeric values between Intel and non-Intel formats (using byte reversal) during both export and import operations. |
Multiple Part Files: UNIX-based implementations of DB2 do not create multiple-part PC/IXF files during export. However, they will allow you to import such a file that was created by DB2 for OS/2. When importing this type of file, all parts should be in the same directory, otherwise an error is returned by the utility.
The single-part PC/IXF files created by the UNIX-based implementations of DB2 export utility can be imported by DB2 for OS/2.
DEL files have differences based on the operating system on which they were created. The differences are:
Since DEL export files are text files, they may be transferred from one operating system to another. File transfer programs handle the above differences if you transfer the file using the text mode. Using the binary mode to transfer the file does not convert row separator and end-of-file characters as required.
If character data fields contain row separator characters, these will also be converted during the file transfer. This conversion will cause an inappropriate change to the data and as a result, when the file is imported into a database on the different platform, data shrinkage or expansion may occur. For this reason, we recommend that you do not use DEL export files to move data between DB2 databases.
Numeric data in WSF format files is stored using Intel machine format. This format allows Lotus WSF files to be transferred and used in different Lotus operating environments (for example, Intel-based and UNIX-based systems).
As a result of this consistency in internal formats, exported WSF files from DB2 products can be used by Lotus 1-2-3 and Symphony running on a different platform. DB2 products can also import WSF files that were created on different platforms.
Transfer WSF files between operating systems platforms in binary, not text mode.
Do not use the WSF file format to transfer data between DB2 databases, since a loss of data may occur. Use the PC/IXF file format instead.
db2move is a tool that can help move large numbers of tables between DB2 databases located on workstations. db2move queries the system catalog tables for a particular database and compiles a list of all user tables. The tool then exports these tables in PC/IXF format. The PC/IXF files can be imported or loaded to another local DB2 database on the same system, or can be transferred to another workstation platform and imported or loaded to a DB2 database on that platform.
db2move calls the DB2 export, import, and load APIs depending on the action requested by the user. Therefore, the requesting user ID must have the correct authorization required by the APIs or the request will fail. Also, db2move inherits the limitations and restrictions of the APIs. db2move is found in the misc subdirectory of the sqllib directory.
The syntax of the tool is:
db2move dbname action [options...]
The dbname is the name of the database. The action must be one of: EXPORT, IMPORT or LOAD. The options are:
This is an EXPORT action only. If specified, only those tables created by the creators listed with this option are exported. If not specified, the default is to use all creators. When specifying multiple creators, each must be separated by commas; no blanks are allowed between creator IDs. The maximum number of creators that can be specified is 10. This option can be used with the "-tn" table-names option to select the tables for export.
The wildcard character, asterisk (*), can be used in table-creators and can be placed anywhere in the string.
This is an EXPORT action only. If specified, only those tables whose names match exactly to those in the specified string are exported. If not specified, the default is to use all user tables. When specifying multiple table-names, each must be separated by commas; no blanks are allowed between table-names. The maximum number of table-names that can be specified is 10. This option can be used with the "-tc" table-creators option to select the tables for export. db2move will only export those tables whose names are matched with specified table-names and whose creators are matched with specified table-creators.
The wildcard character, asterisk (*), can be used in table-names and can be placed anywhere in the string.
Valid options include INSERT, INSERT_UPDATE, REPLACE, CREATE, and REPLACE_CREATE.
Valid options include INSERT and REPLACE.
This option shows the absolute path names where LOB files are created (as part of EXPORT) or searched for (as part of IMPORT or LOAD). When specifying multiple lobpaths, each must be separated by commas; no blanks are allowed between lobpaths. If the first path runs out of space (during EXPORT) or the files are not found in the path (during IMPORT or LOAD), the second path will be used. Each subsequent path will be used for the same reasons should the same conditions exist.
If the action is an EXPORT and lobpaths are specified, all files in the lobpath directories are deleted, the directories are removed, and new directories are created. If not specified, the current directory is used for the lobpath.
Both user ID and password are optional. However, if one is specified, both must be specified. If db2move is run on a client connecting to a remote server, user ID and password should be specified.
Both user ID and password are optional. However, if one is specified, both must be specified. If db2move is run on a client connecting to a remote server, user ID and password should be specified.
The following are several examples showing the db2move:
This will export all tables in sample; the defaults are used for all options.
This will export all tables created by "userid1" or user IDs LIKE "us%rid2"; and, table-name is "tbname1" or table-names LIKE "%tbname2".
This example is applicable for Intel-based platforms only. This will import all tables in sample; any LOB files are to be searched for using lobpaths "D:\LOBPATH1" and "C:\LOBPATH2".
This example is applicable for UNIX-based platforms only. This will load all tables in sample; any LOB files are to be searched for using the lobpath subdirectory in the userid subdirectory of the the home directory or in the tmp subdirectory.
This will import all tables in sample in REPLACE mode; the user ID and password are used.
Usage notes:
The db2move LOAD action is not supported in DB2 Universal Database where partitioned databases may be used.
Notes when using EXPORT:
"nnn" is the table number. "c" is a letter of the alphabet. "yyy" is a number ranging from 001 to 999.
These files are created only if the table being exported contains LOB data. If created, these LOB files are placed in the "lobpath" directories. There are a total of 26 000 possible names for the LOB files.
Notes when using IMPORT:
Notes when using LOAD:
You may be working in a more complex environment where you need to move data between a host database system and the workstation environment. In such an environment, you may work with DB2 Connect; as the gateway for the data from the host to the workstation as well as the reverse.
The following section discusses the considerations when importing and exporting data using DB2 Connect.
The import and export utilities let you move data from a DRDA server database to a file on the DB2 Connect workstation or vice versa. You can then use this data with any other application or RDBMS that supports this import/export format. For example, you can export data from DB2 for MVS/ESA into a delimited ASCII file and later import it into a DB2 for OS/2 database.
You can perform export and import functions from a database client or from the DB2 Connect workstation.
Notes:
To export to a DRDA server database:
To import data from a DRDA server database:
With the DB2 Connect program, import or export operations must meet the following conditions:
If these conditions are violated, the operation will fail and an error message will be generated.
If you import and export mixed data (columns containing both single-byte and double-byte data), consider the following:
The function of the SQLQMF utility with DDCS for OS/2 has been replaced by the DB2 Connect Import/Export functions. The advantages are:
Refer to the Command Reference for further information on using these commands.
EXPORT and IMPORT can be used to move data out of, and into, typed tables. These tables may be in a hierarchy. The complexity of the data movement involving hierarchies includes the requirements to:
A special case also exists when using IMPORT: The CREATE option allows for the creation of the table hierarchy and also the type hierarchy. If the type hierarchy already exists there is no creation required.
Identification of types in a hierarchy is "database dependent". This means that in different databases, the same type has a different identifier. Therefore, when moving data between these databases, a mapping of the same types must be done to ensure the data is moved correctly.
When using EXPORT, before each typed row is written out, an identifier is translated to an "index-value". This index-value can be any number from one (1) to the number of relevant types in the hierarchy. These index-values are obtained by numbering each type when moving through the hierarchy in a specific order. This order is called "traverse order".
There is a default traverse order where all relevant types refer to all reachable types in the hierarchy from a given starting point in the hierarchy. There is also a "user-specified traverse order" where the user defines in a traverse order list those relevant types to be used. The same default or user-specified traverse order must be used when using the EXPORT utility and when using the IMPORT utility.
The default traverse order behaves differently in different file formats. You should assume identical table hierarchy and type relationships in each case presented below.
The PC/IXF file format EXPORT creates a record of all relevant types, their definition, and relevant tables. EXPORT also completes the mapping of an index-value to each table. During the IMPORT, the index-value to table mapping is used to ensure accurate movement of the data to the target database. When using the PC/IXF file format, you should use the default traverse order.
With the ASC/DEL/WSF file formats, although the source and target hierarchies may be structurally identical, the order in which the typed rows and the typed tables were created could be different. This would result in time differences that the default traverse order would identify when proceeding through the hierarchies. The creation time of each type determines the order taken through the hierarchy at both the source and the target when using the default traverse order. You must ensure that the order of creation of each type in both the source and the target hierarchies is identical in addition to ensuring the structural identity between source and target. If you cannot, then you must use the user-specified traverse order.
When you wish to control the traverse order through the hierarchies, you must be aware of the following conditions:
The movement of data from one hierarchical structure of typed tables to another is through a specific traverse order and the creation of an intermediate flat file.
Control of what is placed from the source database into the intermediate file is through the EXPORT utility (in conjunction with the traverse order). You only need to specify the target table name along with the WHERE clause. The EXPORT takes this selection criteria and creates the appropriate intermediate file. Only the selected data from the source database is moved to the target database.
Control of what is placed from the intermediate file into the target database is through the IMPORT utility. You can optionally specify an attributes list at the end of each subtable name to restrict those attributes moved to the target database. If no attributes list is used, all of the columns for that subtable are moved.
Control of the size and placement of the hierarchy being moved is through the IMPORT utility with the CREATE, INTO table-name, UNDER, and AS ROOT TABLE parameters. See the Command Reference for more information on the IMPORT utility parameters.
Both the REPLACE and REPLACE CREATE options for the IMPORT utility are only supported for an entire hierarchy.
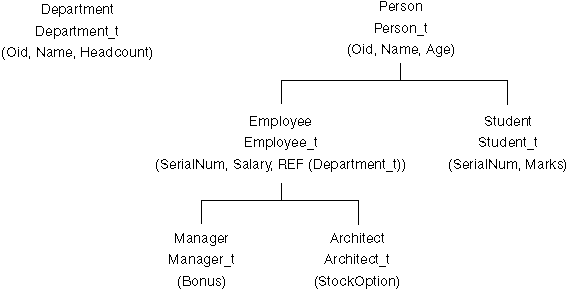
Some examples will be presented here based on the following defined hierarchical structure:
In the most basic of examples, we would like to export an entire hierarchy and re-create the entire hierarchy during the import. The order of activity is as follows:
DB2 CONNECT TO Source_db
DB2 EXPORT TO entire_hierarchy.ixf OF IXF HIERARCHY STARTING Person
DB2 CONNECT TO Target_db
DB2 IMPORT FROM entire_hierarchy.ixf OF IXF CREATE INTO
HIERARCHY STARTING Person AS ROOT TABLE
Each type in the hierarchy is created if they do not already exist. Should these types already exist, they must have the same definition in the target database as those defined in the source database. An SQL error is returned (SQL20013N) if they are not the same. Also, since we are creating a new hierarchy, none of the subtables defined in the data file being moved to the target database (Target_db) can exist. Each of the tables in the source database hierarchy is created. Finally, any data from the source database is imported into the correct subtables of the target database.
In a more complex example, we would like to export the entire hierarchy of the source database and import it to the target database. In addition, although we will export all of the data from the source database for those people in the database over the age of 20, we will only import selected data into the target database. The order of activity is as follows:
DB2 CONNECT TO Source_db
DB2 EXPORT TO entire_hierarchy.del OF DEL HIERARCHY (Person,
Employee, Manager, Architect, Student) WHERE Age>=20
DB2 CONNECT TO Target_db
DB2 IMPORT FROM entire_hierarchy.del OF DEL INSERT INTO (Person,
Employee(Salary), Architect) IN HIERARCHY (Person, Employee,
Manager, Architect, Student)
In this example, within the target database the Person, Employee, and Architect tables must all exist. Data is imported into the Person, Employee, and Architect subtables. That is, we will import:
Columns SerialNum nor REF(Employee_t) will not be imported into Employee or its subtables (that is, Architect, which is the only subtable having data imported into it).
| Note: | Because Architect is a subtable of Employee, and the only IMPORT column specified for Employee is Salary, Salary will also be the only Employee-specific column imported into Architect rows. That is, the SerialNum nor the REF(Employee_t) columns are not imported into either Employee or Architect rows. |
Data for the Manager and Student tables is not imported.
In a final example, we can export from a regular table and import as a single subtable in a hierarchy. The EXPORT command operates on a regular (non-typed) table, so there is no Type_id column in the data file. The modifier NO_TYPE_ID is used to indicate this to the IMPORT command so that IMPORT will not expect the first column to be the Type_id column. The order of the activity is as follows:
DB2 CONNECT TO Source_db
DB2 EXPORT TO Student_sub_table.del OF DEL SELECT * FROM
Regular_Student
DB2 CONNECT TO Target_db
DB2 IMPORT FROM Student_sub_table.del OF DEL METHOD P(1,2,3,5,4)
MODIFIED BY NO_TYPE_ID INSERT INTO HIERARCHY (Student)
In this example, within the target database the Student table must exist. Since Student is a subtable, the modifier NO_TYPE_ID is used to indicate there is no Type_id in the first column. However, you must ensure there is an Object_id column that exists in addition to all of the other attributes that exist in the Student table. And Object-id is expected to be the first column in each row imported into the Student table.
| Note: | The METHOD clause reverses the order of the last two attributes. |
See Command Reference for more information on the exporting and importing of data when working with typed tables in a hierarchical structure.
Replication allows you to copy data on a regular basis to multiple remote databases. If you need to have updates to a master database automatically copied to other databases, you can use the replication features of DB2 to specify what data should be copied, which database tables the data should be copied to, and how often the updates should be copied. The replication features in DB2 are a part of a larger IBM solution for replicating data in small and large enterprises--IBM Relational Data Replication (IBM Replication).
The IBM Replication tools are a set of IBM DataPropagator Relational (DPROPR) programs and DB2 Universal Database tools that copy data between distributed relational database management systems:
Based on the DPROPR V1 offering, IBM Replication tools allow you to copy data automatically between DB2 relational databases, as well as nonrelational and non-IBM databases.
You can use the IBM Replication tools to define, synchronize, automate, and manage copy operations from a single control point for data across your enterprise. The replication tools in DB2 Universal Database offer replication between relational databases only. The tool set manages the copying (replication) of data in a store-and-forward manner.
Replication allows you to give end-users and applications access to production data without putting extra load on the production database. You can copy the data to a database local to an end-user or application, rather than have them access the data remotely. A typical replication scenario involves a source table with copies in one or more remote databases, for example, a central bank and its local branches. A change occurs in the "master" or source database. At a predetermined time, an automatic update of all of the other DB2 relational databases takes place and all the changes are copied to the target database tables.
The replication tools allow you to customize the copy table structure. You can use SQL when copying to the target database to subset, aggregate, or otherwise enhance the data being copied. You can also create the copy tables structure to fit your needs: read-only copies that duplicate the source table, show data at a certain point in time, provide a history of changes, or stage data to be copied to additional target tables. Additionally, you can create read-write copies that can be updated by end-users or applications and have the changes replicated back to the master table. You can replicate views of source tables and views of copies. Event-driven replication is also possible.
The replication tools currently support DB2 on MVS/ESA, AS/400, AIX, OS/2, VM and VSE, Windows NT, HP, and the Solaris Operating environment. You can also replicate to non-IBM databases, such as Oracle, Microsoft SQL Server, and Lotus Notes.
There are two components of the IBM Replication tools solution: IBM DPROPR Capture and IBM DPROPR Apply. You can setup these two components with the DB2 Control Center. The operation of these two components, and the monitoring of them, happen outside of the Control Center.
The IBM DPROPR Capture program captures the changes from the source tables. A source table can be an external table containing SQL data from a file system or nonrelational database manager loaded outside DPROPR; an existing table in the database; or, a table that has previously been updated by the IBM DPROPR Apply program, which allows changes to be copied back to the source or to other target tables.
The changes are copied into a change data table, where they are stored until the target system is ready to copy them. The Apply program then takes the changes from the change data table and copies them to the target tables.
You use the Control Center to set up the replication environment, define source and target tables, specify the timing of the automated copying, specify SQL enhancements to the data, and define relationships between the source and the target tables.
For more information, see the DB2 Replication Guide and Reference, S95H-0999.