
This chapter provides an introduction to DB2 Universal Database and to the types of parallelism provided by DB2. This chapter describes the following:
DB2 provides the flexibility for you to run a wide range of hardware configurations. It allows you to choose how to best match your hardware and application requirements with a specific DB2 product configuration.
The remaining chapters in this part of the book assist you in the design and implementation of your database. With the different levels of complexity in database environments that DB2 supports, there are considerations and tasks specific to one or more of these environments. These considerations and tasks are presented toward the end of each section or chapter and introduced as being for a specific environment. In some cases, entire sections or chapters are appropriate for only a specific environment. After reading this chapter, you should be able to discern which chapters are appropriate for your business needs and your environment.
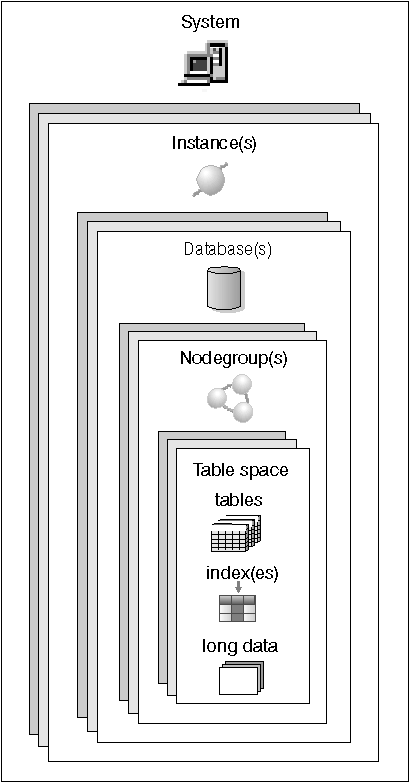
A database manager (sometimes called an instance) is DB2 code that manages data. It controls what can be done to the data, and manages system resources assigned to it. Each instance is a complete environment. It contains all the database partitions defined for a given parallel database system. An instance has its own databases (which other instances cannot access), and all its database partitions share the same system directories. It also has separate security from other instances on the same machine.
A nodegroup is a set of one or more database partitions. When you want to create tables for the database, you first create the nodegroup where the table spaces will be stored, then you create the table space where the tables will be stored. See "Nodegroups and Data Partitioning" for more information about nodegroups. See "Overview of DB2 Parallelism Concepts" for the definition of a database partition.
A database is organized into parts called table spaces. A table space's definition and attributes are recorded in the database system catalog. Once a table space is created, you can then create tables within this table space. A container is assigned to a table space. A container is an allocation of physical storage (such as a file or device). Table spaces reside in nodegroups.
A table consists of data logically arranged in columns and rows. The data in the table is logically related, and relationships can be defined between tables. Data can be viewed and manipulated based on mathematical principles and operations called relations. Table data is accessed via SQL, a standardized language for defining and manipulating data in a relational database. All database and table data is assigned to table spaces.
A query is used in applications or by users to retrieve data from a database. The query uses Structured Query Language (SQL) to create a statement in the form of
SELECT <data_name> FROM <table_name>
In this chapter we use the term "query" to identify a retrieval request (a SELECT statement) from a database.
Figure 1 illustrates the relationship among the objects just described. It also illustrates that tables, indexes, and long data are stored in table spaces.
Figure 1. Relationship Among Some Database Objects
|
DB2 extends the database manager to the parallel, multi-node environment. A database partition is a part of a database that consists of its own data, indexes, configuration files, and transaction logs. (See the Administration Getting Startedfor an overview of indexes, configuration files, and transaction logs.) A database partition is sometimes called a node or database node. (Node was the term used in the DB2 Parallel Edition for AIX Version 1 product.)
A single-partition database is a database having only one database partition. All data in the database is stored in that partition. In this case nodegroups, while present, provide no additional capability.
A partitioned database is a database with two or more database partitions. Tables can be located in one or more database partitions. When a table is in a nodegroup consisting of multiple partitions, some of its rows are stored in one partition and others are stored in other partitions.
Usually, a single database partition exists on each physical node and the processors on each system are used by the database manager at each database partition to manage its part of the database's total data.
Because data is divided across database partitions, you can use the power of multiple processors on multiple physical nodes to satisfy requests for information. Data retrieval and update requests are decomposed automatically into sub-requests and executed in parallel among the applicable database partitions. The fact that databases are split across database partitions is transparent to users of SQL statements.
User interaction is through one database partition. It is known as the coordinator node for that user. The coordinator runs on the same database partition as the application, or in the case of a remote application, the database partition to which that application is connected. Any database partition can be used as a coordinator node.
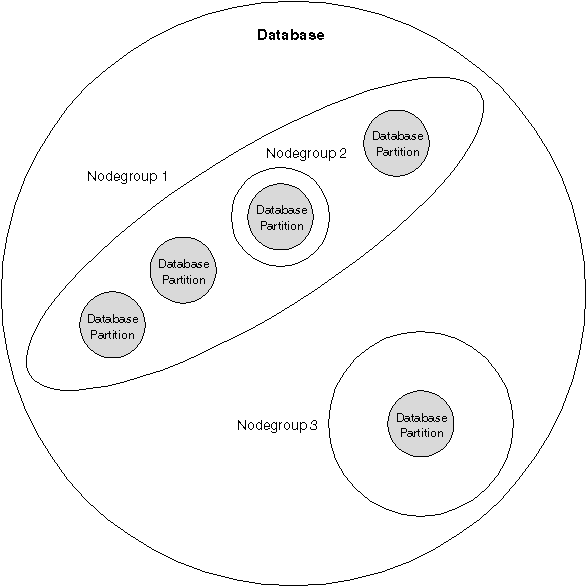
You can define named subsets of one or more database partitions in a database. Each subset you define is known as a nodegroup. Each subset that contains more than one database partition is known as a multi-partition nodegroup. Multi-partition nodegroups can only be defined with database partitions that belong to the same instance.
Figure 2 shows an example of a database with five partitions in which:
Figure 2. Nodegroups in a Database
 |
You create a new nodegroup using the CREATE NODEGROUP statement. See the SQL Reference for more information. Data is divided across all the partitions in a nodegroup. If you are using a multi-partition nodegroup, you must look at several nodegroup design considerations. For more information in both of these areas, see "Designing Nodegroups".
Parts of a database-related task (such as a database query) can be executed in parallel in order to speed up the task, often dramatically so. There are different ways a task is performed in parallel. The nature of the task, the database configuration, and the hardware environment determine how DB2 will perform a task in parallel. These considerations are interrelated. You should consider them together when first deciding on the physical and logical design of a database. This section describes the types of parallelism.
DB2 supports the following types of parallelism:
For situations in which multiple containers exist for a table space, the database manager can initiate parallel I/O. Parallel I/O refers to the process of reading from or writing to two or more I/O devices at the same time to reduce elapsed time. Performing I/O in parallel can result in significant improvements to I/O throughput.
I/O parallelism is a component of each hardware environment described in "Hardware Environments". Table 1 lists the hardware environments best suited for I/O parallelism.
There are two types of query parallelism: inter-query parallelism and intra-query parallelism.
Inter-query parallelism refers to the ability of multiple applications to query a database at the same time. Each query will execute independently of the others, but DB2 will execute all of them at the same time. DB2 has always supported this type of parallelism.
Intra-query parallelism refers to the processing of parts of a single query at the same time using either intra-partition parallelism or inter-partition parallelism or both.
The term query parallelism is used throughout this book.
Intra-partition parallelism refers to the ability to break up a query into multiple parts. (Some of the utilities also perform this type of parallelism. See "Utility Parallelism".)
Intra-partition parallelism subdivides what is usually considered a single database operation such as index creation, database load, or SQL queries into multiple parts, many or all of which can be executed in parallel within a single database partition.
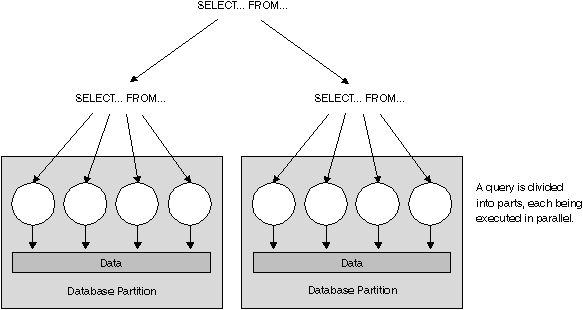
Figure 3. Intra-Partition Parallelism
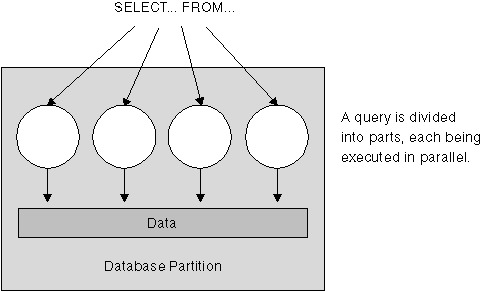 |
Figure 3 shows a query that is broken into four pieces that can be executed in parallel, with the results returned more quickly than if the query was run in a serial fashion. The pieces are copies of each other. To utilize intra-partition parallelism, you need to configure the database appropriately. You can choose the degree of parallelism or let the system do it for you. The degree of parallelism is the number of pieces of a query that execute in parallel.
Table 1 lists the hardware environments best suited for intra-partition parallelism.
Inter-partition parallelism refers to the ability to break up a query into multiple parts across multiple partitions of a partitioned database, on one machine or multiple machines. The query is performed in parallel. (Some of the utilities also perform this type of parallelism. See "Utility Parallelism".)
Inter-partition parallelism subdivides what is usually considered a single database operation such as index creation, database load, or SQL queries into multiple parts, many or all of which can be executed in parallel across multiple partitions of a partitioned database in one machine or multiple machines.
Figure 4. Inter-Partition Parallelism
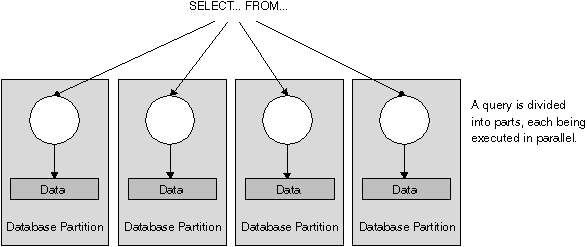 |
Figure 4 shows a query that is broken into four pieces that can be executed in parallel, with the results returned more quickly than if the query was run in a serial fashion in a single partition.
The degree of parallelism is largely determined by the number of partitions you create and how you define your nodegroups.
Table 1 lists the hardware environments best suited for inter-partition parallelism.
You can use intra-partition parallelism and inter-partition parallelism at the same time. This combination provides, in effect, two dimensions of parallelism. This results in an even more dramatic increase in the speed at which queries are processed. Figure 5 illustrates this.
Figure 5. Both Inter-Partition and Intra-Partition Parallelism
 |
DB2's utilities can take advantage of intra-partition parallelism. They can also take advantage of inter-partition parallelism; where multiple database partitions exist, the utilities execute in each of the partitions in parallel. The following paragraphs describe how some utilities take advantage of parallelism.
The LOAD utility can take advantage of intra-partition parallelism and I/O parallelism. Loading data is a heavily CPU-intensive task. The LOAD utility takes advantage of multiple processors for tasks such as parsing and formatting data. Also, the LOAD utility can use parallel I/O servers to write the data to the containers in parallel. See "LOAD Performance Considerations" and the LOAD command in the Command Reference for information on how to enable parallelism for the LOAD utility.
In a partitioned database environment, the AutoLoader utility takes advantage of intra-partition, inter-partition, and I/O parallelism by parallel invocations of load at each database partition where the table resides. For more information about the AutoLoader utility, see "Using the AutoLoader Utility".
During index creation, the scanning and subsequent sorting of the data occurs in parallel. DB2 exploits both I/O parallelism and intra-partition parallelism when creating an index. This helps to speed up index creation when a CREATE INDEX command is issued, during restart (if an index is marked invalid), and during the reorganization of data.
Backing up and restoring data are heavily I/O bound tasks. DB2 exploits both I/O parallelism and intra-partition parallelism when performing backups and restores. Backup exploits I/O parallelism by reading from multiple table space containers in parallel, and asynchronously writing to multiple backup media in parallel. See the BACKUP DATABASE command and the RESTORE DATABASE command in the Command Reference for information on how to enable parallelism for these two commands.
This section provides an overview of the following hardware environments:
In each hardware environment section, considerations for capacity and scalability are described. Capacity refers to the number of users and applications able to access the database in large part determined by memory, agents, locks, I/O, and storage management. Scalability refers to the ability for a database to grow and continue to exhibit the same operating characteristics and response times.
This environment is made up of memory and disk, but contains only a single CPU. This environment has been given many names such as: standalone database, client/server database, serial database, uniprocessor system, and single node/non-parallel environment. Figure 6 illustrates this environment.
Figure 6. Single Partition On a Single Processor
 |
The database in this environment serves the needs of a department or small office where the data and system resources (including only a single processor or CPU) are managed by a single database manager.
Table 1 lists the types of parallelism best suited to take advantage of this hardware configuration.
In this environment you can add more disks. Having one or more I/O servers for each disk allows for more than one I/O operation to be taking place at the same time. You can also add more hard disk space to this environment.
A single-processor system is restricted by the amount of disk space the processor can handle. However, as workload increases a single CPU may become insufficient in processing user requests any faster, regardless of other additional components, such as memory or disk, that you may add.
If you have reached maximum capacity or scalability, you can consider moving to a single partition system with multiple processors. This configuration is described in the next section.
This environment is typically made up of several equally powerful processors within the same machine and is called a symmetric multi-processor (SMP) system. Resources such as disk space and memory are shared. More disks and memory are found in this machine compared to the single-partition database, single processor environment. This environment is easy to manage since physically everything is together in one machine and the sharing of memory and disks is expected.
With multiple processors available, different database operations can be completed significantly more quickly than with databases assigned to only a single processor. DB2 can also divide the work of a single query among available processors to improve processing speed. Other database operations such as the LOAD utility, the backup and restore of table spaces, and index creation on existing data can take advantage of the multiple processors. Figure 7 illustrates this environment.
Figure 7. Single Partition Database Symmetric Multiprocessor System
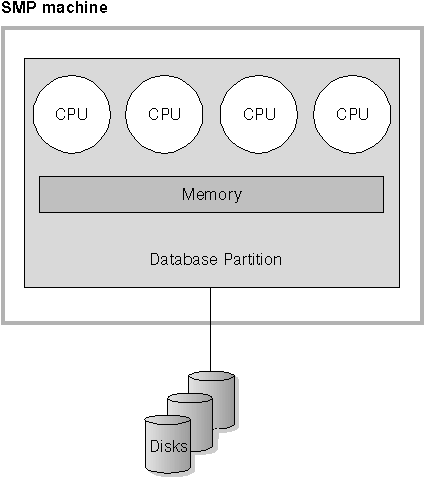 |
Table 1 lists the types of parallelism best suited to take advantage of this hardware configuration.
In this environment you can add more processors. However, since it is possible for the different processors to attempt to access the same data, limitations with this environment can appear as your business operations grow. With shared memory and shared disks, you are effectively sharing all of the database data. One application on one processor may be accessing the same data as another application on another processor, possibly causing the second application to wait for access to the data.
You can increase the I/O capacity of the database partition associated with your processor, such as the number of disks. You can establish I/O servers to specifically deal with I/O requests. Having one or more I/O servers for each disk allows for more than one I/O operation to take place at the same time.
If you have reached maximum capacity or scalablity, you can consider moving to a system with multiple partitions. These configurations are described in the next section.
You can divide a database into multiple partitions, each on its own machine. Multiple machines with multiple database partitions can be grouped together. This section describes the following partition configurations:
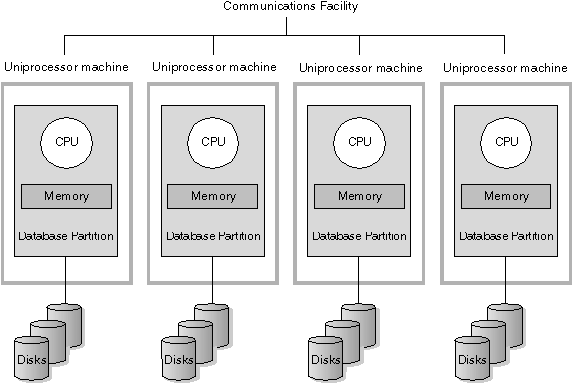
In this environment there are many database partitions with each partition on its own machine and having its own processor, memory, and disks. Figure 8 illustrates this. A machine consists of a CPU, memory, and disk with all machines connected by a communications facility. Other names that have been given to this environment include: a cluster, a cluster of uniprocessors, a massively parallel processing (MPP) environment, or a shared-nothing configuration. The latter name accurately reflects the arrangement of resources in this environment. Unlike an SMP environment, an MPP environment has no shared memory or disks. The MPP environment removes the limitations introduced through the sharing of memory and disks.
Figure 8. Massively Parallel Processing System
 |
A partitioned database environment allows a database to remain a logical whole while being physically divided across more than one partition. To applications or users, the database can be used as a whole and the fact that data is partitioned remains transparent to most users. The work to be done with the data can be divided out to each of the database managers. Each database manager in each partition works against its own part of the database.
Table 1 lists the types of parallelism best suited to take advantage of this hardware configuration.
In this environment you can add more database partitions (nodes) to your configuration. On some platforms, for example the RS/6000 SP, the maximum is 512 nodes. However, there may be practical limits for managing a high number of machines and instances.
If you have reached maximum capacity or scalability, you can consider moving to a system where each partition has multiple processors. This configuration is described in the next section.
As an alternative to a configuration in which each partition has a single processor is a configuration in which a partition has multiple processors. This is known as an SMP cluster.
This configuration combines the advantages of SMP and MPP parallelism. This means a query can be performed in a single partition across multiple processors. It also means that a query can be performed in parallel across multiple partitions.
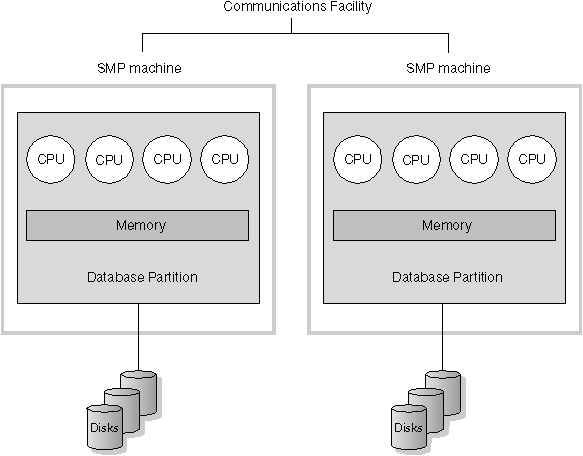 |
Table 1 lists the types of parallelism best suited to take advantage of this hardware configuration.
In this environment you can add more database partitions, as in the previous section. You can also add more processors to existing database partitions.
A logical database partition differs from a physical partition in that it is not given control of an entire machine. Although the machine has shared resources, the database partitions do not share the resources. Processors are shared but disk and memory are not.
One reason for using logical database partitions is to provide scalability. Multiple database managers running in multiple logical partitions may be able to make fuller use of available resources than a single database manager could. This will become more true as machines with even more more processors are manufactured. Figure 10 illustrates the fact that you may gain more scalability on an SMP machine by adding more partitions, particularly for machines with many processors. By partitioning the database, you can administer and recover each partition separately.
Figure 10. Partitioned Database, Symmetric Multiprocessor System
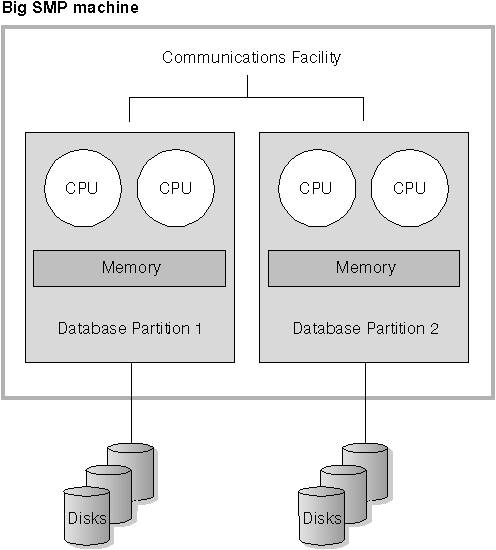 |
Figure 11 illustrates the fact that you can multiply the configuration shown in Figure 10 to increase processing power.
Figure 11. Partitioned Database, Symmetric Multiprocessor Systems Clustered Together
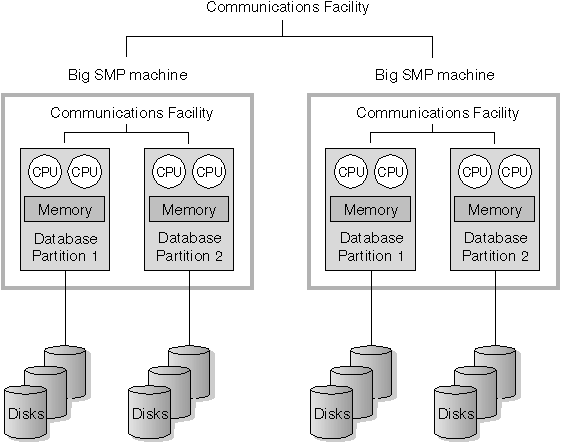 |
Note also that the ability to have two or more partitions coexist on the same machine (regardless of the number of processors) allows greater flexibility in designing high availability configurations and failover strategies. See Chapter 21. "High Availability Cluster Multi-Processing (HACMP) on AIX" for a description of how, upon machine failure, a database partition can be automatically moved and restarted on another machine already containing another partition of the same database.
Table 1 lists the types of parallelism best suited to take advantage of this hardware environment.
The following table summarizes the types of parallelism best suited to
the various hardware environments.
Table 1. Types of Parallelism Possible for Each Hardware Environment
| Hardware Environment | I/O Parallelism | Intra-Query Parallelism | |||
|---|---|---|---|---|---|
| Intra-Partition Parallelism | Inter-Partition Parallelism | ||||
Single Partition, Single Processor | Yes | No(1) | No | ||
Single Partition, Multiple Processors (SMP) | Yes | Yes | No | ||
Multiple Partitions, One Processor (MPP) | Yes | No(1) | Yes | ||
Multiple Partitions, Multiple Processors (cluster of SMPs) | Yes | Yes | Yes | ||
| Logical Database Partitions | Yes | Yes | Yes | ||
| |||||
There are two types of query parallelism: intra-partition parallelism and inter-partition parallelism. Either type, or both types, can be used depending on whether the environment is a single-partition or multi-partition environment.
In order for intra-partition query parallelism to occur, you must modify database configuration parameters and database manager configuration parameters.
For more information on the configuration parameter settings, and how to enable applications to process in parallel, see "Parallel Processing of Applications".
Inter-partition parallelism occurs automatically based on the number of database partitions and the distribution of data across these partitions.
This section provides an overview of how to enable intra-partition parallelism for the following utilities:
Inter-partition parallelism for utilities occurs automatically based on the number of database partitions.
To enable parallelism while loading data, use the following parameters on the LOAD command:
See the Command Reference for information on the LOAD command.
You can enable multiple split processes for the AutoLoader by specifying the MODIFIED BY ANYORDER parameter for the LOAD specification in the autoloader.cfg file. For more information, see "Additional Options and Considerations".
To enable parallelism when creating an index:
See the SQL Reference for information on the CREATE INDEX statement.
To enable parallelism when backing up a database or table space:
To enable I/O parallelism when backing up a database or table space:
See the Command Reference for information on the BACKUP DATABASE command.
To enable parallelism when restoring a database or table space:
To enable I/O parallelism when restoring a database or table space:
See the Command Reference for information on the RESTORE DATABASE command.