{kind=link}
{kind=link}
C2005/F2401 2008 NOTES FOR LECTURE 11 Last Updated 10/08/08
© Copyright 2008 Deborah Mowshowitz and Lawrence Chasin , Department of Biological Sciences , Columbia University , New York, NY
Handouts: 11-1 -- Meselson-Stahl Experiment (not on web); 11-2 -- Synthesis of DNA -- Where the Energy Comes From; 11-3 -- DNA Replication - Details at Fork.
References to the texts are to Sadava 8th ed. & Becker 7th edition. References to 7th or 6th ed. of Purves/Sadava or 6th ed. of Becker are in parentheses if they are different.
For nice animations of the Meselson-Stahl experiment and DNA replication (including primers -- to be discussed next time) go to
http://highered.mcgraw-hill.com/sites/0072437316/student_view0/chapter14/animations.html#
These animations (& your texts) may mention enzymes not discussed in class; you are not responsible for the extra details. A box with the animation should appear on the upper left when you click on the appropriate link. If nothing happens when you click on the link, the box may be behind the page you are looking at. Shrink the main page to see the animation.
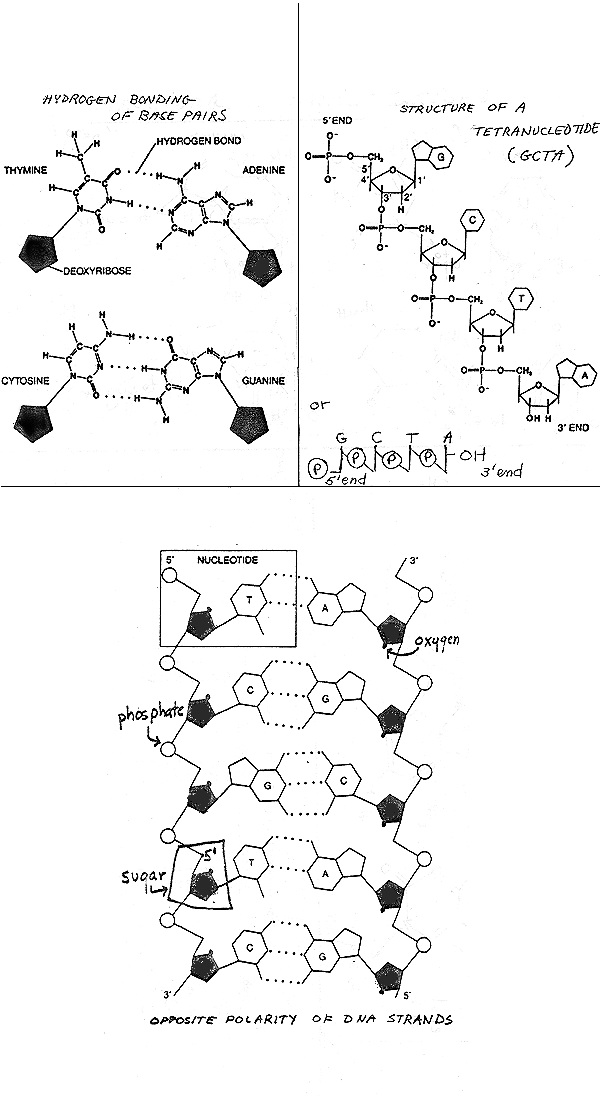
I. DNA structure, cont. A few more points.A. How are the two strands paired up? Parallel or antiparallel? The two chains of DNA could be parallel or anti-parallel as shown by pop bead model or as follows:
anti-parallel
parallel
5' AGC......TTA3'
5' AGC......TTA3'
3' TCG......AAT5'
5' TCG......AAT3'
The two strands of DNA are actually anti-parallel, which is why the two ends of the double stranded molecule are equivalent -- the overall structure or shape of the helix is the same if you turn it upside down, as indicated by the X ray data. (Of course the sequence of base pairs is different if you invert the molecule.) So each double stranded molecule has two chains running in opposite directions, and this makes for complications when we get to replication.
Anti-parallel lineup of the 2 strands is shown on p. 3 of handout 10-3 (from last time), or fig. 3-18 or 18-4 of Becker, or Sadava 11.9 (11.7). On handout 10-3, chain on left runs "down" 5' to 3'. Chain on right runs "up" 5' to 3'. The individual sugar-phosphate connections on the two chains are visibly different. The 1' on sugar always connects to base a little above sugar. But look at 5' position = bend in sugar-phosphate connection (on handout). Bend is just below sugar on right chain and just above sugar on left chain. Each chain has direction but double helix doesn't. Fits with X ray data, but has serious implications when you consider the fine points of DNA replication.
B. Base stacking To see how bases are flat and stacked on top of each other see Becker fig 3-19, Sadava 11.8 (11.6), or model in class.
Base stacking can be called a Van der Waals or a hydrophobic interaction = weak interactions between flat nucleotide rings that are stacked on top of each other in double helix. Helps hold helix together along its length, as opposed to H bonds between the bases, which hold it together across its width.
C. What does the final structure look like? The famous double helix. DNA Molecule - Two Views (Consult your text and/or handouts for additional pictures and details. Alternatively, go to Google, select images, and enter 'DNA'.) See Sadava, fig. 3-27 (3-29) & 11.8 (11.6) or Becker fig. 3-9 or 18-4.
D. Super coiling.
DNA double helix is folded back on itself like a kinked telephone cord -- this is called super coiling. Corresponds to a tertiary structure (if double helix is secondary, in parallel to proteins). This means DNA must be unfolded extensively before it can be duplicated or read out to make proteins. We will ignore how this is done; if you are interested, some details of proteins required for folding and unfolding are in texts.
Some numbers to illustrate the need for supercoiling:
Length of E coli DNA = 3 X 106 base pairs (bp or BP); how long is that?
4 Angstroms (A) per bp, so length in A = 12 X 106 A
Length in meters = 10-10 m/A X 12 X 106 A = 12 X 10-4 m = 1.2 mm = 1 pinhead
But 200,000 E. coli can fit on the head of a pin! Or about 600 E. coli lined up the long way can go across the pin. So there must be higher orders of folding to allow the DNA to fit inside E. coli. {Q&A}.
How DNA is folded up with proteins (histones) in eukaryotic chromosomes will be discussed next term.
II. "Non genetical"
implications of DNA structure
A. Denaturation
1. Double Stranded DNA can be separated into its single strands
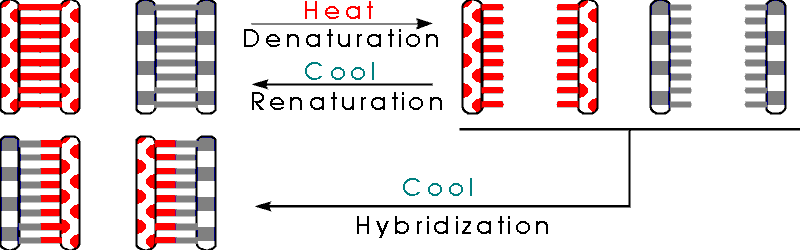
Since the 2 strands of DNA are held together entirely by weak bonds, you can take double stranded DNA apart into single strands by heating the DNA. This is called denaturation by analogy with proteins -- heating proteins or DNA unfolds the molecule and makes it lose its functional shape.
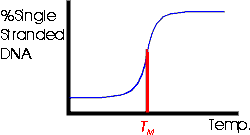
2. Tm -- Melting Temperature
If you heat a particular DNA up, it denatures abruptly at a specific temperature as shown in the picture below and Becker fig. 18-8. The temperature at which the DNA denatures, or unzips or "melts" is called the Tm for melting temperature. The Tm is proportional to the % G-C (= %G + %C) in the molecule. This is because each G-C base pair is held together by 3 hydrogen bonds (not by a triple bond, but by 3 separate H bonds) while each A-T base pair is held together by only 2 H bonds. (See handout 10-3, top left.) So the more G-C the DNA has, the more H bonds there are to hold the two strands together and the more you have to heat the DNA up to denature it.
The way you figure out the entire base composition (%A, G, C, & T) of a DNA is to heat it up and measure its Tm. From the Tm (compared to that of a standard DNA) you get the % G + C in the DNA. Once you have the % G + C, you can calculate the rest since G = C, A = T and G + C + A + T = 100%.
To review denaturation, do Problem 6-4, parts A-C.
B. Renaturation -- if you cool denatured DNA down, it will renature or reform a double helix. As you cool the single stranded denatured DNA, the bases in the complementary single strands match up again, and the single strands reform a double helix. See Becker fig. 18-10.
C. Hybridization -- If you want to know if 2 DNA's are the same, you can find out by denaturing them, mixing the denatured strands, and cooling down the mixture. If the 2 DNA's are identical, then a single strand (say a "Watson") from one DNA can match up with a complementary single strand (say a "Crick") from the other and you can form a hybrid molecule. This is called hybridization since you match up complementary strands from 2 separate molecules to form a hybrid molecule. Variations on this procedure are used to:
Test for similarities between 2 DNA's -- by the extent of base pairing in the hybrids. Hybrids can form between similar, but nonidentical DNAs under appropriate conditions. (Under other, more strict, conditions, only identical DNA's will hybridize successfully.) If the DNA's are similar enough, some, but not all, of the bases will match up and form base pairs. If a few base pairs do not match, but most do, the strands can still form enough H bonds to hold the hybrid together. (How will you measure the proportion of bases that are not paired up?)
Determine the concentrations of various DNA's -- by the rate of renaturation/hybridization. Sequences at higher concentration will find partners and renature more quickly. (For an example, FYI, see Becker fig. 18-15.)
Detect specific DNA sequences -- by their ability to hybridize to test DNA's [called probes] that are radioactive or labeled in some other way. You denature the DNA you want to analyze, and add the (single stranded) probe. If the two DNA's form a hybrid (as detected by binding of probe) you known the "unknown" contained a sequence complementary to the probe.
Some examples of the uses of hybridization will be discussed in class as they come up.
To review renaturation/hybridization, try problem 6-4, part D.
III. The Meselson-Stahl experiment.
Does DNA replicate as implied by the Watson-Crick Model?
A. Possible modes of DNA replication. See picture below & handout 11-1. Also See Sadava chap. 11 or Becker 19-3 (19-3 & 19-4).
1. Semi-conservative replication.
The obvious possibility is that DNA really comes apart into single strands and each strand then serves as template to re-create the missing strand (as implied by the Watson-Crick structure and discussed last time). In this case each of the 2 resulting daughter molecules has one old strand and one new strand; this is called semi-conservative replication. (See Becker fig. 19-2).
2. Other possibilities -- conservative and dispersive replication.
There are (at least) 2 other possibilities:
DNA could replicate without coming apart and the daughter molecules
would then consist of one completely old molecule with 2 old strands, and one completely
new molecule with 2 new strands; this is called conservative replication.
The third
possibility is that pieces of old and new could be scrambled in some way so that each
daughter molecule would have new sections and old sections in each individual strand; this
is called dispersive replication.
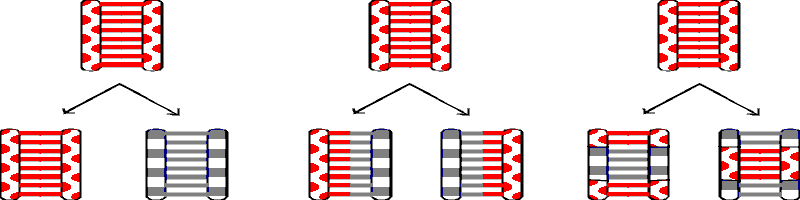
|
<Conservative> |
<Semi Conservative> |
<Dispersive> |
B. The M-S experiment -- first generation -- how to rule out Conservative Replication
How do you find out which possibility is the correct one? The Meselson-Stahl experiment was done to settle this issue. The experiment is explained in Becker, fig. 19-4 (19-3 & 19-4), and in Sadava 11.11 (11.9 in 7th,11.10 in 6th ed). The basic idea is to use density as a label to distinguish old and new pieces of DNA. M & S grew bacteria a long time in medium containing heavy N (15N), so all the DNA was heavy. Then they grew the bacteria for 1 generation in medium containing light or ordinary N (14N), so all new DNA strands or newly made sections should be light. Then they extracted the DNA from the cells and measured the density of the DNA. All the DNA was of a hybrid density in between heavy and light. This result is consistent with semi-conservative replication (and dispersive replication) and it rules out conservative replication -- if replication were conservative, then after 1 generation 1/2 the DNA (the "old" molecules) should be heavy and 1/2 (the "new" molecules) should be light.
C. Some Details of the Method How to tell DNA's of different densities apart?
The method M & S used is called equilibrium density centrifugation. See Sadava 11.11 (11.9) or Becker, Fig. 19-3 (6th ed only) & Box 12A. p. 331 (325). Equil. density centrifugation separates molecules on the basis of differences in density.
How is this different from measuring S values using sedimentation velocity centrifugation, as described previously? Sed. vel. centrifugation separates molecules on the basis of differences in size, not density. A table summarizing the differences between the two methods is on handout 11-1.
D. M-S experiment, cont. -- How to rule out dispersive Replication
1. Method 1 (2nd generation).
M & S then grew the bacteria another generation in light N and looked at the density of the DNA after 2 rounds of DNA replication. The result is in the texts and you should be sure you understand how the result rules out dispersive (and conservative) replication.
To check your understanding, consider the following: For each type of DNA replication, what do you expect after 2 generations? What should the double stranded DNA molecules look like (H-H? H-L), and what should the test tubes look like after centrifugation -- how many bands, and of what density?
2. Method 2 (Denaturation)
M & S did another experiment to rule out dispersive replication -- they took the hybrid DNA obtained after 1 generation of growth in light N and denatured it. They reasoned that if replication is semi-conservative, the denatured DNA should be 1/2 heavy and 1/2 light or 1/2 old strands and 1/2 new ones. If replication is dispersive, each individual single strand should be part heavy and part light, and so all the denatured DNA should be hybrid in density. The denatured DNA was 1/2 heavy and 1/2 light, ruling out dispersive replication and supporting semi-conservative.
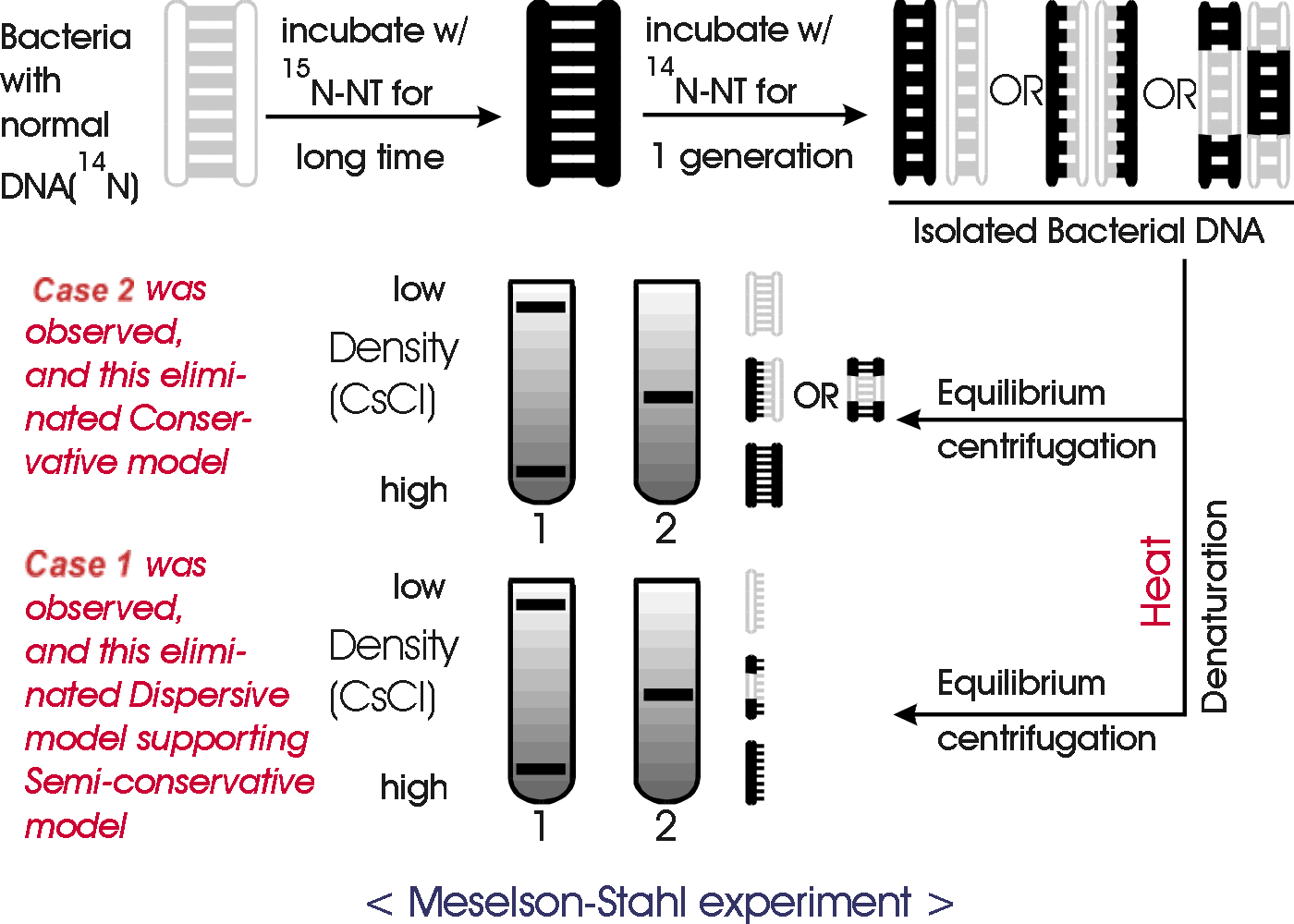
To review the M.S. experiment and its implications, do problem 6-6, parts A & B. Then try 6-8 & 6-9.
IV. "Genetical" Implications of DNA
structure, or how does DNA do job #2?
In other words, how does DNA determines its own nucleotide sequence? What are the major issues?
A. Is DNA self replicating? If you put DNA in a test tube with nucleotide monophosphates (deoxy AMP, TMP, etc.), the DNA should act as template and the nucleotides should get hooked up to make more DNA. But if you try this, you won' t get any new DNA made. Why not? Because you forgot the enzymes and the energy problem. DNA is self replicating in the sense that it determines its own order, but it is not self replicating in the sense that it can replicated by itself -- it requires enzymes (& energy) to replicate.
B. The 3 big issues: There are 3 issues to keep in mind when making a long nonrepeating molecule like DNA (or protein or RNA). They are:
1. Order: How do you line up the monomers in the right order? What is the template?
2. Energy: Where does the energy for synthesis come from?
3. Enzymes: What is the role of enzymes in this process?
C. How do order, energy & enzymes fit in? M-S experiment described above settles issue 1, but what about 2 & 3? How do the enzymes and energy come in? First let's focus on the energy, and then come back to the enzymes.
V. DNA Replication -- Issue 2 -- Energy
Considerations. (See Handout
11-2 for all Reactions & a summary diagram. )
A. Reaction 1 -- Synthesis or hydrolysis?
The obvious reaction for adding a nucleotide to a growing chain is Reaction 1: (all reactions refer to numbered reactions on handout 11-2).
Rxn 1: Chain n nucleotides long +
nucleotide mono-phosphate → chain n+1 nucleotides long + H2O.
New nucleotide is added to 3' end of chain.
For example: AGC + TMP → AGCT + H2O. (See handout for more detailed picture.)
Notes:
(1). DNA vs RNA: If you are making RNA, the sugars are ribose, and the bases are A, G, C & U. If you are making DNA, the sugars are deoxyribose
and the bases are A, G, C & T. In this case it is understood that all the
sugars are deoxy, since we are discussing DNA synthesis. The basic process of chain growth
is the same for DNA and RNA.
(2). You would need a DNA template to make RNA or DNA as
shown in rxn. 1 above and in rxn. 4 below. The template is not drawn in here
(and on handout 11-2) because the focus of this section is on energy, but you
should assume template is present.
Reaction 1 has a positive Δ Go of about +7 kcal/mole, so it goes to the left, not the right. Rxn. 1 is actually used (to the left) to break down polynucleotides that you eat → mononucleotides for building your own DNA. You have to break down ingested DNA so it doesn't transform you -- you want to recycle the nucleotides, but you want to destroy the foreign genetic information.
B. How to drive rxn. 1 to the right? Why we need rxn. 2
To drive rxn. 1 strongly to the right (and achieve synthesis, not breakdown), we need to break 2 "high energy" bonds, that is to knock 2 phosphates off an ATP or the equivalent. In other words, we want to couple the following reaction to rxn 1:
|
Rxn. 2 |
2 ATP + 2 H2O → 2 ADP + 2 Pi |
ΔGo = -14 kcal/mole |
The Pi is written in bold to emphasize that it is a phosphate, not a phosphorous atom.
C. How are reactions 1 & 2 coupled? The coupling is done in three steps (rxns 3 - 5). The individual reactions and a summary diagram showing the results on an energy scale are shown on Handout 11-2. The coupling of the three steps (rxns 3 - 5) occurs like so:
(step 1 -- Rxn 3). First the energy of ATP is used to convert TMP, CMP, GMP etc. to TTP, CTP, GTP (using the appropriate enzyme) as follows:
|
Rxn. 3 |
2 ATP + TMP → 2 ADP + TTP |
ΔG° = 0 kcal/mole |
(step 2 -- Rxn 4). Then CTP, GTP, etc. are used as starting materials, so knocking off the extra 2 phosphates can provide the energy to drive nucleotide synthesis. The 2 P-P bonds are broken in 2 steps. First the end P-P is removed as a unit and the nucleotide is added on as follows:
Rxn. 4: Polymerization catalyzed by DNA polymerase (See handout 11-2 for more detailed picture.)
For example: AGC + TTP → AGCT + P-Pi (inorganic pyrophosphate)
(step 3 -- Rxn 5). Then the P-Pi is hydrolyzed using pyrophosphatase as follows:
Pyrophosphatase |
||||
|
Rxn. 5 |
P - Pi + H2O |
----------------------> |
2 Pi |
ΔGo = -7 Kcal/mole |
ΔGo for reactions 3 & 4 is about zero, and ΔGo for rxn 5 is about -7 kcal/mole. The net result of reactions 3 - 5 is to couple reactions 1 & 2, and thus to use the energy of ATP hydrolysis to drive polynucleotide synthesis.
Rxn 5, which is catalyzed by the enzyme pyrophosphatase really "pulls" the entire synthesis of polynucleotides. Rxn 5 is strongly to the right, so it removes one of the products of rxn 4, thus "pulling" rxn 4 to the right. (So ΔG for reaction 4 is <<0 even though ΔGo is zero.) When rxn 4 goes to the right, it uses up the product of rxn 3, pulling it to the right too. So the whole combination, reactions 3 - 5 goes to the right.
D. Summary Diagram. The relative free energy changes involved in all these reactions can be summarized by putting the components on an energy scale, as shown on Handout 11-2. (The 2ATP to 2ADP reaction shown, reaction 2, is downhill, not uphill. It should be in a separate box. It is included to indicate that the energy derived from hydrolysis of ATP is used to 'push' phosphorylation of XMPs to XTPs.)
To review the energy issues in DNA synthesis, try problem 6-7.
VI. DNA Replication -- Issue 3 -- Enzymes.
A. How Many Enzymes?
The enzyme that catalyzes addition of nucleotides to a growing chain (rxn 4) is called DNA polymerase. A very large number of additional enzymes and proteins are required to replicate DNA properly, since the DNA must be unwound, unfolded, etc. (and then rewound and refolded) in addition to being polymerized. (If you are interested, see Becker fig. 19-12.) It also turns out that polymerization (especially starting and stopping) is quite complicated. We will ignore most of the topological and enzymatic complications, and most of the proteins required to deal with them, in this discussion and stick to the enzymes DNA polymerase, ligase (see below) and pyrophosphatase (see above). You will get a chance to appreciate all the fine points of DNA synthesis when you take molecular biology (previously called biochemistry II). We will consider primers and primase next time. There are multiple DNA polymerases, but we will not distinguish them since they all work about the same way. (All add to the free 3' end, so all chains grow in the same direction -- see below).
B. Direction of Chain Growth
1. DNA polymerases all add one way
DNA polymerase adds nucleotides to the 3' end of a growing chain as in rxn 4 above, so the new chain is made from its 5' end to its 3' end. DNA polymerase will not add nucleotides on the the 5' end, and neither will any other enzyme, so all new chains must be made 5' to 3'. Once an enzyme is designed to hold the 3' end of a nucleotide so the 5' end of the nucleotide can hook up the 3' end of the growing chain, then the same enzyme cannot hold the 5' end of a nucleotide, which has a different shape and chemical make up, and so the enzyme cannot catalyze additions to the 5' end of the growing chain.
2. All chains grow antiparallel to template.
All nucleotide chains must be made 5' to 3' and each new single strand must be antiparallel to the its template strand, so the resulting double stranded molecule will have antiparallel strands. See Sadava 11.12 (11.10 in 7th, 11.11 6th ed) or Becker fig. 19-7. For example:
Template |
Daughter Molecules |
Direction of Synthesis of New Strand |
||
5' A G C T T A G 3' |
(old) |
|
||
|
5' A G C T T A G 3' |
→ |
3' T C G A A T C 5' |
(new) |
← |
|
|
|
|||
| 3' T C G A A T C 5' |
→ |
5' A G C T T A G 3' |
(new) |
→ |
| 3' T C G A A T C 5' | (old) |
3. The two "new" strands in a double helix must grow in opposite directions.
If bottom strand of template is used, the new strand must be made left to right (→)
If top strand of template is used, the new strand must be made right to left (←)
In both cases, the new strand is made from 5' to 3'.
What if you want to use both strands of a double helix as templates simultaneously? Then you must make the complement to the top strand in one direction and the complement to the bottom strand in the other direction. This is the only way both strands can be made 5' to 3'.
To review how DNA chains grow, try problems 6-6, part C, & 6-12 parts A-C . Other problems on this topic are 6-10 & 6-11.
C. Discontinuous Synthesis
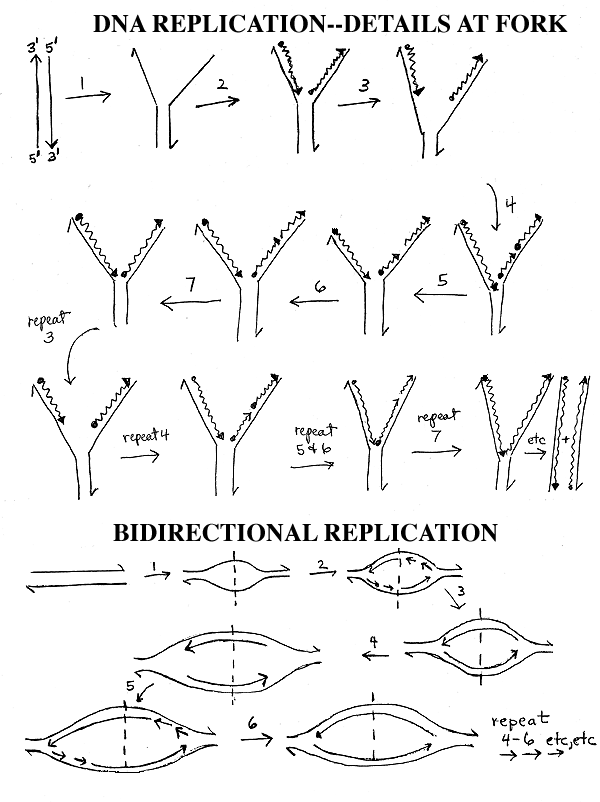
How does replication work with a real DNA molecule that is millions of base pairs long? See Sadava 11.18 (11.16 in 7th, 11.17 in 6th ed) or Becker 19-9. This is diagrammed on handout 11-3. The steps and letters listed below refer to the top diagram on the handout.
You don' t unwind the entire molecule and replicate each template strand separately. Instead you unwind a little of the double helix at a time, starting from one end (step 1), to give molecule A.
Then you replicate the short denatured region as above (step 2), to get molecule B.
Then you unwind a little more (step 3), to get molecule C.
Now one of the new chains (the leading strand, which is the one being made on the left on the handout) can keep on growing 5' to 3' in a continuous manner while the new section of the other chain (the lagging strand, the one being made on the right) must be made 5' to 3' in a retrograde fashion (step 4). This gives molecule D. The short, discontinuously synthesized fragments of about 100 - 1000 bases made in step 4 are known as Okazaki fragments after their discoverer. (See Becker 19-8.)
Skip steps 5 & 6 (and molecules E & F) for now. Steps 5 & 6 involve primers and will be explained later (or next time).
If this retrograde or discontinuous synthesis continues, the new chain on the right (the lagging strand) will have breaks in it, so the cell has an enzyme called ligase that ligates or ties up the short fragments into one continuous chain (step 7). This gives molecule G.
These steps are repeated until the entire double helix is duplicated.
To review discontinuous synthesis, go over handout 11-3 (top) and/or figures in texts. Wait on the problems until we go over primers.
Lecture will (hopefully) cover at
least to here; anything that isn't covered in #11 will be wrapped up in #12.
VII. Bi-directional Replication. (Bottom
of handout
11-3).
A. How many replication forks per DNA? The more forks, the faster replication is. Most small genomes (such as bacterial and viral DNA's) are circular, and replicate bi-directionally -- 2 forks emanate from a single origin as shown on the bottom of handout 11-3 or Sadava 11.13A (11.11a in 7th, 11.12a in 6th ed.) or Becker 19-4 (19-5). Longer DNA molecules are usually linear and often have multiple bidirectional origins of replication as shown in Sadava 11.14B (11.12 b or 11.13b) or Becker fig. 19-5 (19-6) -- this will be discussed later when we get to eukaryotes.
B. How does bi-directional Replication go? In the top picture on the handout you have one fork or zipper moving down the DNA. In the bottom picture, you have 2 zippers or forks. Both start from the same point (the dotted line = origin of DNA replication = ori) but one fork goes to the left and one fork goes to the right. The events at each fork are the same as those shown in the top of the handout, but the forks go left and right instead of down. At each fork you have unwinding, continuous synthesis on one strand and discontinuous synthesis & ligation on the other strand, just as before. If the DNA is circular, the right fork is really going clockwise and the left fork counterclockwise, and the 2 forks proceed until they meet in the middle of the molecule, approximately 180 degrees from where they started. (See Becker fig. 19-4 (19-5).)
C. An Important Definition: Bidirectional replication means that there are 2 forks that move in opposite directions. It does NOT refer to the fact that the 2 DNA strands (leading and lagging strands) are made in opposite directions. That is called discontinuous synthesis, and it always happens at every fork whether there is one fork (unidirectional replication as in the top panel of handout 11-3) or two (bidirectional replication as on the bottom of the handout.)
To be sure you understand what is happening in the bottom picture, it is a good idea to write in all the 5' and 3' ends on the DNA's shown and also to number the Okazaki fragments at each fork to show the order in which they are made.
D. Topology.
1. What Moves? In the pictures on the handouts and in many pictures in the texts, it looks like the DNA stays put and the enzymes move down the DNA. It is probably the other way around -- the enzymes stay put, and the DNA slides through them. See Sadava fig. 11.13 & 11.14 (11.11 & 11.12 in 7th ed, 11.12 & 11.13 in 6th; not in 5th edition.)
2. How Polymerase is Oriented: (FYI only.) The polymerases making the leading and lagging strands are probably moving (or facing) effectively in the same direction, relative to the fork, because the template for the lagging strand is looped around. See Becker fig. 19-14. (The leading and lagging strands are both being made in the 5' to 3' direction, anti-parallel to their respective templates.) The end of the animation (see link above) called 'How nucleotides are added in DNA Replication' shows the looping.
To review bi-directional replication, see problem 6-13, part A.
Next time: Primers -- How do DNA chains get started?
Lecture #12: Wrap up of DNA synthesis, PCR, and then on to RNA synthesis. What do you need RNA for, and how is RNA made? How do RNA and DNA synthesis compare?