
The additional storage requirements associated with the introduction of replication into your system will arise in three areas:
If update copying is required, the database management system (DBMS) must log full row images for any update made to a table that has been selected for propagation. Additional log data is also generated when data is inserted or deleted from the unit-of-work (UOW) and change data (CD) tables in DB2.
It is not a straightforward calculation to estimate the increase that will be experienced in the log or journal volume. As a rule of thumb, it is recommended that the estimated increase be sized at three times the current log volume for the tables subject to replication.
A more detailed estimate requires detailed knowledge of the updating application and the replication requirements. If an updating application typically updates 60% of the columns in a table, the DATA CAPTURE CHANGES requirement will cause these log records to grow by more than half. Log records that would typically hold more or less of the row data would grow less or more, respectively. Several customers report a 60%-80% increase in the size of the update log records for the application tables that will be captured.
If only a small number of the columns are defined in the replication source, the inserts and deletes that are made to the CD table will cause small log records to be generated for these updates, whereas a replication source with all before and after images of the columns of a table will generate a larger log volume, as in the case of update-anywhere scenarios.
There will also be logging on the target database, where the rows are applied. Because the Apply program does not issue interim checkpoints, an estimate should be made for the maximum answer set of changed rows that will be handled by the Apply program, and the space for the logs should be allocated accordingly.
The estimates for this storage are also based on the source updating applications and the replication requirements. The tables that account for the most storage use in replication are the UOW table, the CD tables, and the target tables. Space requirements can be estimated for the target tables based on the source tables.
Space requirements for the CD tables can be estimated by first determining the "holding" period of the data. For example, if the Apply program is run once daily, with a "pruning" deletion of the applied rows from the CD table occurring once a day just after the Apply program, the base "holding" period would be 24 hours worth of updates. If the CD rows are 100 bytes long, and 100,000 updates are captured on an average day, the storage required for the CD table is about 10 MB. This is a sufficient approximation for initial storage requirement estimates. The CD table rows include 21 bytes of overhead data, in addition to the set of columns defined in the replication source.
The UOW table size is harder to estimate. The number of rows inserted in a day would equal the number of commits issued on transactions that update tables subject to replication. You should initially overestimate the size required and monitor the space actually used to see whether any space can be recovered. UOW table rows are fixed at 79 bytes long.
The space requirements for the IBM Replication control tables other than the UOW and CD tables are generally quite small. Most control tables require only a few rows, and default sizings are usually adequate.
The target table can be estimated by starting with the size of the source table, and then adding or subtracting changes to the target table from data transformation (adding columns), aggregating columns, or subsetting columns or rows.
The spill file used by the Apply program is equal to the size of the data selected for replication at each interval, including full refresh. (4) The spill file uses disk storage on every platform, or it can use virtual memory with Apply for MVS. The size of the answer set to be selected by the Apply program can be estimated by looking at the frequency interval planned for the Apply program, as compared to the volume of changes in that same time period, or in the peak period of change. For example, if change volume peaks at 12,000 updates per hour, and the Apply program frequency is planned at one-hour intervals, the one-hour interval will determine the average size of the spill file. In this case, the spill file must hold one-hour's worth of updates, or, 12,000 updates. The row size is the target row size, including any IBM Replication overhead columns. This row size will not be in DB2 packed internal format, but in expanded, interpreted character format, as fetched from the select. The row also includes a row length and null terminators on the individual column strings. Multiple spill files are used for replication subscriptions with multiple target tables; one spill file for each target table.
You may have a replication subscription with a large block of changes from one or more CD or CCD tables to be replicated in one Apply cycle. These large blocks can cause a backlog of queued transactions. They can also cause the spill file or log to overflow. Batch-Apply scenarios, for example, can produce a large backlog of queued transactions that need to be propagated (as is typical when the subscription runs only once a day or less). If a large block of change data accumulated in the CD tables due to an extensive Apply program outage, for example, breaking down the block of data prevents spill file overflows.
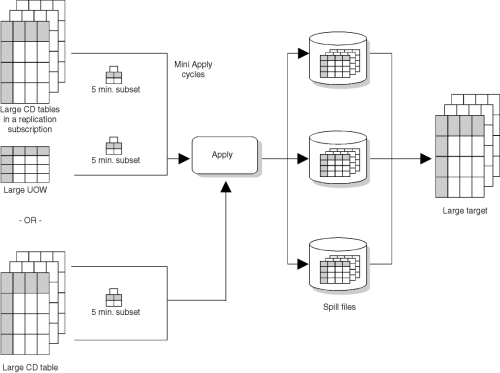
You can use the Data Blocking page of the Subscription Timing notebook to specify how many minutes worth of change data can move in a subscription cycle. The number of minutes you specify is used to determine the size of the data block. If the accumulation of change data is greater than the size of the data block, the Apply program converts a single subscription cycle into many mini-cycles, reducing the backlog to manageable pieces. It automatically retries three times, adapting to the work load level to copy in blocks that won't cause spill file or log overflow. To adapt the work load, the Apply program cuts the value in half to get the answer set size small enough to replicate successfully. If there is still a problem, it uses one-fourth of the value to align the changed data backlog with the available system resources. This reduces the stress on the network and DBMS resources and reduces the risk of failure. If a failure occurs during one of the mini-cycles, then only the failed mini-cycle needs to be redone. When the Apply program later retries the replication subscription, it will resume from the point following the last successful mini-cycle. Figure 6 shows how the changed data is broken down into subsets of changes.
Figure 6. Data Blocking Value. You can reduce the amount of data being replicated at a time by specifying a blocking value.
The data blocking minute default is NULL. This NULL default value will copy all committed data available, no matter how big or small. The number of minutes that you set should be small enough so that all the transactions for the replication subscription that occurred during the interval can be copied without causing the spill file to overflow or a log full condition. The space required for the spill files is the sum of the space required for each answer set in the replication subscription. The column MAX_SYNCH_MINUTES in the subscription set control table contains the value that you specify.
Restrictions:
The Capture program captures updates from the log file. When the log is full, its contents are archived on an archive log file. If the system handles a large number of transactions, the Capture program can occasionally lag behind. If the log is too small, some of the log records can be archived before they are captured. Archived log records cannot be recovered by Capture for MVS, VSE, and VM running with DB2 for MVS 3.1 or DB2 for VSE & VM 5.1. However, archived log records can be recovered by Capture for MVS running with DB2 for MVS 4.1 or higher, or the DB2 Universal Database V5.
If you are running on DB2 for MVS 3.1 or DB2 for VSE & VM 5.1, the size of your log should be large enough to handle at least 24 hours of transaction data.
All of these sizes are estimates only. To prepare and design a production-ready system, factors such as failure prevention must also be taken into account. For example, the holding period of data might need to be increased to account for potential line outage.
If storage estimates seem to be unreasonably high, the frequency interval of the Apply program and pruning should be reexamined. Trade-offs frequently must be considered between storage utilization, capacity for failure tolerance, and CPU overhead consumed.
(4) If you are using ASNLOAD, instead of a load spill file there will be a load input file.