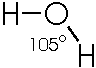 ,
, © Copyright 2001 Lawrence Chasin and Deborah Mowshowitz Department of Biological Sciences Columbia University New York, NY
Last updated Wednesday, September 07, 2011 07:21 PM
Bio C2005/F2401x Lec.2 L. Chasin September 8, 2011
1 multipage handout. Please bring handouts to subsequent classes
Recitations start next week. Look for recitation assignment lists and times on the Web site by Monday at noon. No quiz the first week.
Any questions on the mechanics of the course?
Outline:
Water:
Water
molecular structure used as a springboard to discuss all weak bonds:
Chemical bonds (5):
covalent (strong)
hydrogen (weak)
ionic (~weak)
hydrophobic (weak)
van der Waals (weak)
Organic acids and
bases
Macromolecules vs. small molecules
High molecular weight vs. low molecular
weight
Polymers vs. monomers
Biosynthetic pathways
Macromolecules: 1)
Polysaccharides
Monomers are
sugars; sugars are carbohydrates
Glucose
Ring formation
Chair form
Anomers: alpha and beta glucose
Glycosidic bonds
Disaccharides
Polysaccharides: cellulose and starch
Other sugars
We now start on the problem of how the bacterium E. coli reproduces, how it grows; how we get two E. coli cells from one.
It is this story that will make up much of this course. We will start with the simple and move to the more complex (as opposed to the opposite, also a valid approach). We will start with description and then move to process and function at each step.
First we need to know what are the chemicals that need to be made if we are to create one net E. coli cell. We need to turn to the nature of the chemicals that make up an E. coli cell, so we know what it is that we need to make in an hour.
(Water:
Most
abundant single molecule)
Let's start with the most abundant and most important molecule in the cell, not
an organic molecule, but water, H2O. We
will use our discussion of the water molecule as a springboard for introducing
different types of chemical bonds that are important in biology.
A more accurate representation than H20 would be: HOH, showing that each hydrogen atom is bonded to the oxygen atom.
Or H-O-H, where the dashes indicate covalent bonds, the sharing of electrons.
Or, showing the actual angle formed by the 2 bonds to H:
,
or, showing the sharing of electrons more explicitly:
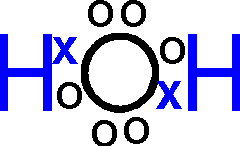
----------------------------------------------------------
We will use our discussion of water as a springboard to introduce weak chemical bonds that are important in biological structures.
A yet more accurate portrayal of water would be:
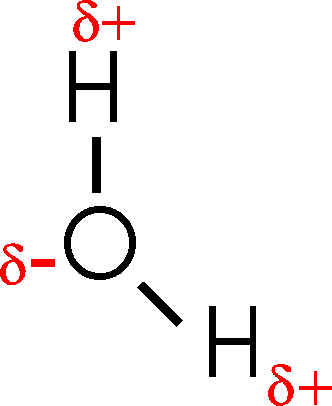
This configuration [Purves6ed 2.8] has important consequences, because although the electrons are indeed shared between the H's and the O, they are not shared equally. The oxygen nucleus is more electronegative than the hydrogen nucleus, that is, it attracts the shared electrons more strongly than the hydrogen nuclei. As a result, the O is slightly negatively charged and the H's are slightly positively charged.
The
![]() 's indicate a
partial charge, as opposed to a full charge. You'd get a full charge if the electron were
to be completely captured by one of the partners, resulting in the formation of
charged ions, as chlorine atom does in table salt (NaCl --> Na+ and
Cl-).
's indicate a
partial charge, as opposed to a full charge. You'd get a full charge if the electron were
to be completely captured by one of the partners, resulting in the formation of
charged ions, as chlorine atom does in table salt (NaCl --> Na+ and
Cl-).
So water is a polar molecule (one with a charge separation, one side is slightly negative and the other slightly positive), and this property has profound consequences for biological molecules. Because it has two poles, a positive side and a negative side, water is also sometimes called a dipole.
Water forms
hydrogen bonds
As a result of this polarity, each
water molecule can be attracted to another water molecule, depending on the
orientation. This attraction is very sensitive to orientation, being sharply
maximal when the O - H - O atoms are lined up:
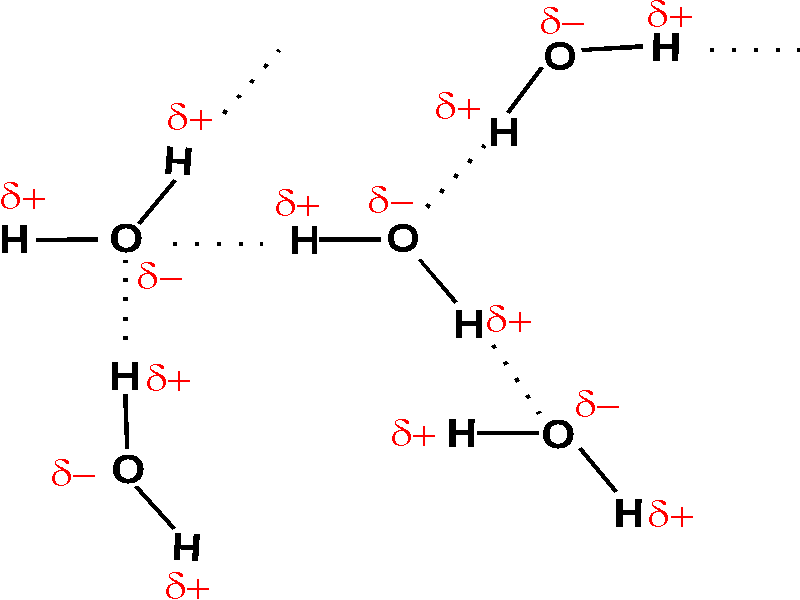
These connections between two molecules are called hydrogen bonds. Their strength is about 3 kcal/mole, thus they are weak bonds compared to the strong covalent bonds of ~100 kcal/mole. To chemically break covalent bonds by the thermal motion induced by heat, you would typically need hundreds of degrees (e.g., breaking oxygen-oxygen bonds when burning coal). In contrast, hydrogen bonds are readily disrupted at temperatures between freezing and boiling (0o - 100oC). In fact, freezing and boiling of water is a reflection of the hydrogen bonding: Gas = so much thermal motion that no hydrogen bonding is possible [Purves6ed 2-15c]; liquid = H-bonds are constantly forming, breaking, and re-forming [Purves6ed 2-16b]; solid = hydrogen bonds are locked in a stable crystal structure, which is ice [Purves6ed 2.16a].
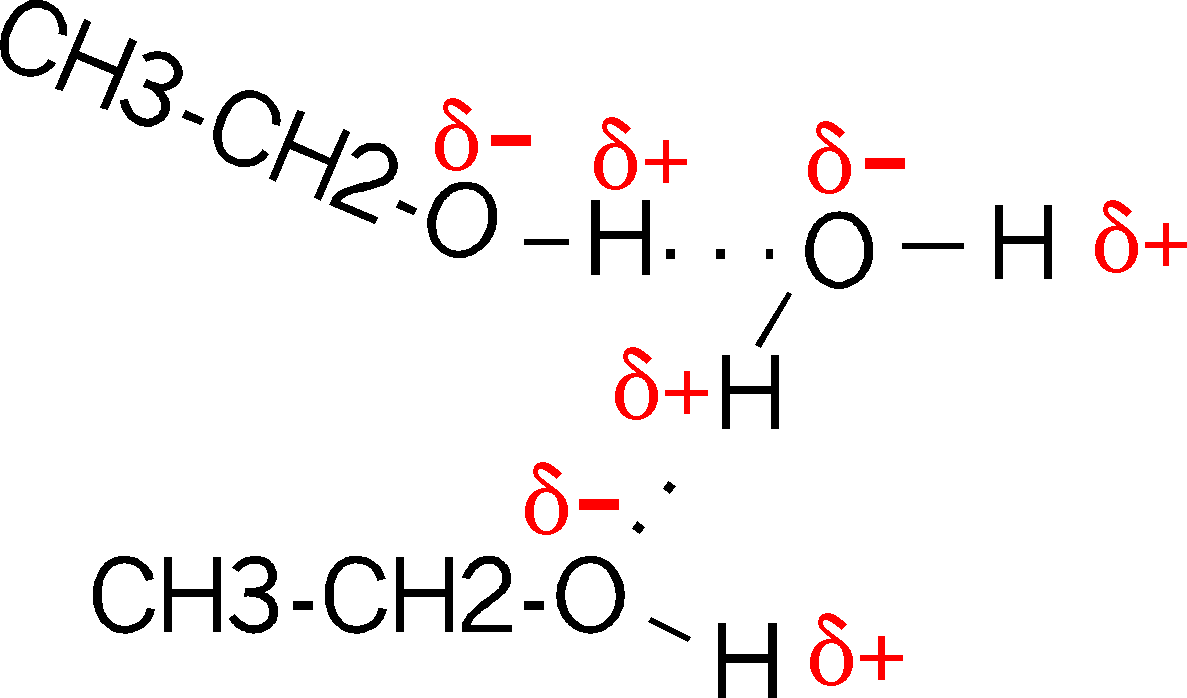
Are there H-bonds in compounds other than
water? Sure. Consider ethanol (alcohol), which has an hydroxyl group (-OH,
see
functional groups handout; we will be discussing almost all of these
functional groups at one time or other). Compare CH3-CH2-OH,
vs. ethane (CH3-CH3) which does not have this polar hydroxyl group. The hydroxyl
group is polar, for the same reason as in water. So it can H-bond to water when
it is in an aqueous solution (as most biological molecules are). It is for
this reason that most compounds with polar groups are very soluble in water.
That is, they are constantly forming these weak bonds to the water molecules.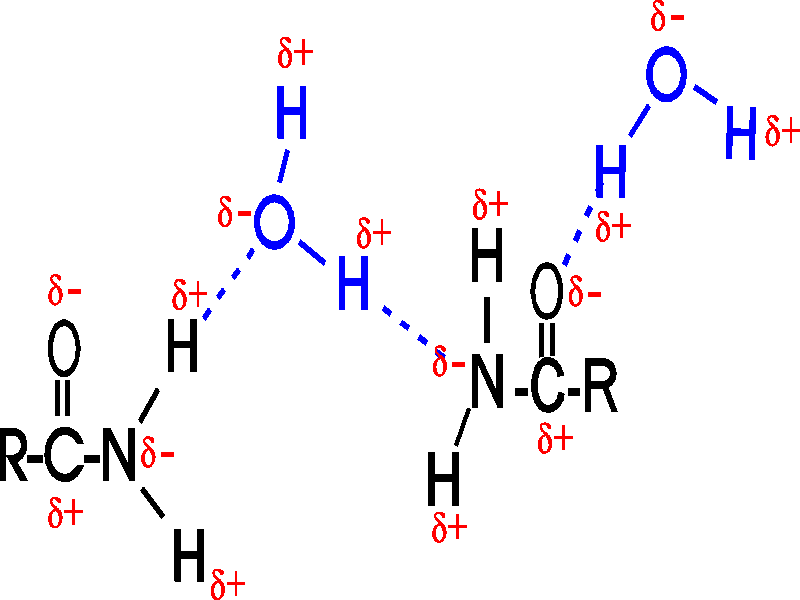
This is now the second organic molecule we have met. Note that carbon always forms 4 bonds.
And the H-bonds are not limited to oxygen in O-H groups: nitrogen is also more electronegative than hydrogen, as in an amide (-CO-NH2), and oxygen is more electronegative than carbon (as in the C=O part within the amide group):
("R" is shorthand for any general organic group, one that is not necessarily relevant for the discussion at hand.)
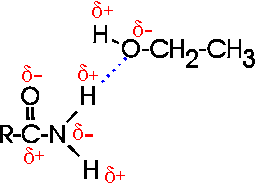 How about H-bonds between organic molecules?
Sure, if they can find each other: e.g., ethanol-acetamide, and the orientation
is important here, as with water. (If the amide in the diagram were acetamide,
the R would be CH3)
[Purves6ed 2.9].
How about H-bonds between organic molecules?
Sure, if they can find each other: e.g., ethanol-acetamide, and the orientation
is important here, as with water. (If the amide in the diagram were acetamide,
the R would be CH3)
[Purves6ed 2.9].
In aqueous solutions such interactions will always be competing with water molecules, which are usually much more abundant....
(Water molecular structure used as a springboard to discuss all weak bonds:)
Having introduced the subject of weak bonds, I want to now complete the discussion of bonds by introducing all of the bonds that play important roles in the behavior of biological molecules. There are five:
::Chemical bonds (5)
| Covalent | Hydrogen | Ionic | Van der Waals | Hydrophobic forces |
| ~100 kcal/mole | ~3 kcal/mole | ~ 5 kcal/mole | ~1 kcal/mole | ~3 kcal/mole |
| electrons shared | water-water | full charge transfer | fluctuating | not a bond per se |
| organic-water | can attract H-bond | induced dipole | entropy driven | |
| organic-organic | strong in dry crystal | at close range only | only works in water | |
| strong | weak, orientation sensitive | weak in water | weak | weak |
The weak bonds are going to be all-important for biochemical processes.
:: covalent (strong)
1.
covalent bonds: electrons shared between 2 atoms, strong [bond energy of ~ 100
kcal/mole] = energy needed to pull the 2 bonding atoms apart]
calorie: energy needed to heat 1 gram (1cc) of water 1 degree Centigrade
kilocalorie (kcal) = 1000 times 1 calorie
Calorie (with a capital C) = 1 kcal = dietary Calorie
:: hydrogen (weak)
2. hydrogen bonds:
water-water [~2-3 kcal/mole]
organic molecule - water
organic - organic molecule
orientation-dependent
{Q&A}
:: ionic (~weak)
3. Ionic bonds:
Full charge transfer; NaCl = strong in the dry crystal (need a hammer to break
it)
But ionic bonds are weak in water. Why? Water can H-bond to the charged ions: Na+ and Cl-. This process is called solvation [Purves6ed 2.11].
So, is this bond between water and the ion an H-bond or an ionic bond? Sort of half and half, = "polar interactions" or "ion-dipole interactions"). Maybe 4 kcal/mole.
--- 3A. Organic molecules can form ions too (acids and bases):
(Organic acids and
bases)
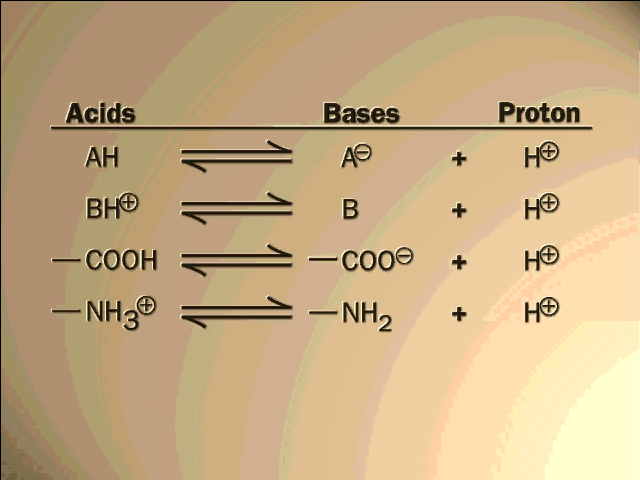
ACIDS: molecules that
are able to lose a proton (hydrogen ion) easily, such as a carboxyl group (a
carboxylic acid):
R-CO-OH ---> R-CO-O- (net charge = -1), + H+.
BASES: molecules that are able to take up a proton easily (protons being always around to some extent in water [ e.g., at 10-7M at pH7]), such as amines:
R-NH2 + H+ --> R-NH3+
Carboxylic acids will be almost the only organic acids and amines will be almost the only organic bases we will discuss this semester.
Acidity and basicity are measured by pH (= -log[H+]) [Purves6ed 2.18]
Under the right conditions, ionic bonds can form between two organic ions, with a bond strength of about 5 kcal/mole (in water):

Where are we going with all this chemistry, and these weak bonds? We started describing the molecules of E. coli, with the idea that we have to know what we have, in order to know what we have to make, to replicate an E. coli cell. The weak bonds I am cataloging for you now show how these molecules can interact - but as we proceed to consider larger and larger molecules, they will help us to understand the structure of the individual large molecules, such as proteins and DNA. So this is more than just a listing, the weak bonds will be very important, as we will see in the next few lectures.
::
van der Waals (weak)
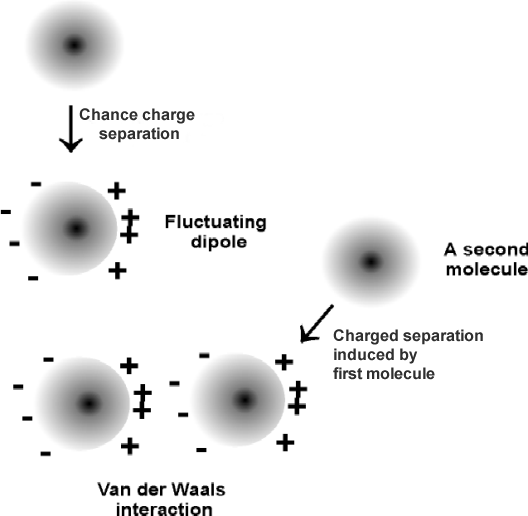
4. Van der Waals
bonds: Exist between any 2 molecules
Only effective at very close range (e.g., 0.1 nm, or 1A).
Fluctuating induced dipole. Fluctuating, induced, dipole.
~1 kcal/mole.
These are the weakest of the bonds we'll
discuss, about 1 kcal/mole, but they are able to form between any
two molecules.
Van
der Waals interactions form between fluctuating induced dipoles. Take for
example two methane molecules (CH4) , where the C and H have about the same electronegativity, so there is no intrinsic charge separation. A momentary
negative charge can develop in the electron distribution around one of these
atoms, and this charge will induce the opposite charge in a nearby atom's
electron cloud. These bonds are only effective at extremely short range (~
"touching"). Indeed, the size of an atom in space is often estimated by its "van
der Waals radius." (Closest approach before repulsion between nuclei sets in).
:: hydrophobic (weak)
5.
Hydrophobic interactions ("bonds")
Not really bonds, but often referred to as such.
Caused by the effects of water on the association of other molecules.
Non-polar (apolar) molecules are unable to form H-bonds with water.
E.g., octane, CH3-(CH2)6-CH3 (~= gasoline)
Water molecules surrounding an apolar molecule take on a relatively ordered structure compared to the constantly switching H-bonding patterns made with other water molecules.
This ordered "cage" structure is minimized by interfacing the apolar molecules with each other:

Systems will change so as to maximize entropy (number of different states that can be occupied). Even though the octane molecules are more ordered when aggregated, the increase in disorder of the water molecules that become freed from the cage structure is so great that the entropy of the system is greater with the octane molecules coalesced. This increase in entropy provides a hydrophobic force equivalent to about 2-3 kcal/mole (per mole of octane, in this case).
The actual bonds between the octane molecules in a coalesced glob in water are just the van der Waals bonds.
This state of affairs is not intuitively obvious.
The bottom line is that apolar groups will tend to associate with other apolar groups in aqueous solutions. Click here for another view of hydrophobic interactions. [methane] [watercage]. These hydrophobic interactions are of paramount importance in biology, as they are responsible for the integrity of the cell membrane, for example, as we shall see. Thus the very definition of a cell depends on these forces.
This finishes our introduction to the chemical bonds that will be important in our consideration of biological molecules.
Let's get back to the chemical make-up of an E. coli cell: Water was molecule #1.
(Macromolecules
vs. small molecules: High molecular weight vs. low
molecular weight)
We have about 5000 more
different molecules to consider. Before proceeding to #2, let's place all molecules
into 2 classes:
1) small; and 2) large.
Small ~< 500 daltons, (or molecular weight
units), corresponding to ~< 50 atoms; Large ~> 5000 daltons (~500 atoms).
These molecular weight distinctions are not sharp boundaries, just a rough gauge.
The large molecules are usually called macromolecules. The small molecules are just called small molecules.
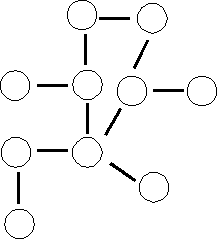 Small = e.g., a molecule like propylene, a synthetic organic chemical:
CH3-CH=CH2. What is a large version of this small molecule? It is not
like the picture on the left (where each circle represents propylene):
Small = e.g., a molecule like propylene, a synthetic organic chemical:
CH3-CH=CH2. What is a large version of this small molecule? It is not
like the picture on the left (where each circle represents propylene):
( Incorrect picture)
Rather, polypropylene, a familiar plastic, is a linear polymer of propylene: O-O-O-O-O-O-O-O-O-O-O-.
(Polymers vs. monomers)
Virtually all of the biological
macromolecules are built this same way: they are linear
polymers of small molecules. This simplifies matters greatly.
Nomenclature: Monomers --> di-mers (two small molecules linked together covalently) --> tri-mers --> tetramers, etc. .--> oligo-mers (moderate numbers of repeating units), --> poly-mers (lots of repeating units).
The monomers could be all the same, as in certain polysaccharides like cellulose (glucose (n)) or they could be different, the extreme example being proteins, where there is a mixture of 20 different monomers present.
While this greatly simplifies our consideration of these large molecules, there is plenty of complexity left.
Some of the important small molecules in the cell are these monomers, the basic building blocks of the biological polymers. The polymers, or macromolecules, comprise 4 classes:
polysaccharides,
lipids,
nucleic acids, and
proteins.
The total number of such monomers is about 50..... Pretty simple...
Now there are about 15 or so other small molecules that serve other functions (they are not monomers that will end up in polymers). These are co-factors that are important in the catalysis of chemical reactions in the cells ( ~ vitamins). So this brings us to ~65 different small molecules so far.
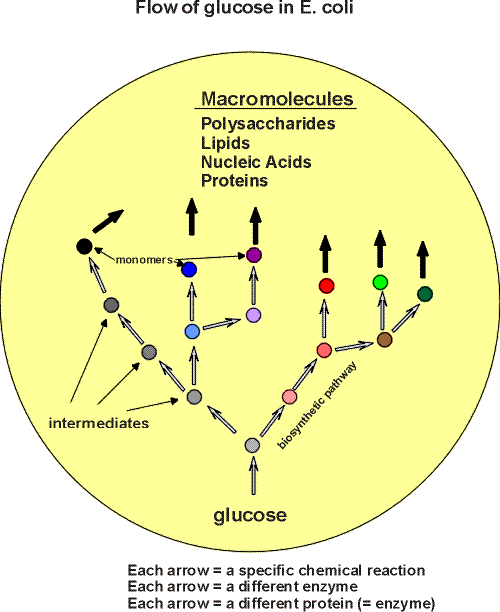
Then, necessary but less generally important, are the "intermediates". All the carbon in E. coli can flow from glucose via biochemical pathways (see flow handout for overview):
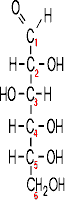
This is what glucose looks like :
For instance, This is what one of the monomers
of a protein looks like (this one an amino acid called alanine) :
These molecules are quite different. In the cell, a molecule of glucose
is converted, through a series of chemical transformations into the product,
(here, alanine), a monomer for building proteins. Intermediate types of
molecules are created along the way on this pathway (a metabolic pathway). In
general, 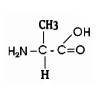
glucose --> A --> B --> C --> D --> E --> monomer --> polymer
[A, B, C, D, and E here are the intermediates.]
These pathways are of various lengths. If we take 10 as a generous estimate of the intermediate steps in an average pathway, then we get another 585 (i.e., 9 x 65) different small molecules to add to our total in the E. coli cells. So our final number of small molecules is about 650. Not too great a number to master. Almost all are known. We will get to know the majority of the end-products, the monomers, as well as a few of the intermediates.
We will continue our discussion of the molecules of E. coli by focusing on the polymers - the monomers will be considered in the context of the macromolecules of which they are a part.
A simple overview of the kinds of molecules in the cell, then, is (Handout):
(POLYSACCHARIDES)
(Monomers are sugars; sugars are carbohydrates)
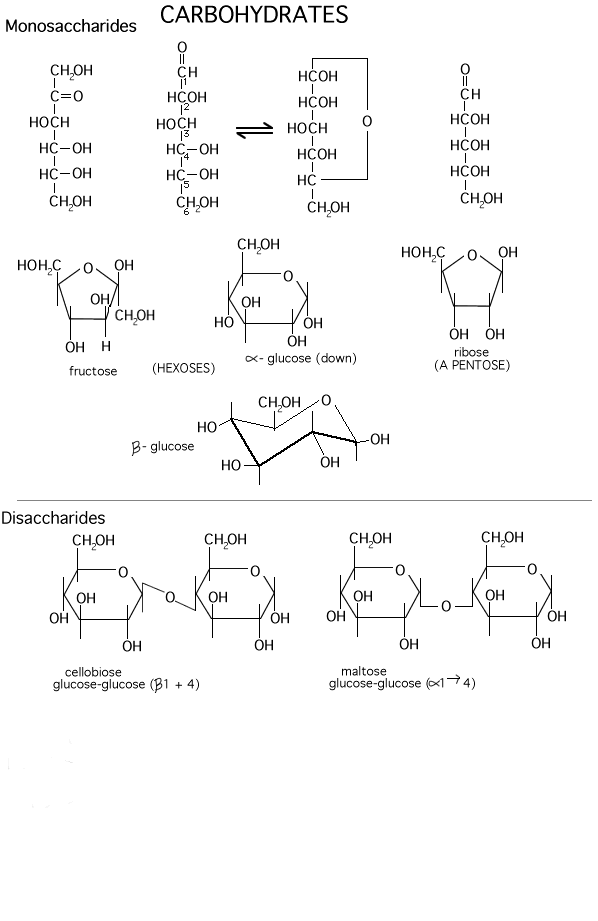
So let's go to our first macromolecule class, POLYSACCHARIDES: The MONOMERS here are SUGARS. Most common is glucose (also called dextrose). Let's look at the structure of this hexose (a sugar with 6 carbon atoms):
(Glucose)
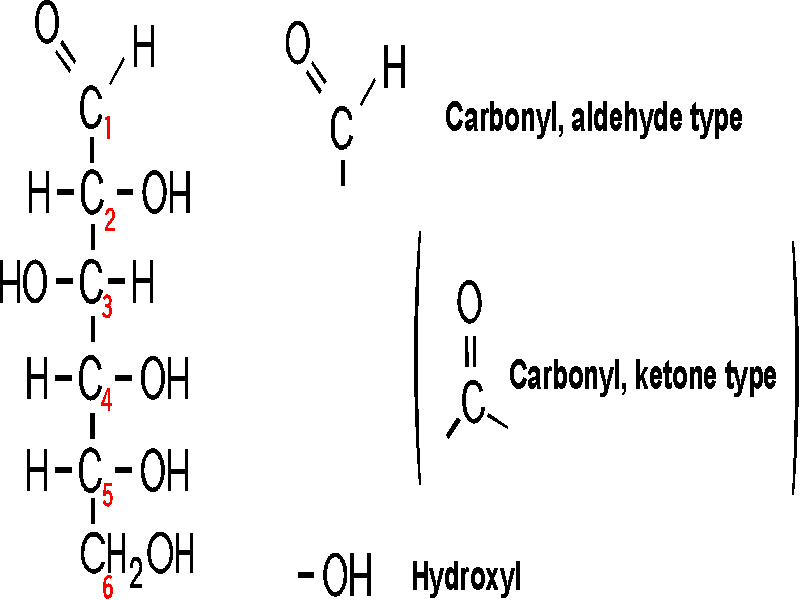
Note the functional groups here: a carbonyl
(aldehyde or ketone) and a bunch of hydroxyls. Is it hydrophilic or hydrophobic?
And so is it very soluble in water? (yes, like sucrose, table sugar). Note the
numbering system, so we can talk about the various carbons in the chain.
Numbering usually begins at the end closest to the carbon that has the least
number of hydrogens or most oxygens. Sugars are
carbohydrates, with a general formula of CnH2nOn;
the term refers to carbon compounds with many hydroxyls and a carbonyl (C=O)
group.
Compare the diagram drawn on the left here with that on theroght to note some organic chemistry shorthand. Since carbon is so common in organic compounds and always takes four bonds, we can simply leave it out, with the understanding that a carbon atom is present at the vertex of 2 or more bonds. Similarly, we can adopt the convention of leaving out the hydrogens, which form only a single bond: thus a bond line with nothing appended to it means that there is a hydrogen there at this level of abbreviation .
(Ring formation)
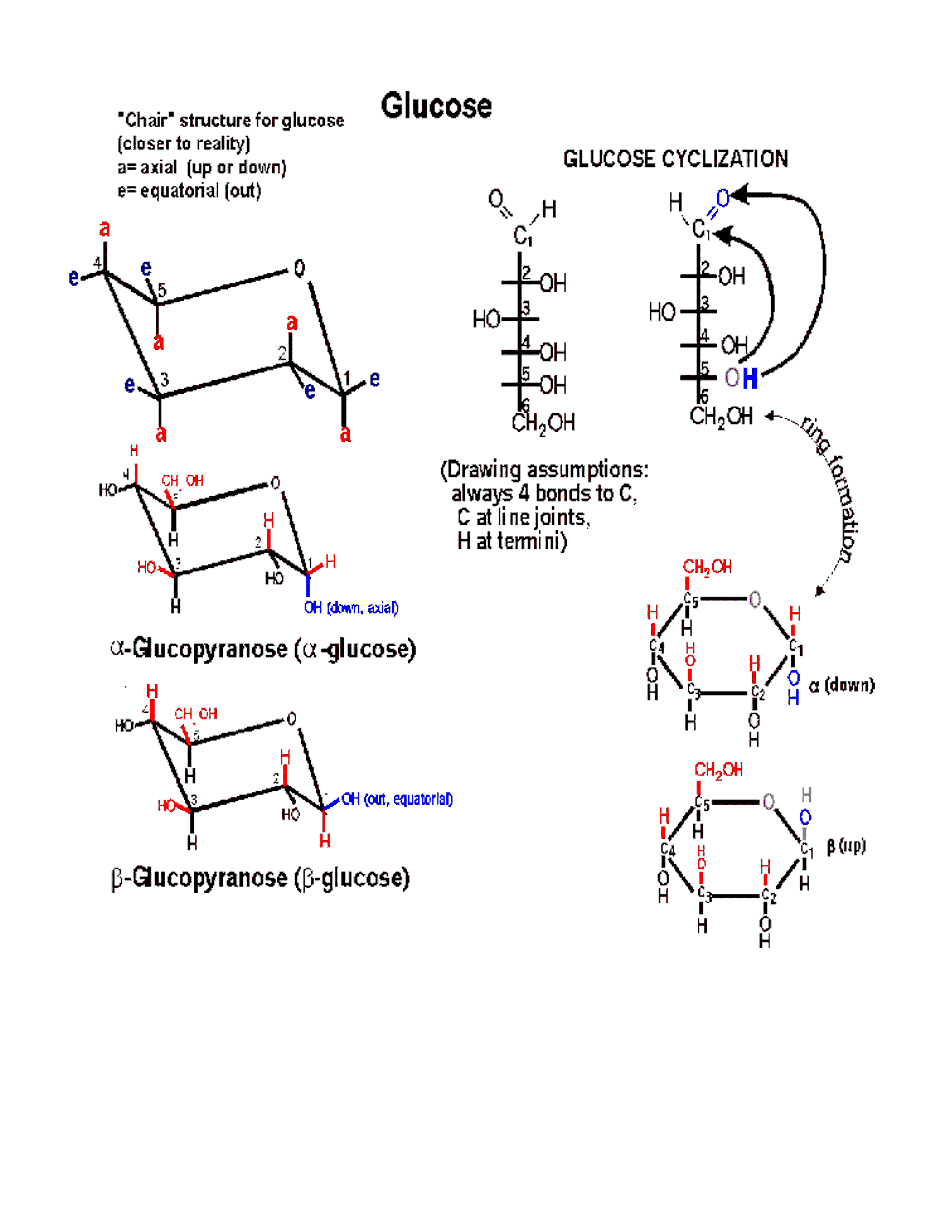
In 3-dimensional space, a hexose chain can
easily curl up, such that the oxygen attached to carbon 5 can be juxtaposed next
to carbon 1. A 6-membered ring forms preferentially in
water, by attack of the hydroxyl of carbon-5 (C5) on the carbonyl double bond at
C1. One bond of the carbonyl double bond opens up and forms a new bond between
carbon-1 with the O of C5. The H leaves C5 and a new OH group is formed on
carbon 1. Follow along with the diagram on the
glucose handout, So a 6-membered ring is formed, with O
as one of its members (one of the vertices). One carbon (C6) is left
sticking out away from the ring. Unlike most biochemical reactions, which
require a catalyst to help them take place at a reasonable rate (more on this in
a week or so), this intramolecular cyclization reaction takes place all on its
own, as soon as a sugar is put into a water (aqueous) solution. This
reaction is rapid because the players can't help but keep bumping into each other
as the glucose chain of carbons dances in thermal motion. The ring
structure can also open up, re-forming the straight chain. The 2 forms are
in a dynamic equilibrium, but because the ring form is more stable, this species
predominates in water.
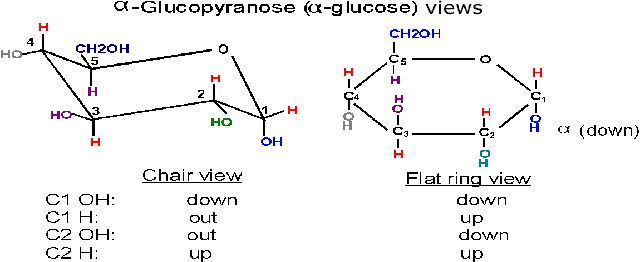
(Anomers: alpha and
beta glucose)
Now, when the O attached to C5 approaches
the carbon C1 which has the carbonyl double bond, it can do so from one side or
from the other side. Depending on which side is attacked, the resulting ring
comes out looking different in 3-dimensional-space, because the OH formed from
the carbonyl oxygen is oriented distinctively in the 2 cases. That is, the
resulting ring can be of
two different conformations in space. The two conformations are formed
at about equal frequencies. The 2 conformations are called alpha and beta:
Alpha, where the
C1 OH that is formed ends up BELOW* the C1 hydrogen,
or
Beta, where the C1 OH that is formed ends up ABOVE*
the C1 hydrogen (see
glucose handout, right side. See also a picture [Purves 3.11]).
And animation: http://www.stolaf.edu/people/giannini/flashanimat/carbohydrates/glucose.swf
In sugars, carbonyl carbons that can switch the
side of their hydroxyl groups when cyclized are called anomeric
carbons, and the two resulting sugars (alpha and beta forms) are called
anomers. See sugars
[Purves 3.11], and more sugars
[Purves 3.12b][Purves 3.12a].
{Q&A}
{Q&A}
(Chair form)
The ring is actually not flat, but puckered into a reclining chair-like shape,
but hard to draw: (see
flat vs. puckered) - - -in this chair-view the hydrogens and the
hydroxyls can be seen to be not really up or down, but are rather either
axial (vertical, sticking up OR down) or equatorial
(horizontal, sticking out).
Note in glucose all the hydroxyls are equatorial except that of the #1 carbon in the alpha conformation. In beta-glucose this - OH is upper, relative to the hydrogen, and in fact equatorial; but in alpha-glucose it is lower (relative to the hydrogen) and axial (and down).
The formation and structure of these ring forms of glucose is treated much more extensively in the live lecture, as can be appreciated from viewing the PowerPoint of this lecture.
The existence of these two seemingly very similar 3-dimensional structures for glucose can have important effects on the 3-dimensional structure of polysaccharides made from these glucose monomers, which in turn can determine the function of the polysaccharide, as we will see.
Glycosidic bonds)
As we consider a polymer built from glucose
monomers, we can first consider a dimer. Two glucose monomers can be connected
to form a DIMER. This connection, WHICH DOES NOT HAPPEN BY ITSELF (i.e., without
some help from a catalyst), involves a dehydration, the removal
of one molecule of water, from the 2 monomers:
2 monomers ----------------------> dimer
R-OH + R-OH ---------> R-O-R + HOH
This type of reaction is also referred to as a CONDENSATION, as it condenses two molecules into one. Such dehydrations/condensations are a common way in which monomers are linked up into polymers in biological macromolecules.
The resulting -C-O-C- bond is called a glycosidic bond when it is connecting two sugars.
Conversely, the breakdown of polymers back to their constituent monomers involves the reversal of this chemistry, the addition of water, or hydrolysis (the products = a hydrolysate).
R-O-R + HOH ------> R-OH + R-OH
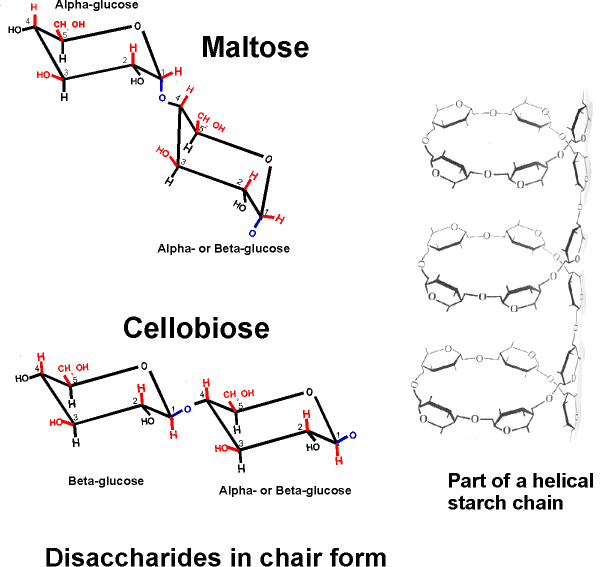
Both of these reactions require different catalysts in the cell in order to occur, which is generally true for all the biochemical reactions we will discuss. See the Carbohydrates handout, below the line for a depiction of two dimers in the flat ring forms. Note the 1-4 linkage (C6 sticks out of the ring, so that is one way to figure out the numbering in the ring). Although the bonds are presented as bent at right angles, they are not really so, it is just a way of presenting both sugar monomers right side up and still connect them with a glycosidic bond that maintains the information about the orientation of the bonds relative to the ring.
There are several different hexoses in most cells. Fructose, galactose, and mannose are some common ones. Differences lie in the positions of the carbonyl along the chain and relative positions of the hydroxyls in space. Fructose has a ketone carbonyl at C2, and cyclizes to form a 5-membered ring (still with one member oxygen of course, so 2 C's stick out from the ring (Carbohydrates handout).
And there are several common disaccharides (see Becker):
Glucose-glucose via a 1-4 alpha-link is maltose, where alpha refers to the state of the -OH in the monomer joined at its C1 carbon [Purves 3.13a]. Maltose is formed as you digest bread.
Galactose + glucose [Purves 3.12] via a 1-4 beta-link is lactose (in milk) ,
Glucose + fructose [Purves 3.12] via a 1-2 alpha-beta link is sucrose (table sugar).
But these are not yet polymers, or macromolecules.
These dehydrations can continue in many cases in a repeated way to form chains that contains 1000's of monomers:
X--1,4--X--1,4--X--1,4--X--.........(where X represents a sugar ring)
To be sure you understand disaccharides, try Problem 1-8C and 1-9 D & E.
Starch and cellulose:
function follows form)
A poly-glucose of this type is
CELLULOSE, which contains exclusively glucose
molecules in beta linkages The beta linkage results in a pretty straight
connection between the C1 and C4 of adjoining carbon atoms, since they both are
equatorial and so are sticking out, as can be seen on
handout 2-9, disaccharides in chair form. Thus a cellulose chain extends
straight with its C6 OHs sticking out from the chain on either side.
[Purves 3.14a1] Many cellulose molecules can then associate side by side
(via hydrogen-bonds to each other) to form a fiber of great strength (e.g., in
cotton, and it also contributes to rigidity of wood )
[Purves 3.14b] [TINKER TOY demo]. Cellulose is the most abundant carbon
compound in the biosphere, accounting for about half of all such carbon.
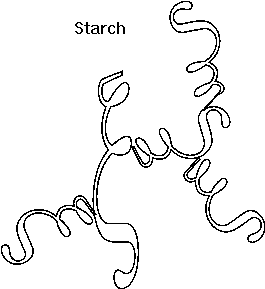
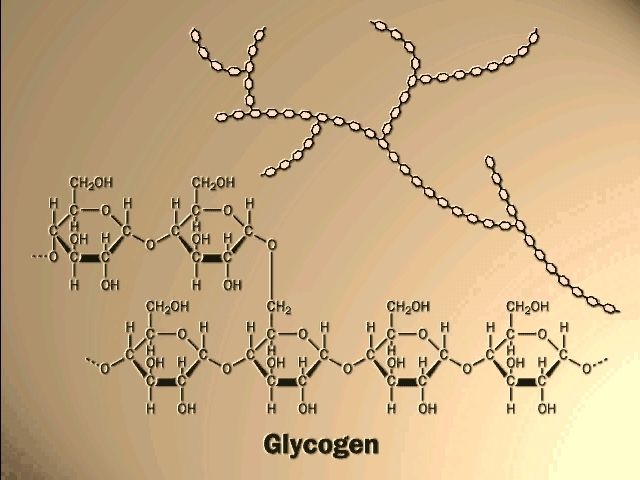
If glucose molecules are put together with an alpha 1,4 link instead of beta, then a polymer of a different shape results. Here, the C1 -OH is axial whereas the C4 -OH in glucose is (always is, by definition in "glucose") equatorial. The angle of this alpha 1,4 bond is such that the polymer bends at each glycosidic connecting bond, as can bee seen in handout 2-9, disaccharides in chair form. As a result, it takes on a helical shape that again allows lots of hydrogen bonding between glucoses in each turn of the helix, thus stabilizing the polymer in this shape. [TINKER TOY demo]. Such is the case with STARCH, which consists of alpha-glucose molecules joined in 1,4 linkages. In addition, starch has branches [Purves 3.14b] made by linking additional glucose molecules at the C6 OH of some of the glucose residues in the chain, via an alpha 1,6 bond). The branch continues with alpha 1,4 linkages (see Becker for picture). The length and frequency of the side chains give rise to the different forms of starch (potatoes, corn) or of a starch like polymer found in mammalian muscles and liver, GLYCOGEN (and see [Purves 3.14a2] . These polymers act as storage forms for glucose. When glucose is needed, they can be hydrolyzed (adding water back to the bond between the monomers) to regenerate the free monomer. Glycogen is more highly branched than starch, and its breakdown from the many ends so produced leads to rapid mobilization of the glucose moieties within it, a property more important in animals than plants. {Q&A}.
Here is our first good example of an important theme in biochemistry, the relationship between structure and function at the molecular level. The straight linear structure of cellulose made possible by the beta-linkages allows the assembly of thousands of aligned molecules to produce a cellulose fiber of great tensile strength. The alpha-linkage in starch produces a compact structure, not strong, which serves as a storehouse of glucose for energy when needed.
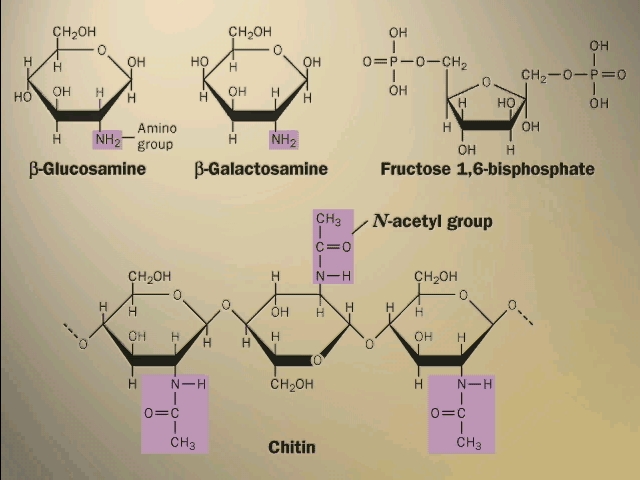
Your texts have additional examples of important polysaccharides. Some of the sugars have nitrogen-containing groups appended to the basic carbohydrate ring. The rigid bacterial cell wall is another example, like cellulose, of a polysaccharide used for structural support. So is the shell, or exoskeleton, of insects (CHITIN) [Purves 3.15c].
To go over the structure of polysaccharides, try problem 1-11. If you need more review, try 1-25.
The PowerPoint for this lecture has several additional diagrams that you may find useful.
© Copyright 2011 Lawrence Chasin and Deborah Mowshowitz Department of Biological Sciences Columbia University New York, NY

![[Purves6ed 2.8]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure02-08.jpg){kind=link}
![[Purves6ed 2-15c]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure02-15c.jpg){kind=link}
![[Purves6ed 2-16b]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure02-15b.jpg){kind=link}
![[Purves6ed 2.16a]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure02-15a.jpg){kind=link}
![[Purves6ed 2.11]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure02-11.jpg){kind=link}
{kind=link}
![[Purves6ed 2.18]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure02-18.jpg){kind=link}
![[methane]](http://www.columbia.edu/cu/biology/courses/c2005/images/watermethane.gif){kind=link}
![[watercage]](http://www.columbia.edu/cu/biology/courses/c2005/images/watercage.jpg){kind=link}
{kind=link}
![[Purves 3.11]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure03-11.jpg){kind=link}
![[Purves 3.12b][Purves 3.12a]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure03-12a.jpg){kind=link}
{kind=link}
{kind=link}
![[Purves 3.13a]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure03-13a.jpg){kind=link}
![[Purves 3.12]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure03-12b.jpg){kind=link}
{kind=link}
![[Purves 3.14a1]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure03-14a-1.jpg){kind=link}
![[Purves 3.14b]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure03-14b.jpg){kind=link}
{kind=link}
![[Purves 3.14a2]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure03-14a-2.jpg){kind=link}
{kind=link}
![[Purves 3.15c]](http://www.columbia.edu/cu/biology/courses/c2005/purves6/figure03-15c.jpg){kind=link}