
A nodegroup is a named set of one or more nodes that are defined as belonging to a database. Each database partition that is part of the database system configuration must already be defined in a partition configuration file called db2nodes.cfg. A nodegroup can contain from one database partition to the entire number of database partitions defined for the database system.
You create a new nodegroup using the CREATE NODEGROUP statement. You modify a nodegroup using the ALTER NODEGROUP statement. You can add or drop one or more database partitions from a nodegroup. The database partitions must be defined in the db2nodes.cfg file before modifying the nodegroup. Table spaces (defined later) reside within nodegroups. Tables reside within table spaces.
When a nodegroup is created or modified, a partitioning map is associated with it. A partitioning map, in conjunction with a partitioning key and a hashing algorithm, is used by the database manager to determine which database partition in the nodegroup will store a given row of data. More information on partitioning maps, keys, and other related issues are discussed later in this chapter.
With a non-partitioned database, no partitioning key or partitioning map is required. There are no nodegroup design considerations if you are using a non-partitioned database. A database partition is part of the database that consists of its own user data, indexes, configuration files, and transaction logs. Default nodegroups that were created when the database was created, are used by the database manager. IBMCATGROUP is the default nodegroup for the table space containing the system catalogs. IBMTEMPGROUP is the default nodegroup for the table spaces containing the temporary tables. IBMDEFAULTGROUP is the default nodegroup for the table spaces containing the user-defined tables the user chooses to put there.
If you are using a multiple partition nodegroup, consider the following design points:
You should place small tables in single database partition nodegroups, except where you want to take advantage of collocation with a larger table. Collocation is the placement of rows from different tables that contain related data in the same database partition. Collocated tables allow the database to utilize more efficient join strategies. Collocated tables can reside in a single database partition nodegroup. Tables are considered collocated if they reside in a multiple partition nodegroup, and have the same number of columns in the partitioning key and the data types of the corresponding columns are partition compatible. Rows in collocated tables with the same partitioning key value are placed on the same database partition. Tables can be in separate table spaces in the same nodegroup and still be considered collocated.
You should avoid extending medium-sized tables across too many database partitions. For example, a 100 MB table may perform better on a 16-database partition nodegroup than on a 32-database partition nodegroup.
You can use nodegroups to separate online-transaction-processing (OLTP) tables from decision-support tables to ensure that the performance of OLTP transactions is not impacted by decision-support transactions.
Based on the logical design of your database, and the amount of data that the database is required to process, you should have a good idea whether your database needs to be partitioned. If you need to partition your database, you should consider the following to complete your database design as it relates to nodegroup use:
DB2 supports a partitioned storage model allowing you to store data across several database partitions in the database. This means that the data is physically stored across more than one database partition and yet can be accessed as if the data were located in the same place. Applications and users accessing data in a partitioned database do not need to be aware of the location of the data.
The data, while physically split, is used and managed as a logical whole. Users can choose how to partition their data by declaring partitioning keys. Users can also determine which and how many database partitions their table data can be spread across by selecting the table space and the associated nodegroup in which the data should be stored. In addition, a partitioning map (which is user-updateable) is used with a hashing algorithm to specify the mapping of partitioning key values to database partitions which determines the placement and retrieval of each row of data. As a result, you can spread the workload across a partitioned database for large tables while allowing smaller tables to be stored on one or more database partitions. Each database partition has local indexes on the data it stores resulting in increased performance for local data access.
You are not restricted in your design to having all tables in their table spaces divided equally across all database partitions in the database. DB2 supports partial declustering, which means that you can divide tables and their table spaces across a subset of database partitions in the system (that is, a nodegroup). You do not have to divide all tables in their table spaces across all the database partitions in the system.
An alternative to consider when you would like tables to be positioned on each database partition, is to use summary tables and then replicate those tables. A summary table could be created with the information you choose. Then you could replicate the summary table to each node. See "Replicated Summary Tables" for more information on why you would want to do this.
In a partitioned database environment, the database manager has to have a way of knowing which rows of a table are stored on which database partition in the database. The database manager has to know where to go to look at or retrieve the data it needs. Just as we need a map to find our way around a city to different locations, the database manager needs a map, called a partitioning map, to find the right part of the database (that is, which database partition) to go to get different parts of the data in the database.
A partitioning map is an internally generated array containing either 4 096 entries for multiple partition nodegroups, or a single entry for single partition nodegroups. For a single partition nodegroup, the partitioning map has only one entry containing the partition number of the database partition where all the rows of a database table are stored. For multiple partition nodegroups, the partition numbers of the nodegroup are specified in a round-robin fashion. Just as a city map is organized into sections using a grid, the database manager uses a partitioning key to determine the location (the database partition) where the data is stored.
For example, assume that you have a database created on four database partitions (numbered 0-3). The partitioning map for the IBMDEFAULTGROUP nodegroup of this database would be:
0 1 2 3 0 1 2 ...
If a nodegroup had been created in the database using database partitions 1 and 2, the partitioning map for that nodegroup would be:
1 2 1 2 1 2 1 ...
If the partitioning key for a table to be loaded in the database is an integer that has possible values between 1 and 500 000, the partitioning key is hashed to a partition number between 0 and 4 095. That number is used as an index into the partitioning map to select the database partition for that row.
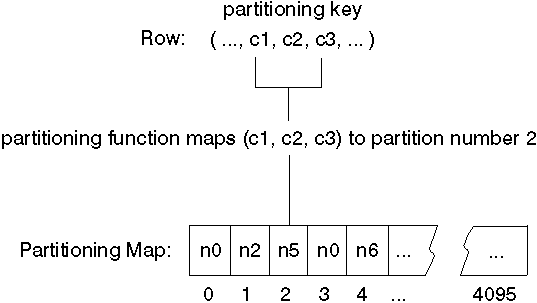
Figure 16 shows how the row with the partitioning key value (c1, c2, c3) is mapped to partition 2, which, in turn, references database partition n5.
Figure 16. Data Distribution Using a Partition Map
A partition map is a flexible way of controlling where data is stored in a partitioned database. If you have a need at some future time to change the data distribution across the database partitions in your database, you can use the data redistribution utility. The data redistribution utility allows you to re-balance or introduce skew into the data distribution. For more information regarding this utility, see Chapter 18. "Redistributing Data Across Database Partitions".
You can use the Get Table Partitioning Information (sqlugtpi) API to obtain a copy of a partitioning map that you can view. For more information on this API, see the API Reference manual.
A partitioning key is a column (or group of columns) that is used to determine the partition in which a particular row of data is stored. A partitioning key is defined on a table using the CREATE TABLE statement. If a partitioning key is not defined for a table in a table space that is divided across more than one database partition in a nodegroup, one is created by default from the first column of the primary key. If no primary key is specified, the default partitioning key is the first non-long field column defined on that table. (Long includes all long data types and all Large Object data types). If you are creating a table in a table space associated with a single database partition nodegroup and you want to have a partitioning key, you must define the partitioning key explicitly. One is not created by default.
If no columns satisfy the requirement of the default partitioning key, the table is created without one. Tables without a partitioning key are only allowed in single database partition nodegroups. You can add or drop partitioning keys at a later time following the initial creation of the table using the ALTER TABLE statement. Altering the partition key can only be done to a table in a table space that is associated with a single database partition nodegroup.
Choosing a good partitioning key is important. When you make the choice, you must know:
If collocation is not a major consideration, a good partitioning key for a table is one that spreads the data evenly on all database partitions in the nodegroup. The partitioning key for each table in a table space that is associated with a nodegroup determines if the tables are collocated. Tables are considered collocated when:
This ensures that rows of collocated tables with the same partitioning key values are located on the same partition. For more information on partition-compatibility, see "Partition Compatibility". For more information on table collocation, see "Table Collocation".
An inappropriate partitioning key can cause the distribution in the data of the table to be uneven. Columns with unevenly distributed data and columns with a small number of distinct values should not be chosen as a partitioning key. The number of distinct values must be great enough to ensure an even distribution of rows across all database partitions in the nodegroup. The cost of applying the partitioning hash algorithm is proportional to the size of the partitioning key. The partitioning key cannot be more than 16 columns, but fewer columns make for better performance. Unnecessary columns should not be included in the partitioning key.
The following points should be considered when defining partitioning keys:
UPDATE emp_table SET ... WHERE emp_no = host-variable
In a situation like this, the emp_no column is a good choice as a single column partitioning key for the emp_table table.
Hash partitioning is the method whereby the placement of each row in the partitioned table is determined. The method works as follows:
When logically designing your database, and based on the needs of your applications, you may find that two or more tables will jointly provide data in response to frequently asked queries. When physically designing your database, you want related data from these two tables to be located as close together as possible. In an environment where the database is physically divided among two or more database partitions, there must be a way to keep the related pieces of the divided tables as close together as possible. The ability to do this is called table collocation.
Tables are collocated when they are stored in the same nodegroup, and when their partitioning keys are compatible. Placing both tables in the same nodegroup ensures a common partitioning map. The tables may be in different table spaces, but the table spaces must be associated with the same nodegroup. The data types of the corresponding columns in each partitioning key must be partition-compatible. For information about partition compatibility, see "Partition Compatibility".
DB2 has the ability to recognize, when accessing more than one table for a join or subquery, that the data to be joined is located at the same database partition. When this happens, DB2 can choose to perform the join or subquery at the database partition where the data is stored instead of having to move data between database partitions. This ability to carry out joins or subqueries at the database partition has significant performance advantages. For more information, see "Collocated Joins".
The base data types of corresponding columns of partitioning keys are compared and can be declared as being partition compatible. Partition compatible data types have the property that two variables, one of each type, with the same value, are mapped to the same partition number by the same partitioning algorithm.
Partition compatibility has the following characteristics:
A summary table is a table that is defined by a query that is also used to determine the data in the table. Summary tables can be used to improve the performance of queries. If the database manager determines that a portion of a query could be resolved using a summary table, the query may be rewritten by the database manager to use the summary table. This decision is based on certain settings such as CURRENT REFRESH AGE and CURRENT QUERY OPTIMIZATION special registers.
In a partitioned database environment, you can replicate summary tables. You can use replicated summary tables to improve query performance. A replicated summary table is a table that is based on a table that you created in a table space (perhaps a table space created in a single-partition nodegroup), but you want all the table data replicated across all the database partitions in the nodegroup. To create the replicated summary table, you use the CREATE TABLE statement with the REPLICATED keyword. The REPLICATED keyword is only valid when the AS fullselect and REFRESH IMMEDIATE keywords are also used.
See "Creating a Summary Table" for information concerning summary tables.
By using replicated summary tables, you can obtain collocation between tables that are not typically collocated. Replicated summary tables are particularly useful for joins in which you have a large fact table and small dimension tables. To minimize the extra storage required and the impact of having to update every replica, good candidates for tables to be replicated would have the following characteristics:
| Note: | You should also consider replicating larger tables that are infrequently updated: in this situtation, the one-time cost of replication is offset by the performance benefits that can be obtained by collocation. |
By specifying a suitable predicate in the subselect used to define the replicated table, you can replicate both selected columns, selected rows, or both.
For more information about replicated summary tables, see the CREATE TABLE statement in the SQL Reference. For more information about collocation, see "Collocated Joins".