
In a hot standby configuration, the AIX processor node that is the takeover node is not running any other workload. In a mutual takeover configuration, the AIX processor node that is the takeover node is running other workload.
Generally, DB2 UDB EEE runs in mutual takeover mode with partitions on each node. One exception is a scenario where the catalog node is part of a hot standby configuration.
When planning a large DB2 installation on a RS/6000 SP using HACMP ES, you need to consider how to divide the nodes of the cluster within or between the RS/6000 SP frames. Having a node and its backup in different SP frames can allow takeover in the event one frame goes down (that is, the frame power/switch board fails). However, such failures are expected to be exceedingly rare because there are N+1 power supplies in each SP frame and each SP switch has redundant paths along with N+1 fans and power. In the case of a frame failure, manual intervention may be required to recover the remaining frames. This recovery procedure is documented in the SP Administration Guide. HACMP ES provides for recovery of SP node failures; recovery of frame failures is dependent on proper layout of clusters within the SP frame(s).
Another planning consideration involves how to manage big clusters: It is easier to manage a small cluster than a big one; however, it is also easier to manage one big cluster than many smaller ones. When planning, consider how your applications will be used in your cluster environment. If there is a single, large, homogeneous application running on, for example, 16 nodes then it is probably easier to manage as a single cluster rather than as eight (8) two-node clusters. If the same 16 nodes contain many different applications with different networks, disks, and node relationships then it is probably better to group the nodes into smaller clusters. Keep in mind that nodes integrate into an HACMP cluster one at a time; it will be faster to start a configuration of multiple clusters rather than one large cluster. HACMP ES supports both single and multiple clusters as long as a node and its backup are in the same cluster.
HACMP ES failover recovery allows pre-defined (also known as "cascading") assignment of a resource group to a physical node. The failover recovery procedure also allows floating (also known as "rotating") assignment of a resource group to a physical node. IP addresses; external disk volume groups, filesystems, NFS filesystems; and, application servers within each resource group specify either an application or application component which can be manipulated by HACMP ES between physical nodes by failover and reintegration. Failover and reintegration behavior is specified by the type of resource group created, and by the number of nodes placed in the resource group.
As an example, consider a DB2 database partition (logical node): If its log and table space containers were placed on external disks, and other nodes were linked to that disk, it would be possible for those other nodes to access these disks and restart the database partition (on a takeover node). It is this type of operation that is automated by HACMP. HACMP ES can also be used to recover NFS file systems used by DB2 instance main user directories.
Read the HACMP ES documentation thoroughly as part of your planning for recovery with DB2 UDB EEE. You should read the Concepts, Planning, Installation, and Administration guides. Then you can layout the recovery architecture for your environment. For the subsystems you have identified for recovery based on the identified points of failure, identify the HACMP clusters you need and the recovery nodes for each (either hot standby or mutual takeover). This architecture and planning is a starting point for completing the HACMP worksheets found in the documentation (mentioned above).
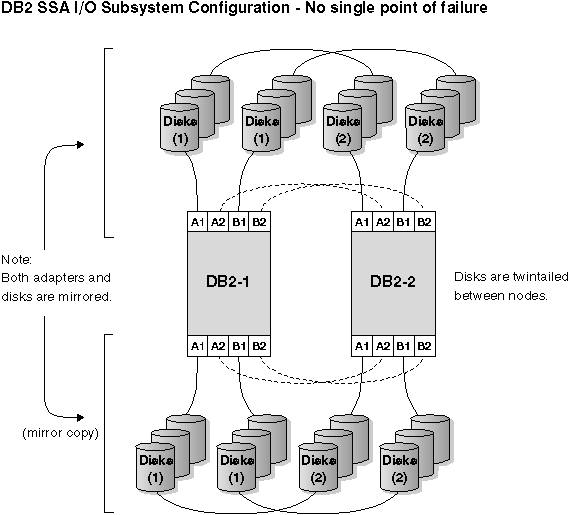
It is strongly recommended that both disks and adapters are mirrored in your external disk configuration. For DB2 physical nodes that are configured for HACMP, care is required to ensure that nodes can vary on the volume group from the shared external disks. In a mutual takeover configuration, this arrangement requires some additional planning so that the paired nodes can access each other's volume groups without conflicts. Within DB2 UDB EEE this means that all container names must be unique across all databases.
One way to achieve uniqueness in the names is to include the partition
number as part of the name. You can specify a node expression for
container string syntax when creating either SMS or DMS containers.
When you specify the expression, either the node number is part of the
container name, or, if you specify additional arguments, the result of the
argument is part of the container name. You use the argument
" $N" ([blank]$N) to indicate the node
expression. The argument must occur at the end of the container string
and can only be used in one of the following forms. In the table below,
the node number is assumed to be five (5):
Table 50. Arguments for Creating Containers
| Syntax | Example | Value |
|---|---|---|
| [blank]$N | " $N" | 5 |
| [blank]$N+[number] | " $N+1011" | 1016 |
| [blank]$N%[number] | " $N%3" | 2 |
| [blank]$N+[number]%[number] | " $N+12%13" | 4 |
| [blank]$N%[number]+[number] | " $N%3+20" | 22 |
|
Notes:
| ||
Following are some examples of creating containers using this special argument:
CREATE TABLESPACE TS1 MANAGED BY DATABASE USING
(device '/dev/rcont $N' 20000)
The following containers would be used:
/dev/rcont0 - on Node 0 /dev/rcont1 - on Node 1
CREATE TABLESPACE TS2 MANAGED BY DATABASE USING
(file '/DB2/containers/TS2/container $N+100' 10000)
The following containers would be used:
/DB2/containers/TS2/container100 - on Node 0 /DB2/containers/TS2/container101 - on Node 1 /DB2/containers/TS2/container102 - on Node 2 /DB2/containers/TS2/container103 - on Node 3
CREATE TABLESPACE TS3 MANAGED BY SYSTEM USING
('/TS3/cont $N%2, '/TS3/cont $N%2+2')
The following containers would be used:
/TS/cont0 - on Node 0 /TS/cont2 - on Node 0 /TS/cont1 - on Node 1 /TS/cont3 - on Node 1
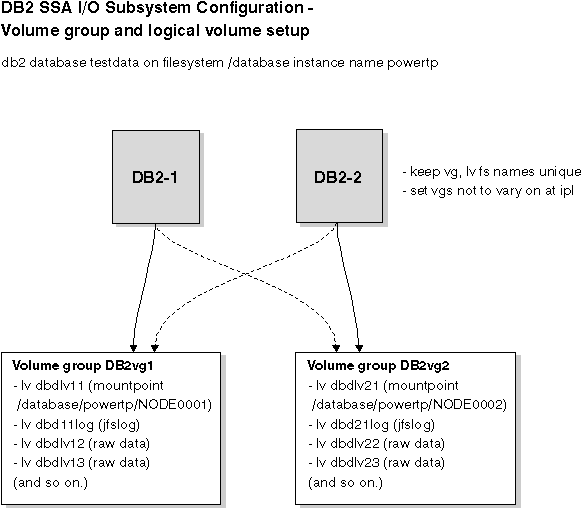
The following pictures show some of the planning involved to ensure a highly available external disk configuration and the ability to access all volume groups without conflict.
Figure 69. No Single Point of Failure
Figure 70. Volume Group and Logical Volume Setup
Once configured, each database partition in an instance is started by HACMP ES one physical node at a time. Using multiple clusters is recommended for starting parallel DB2 configurations that are larger than four (4) nodes.
| Note: | Each HACMP node in a cluster is started one at a time. For a 64-node parallel DB2 configuration, it is faster to start 32, two-node HACMP clusters in parallel rather than four (4), sixteen-node clusters. |
A script file, rc.db2pe, is packaged with DB2 UDB EEE to assist in configuring for HACMP ES failover or recovery in either "hot standby" or "mutual takeover" nodes. In addition, DB2 buffer pool sizes can be customized during failover in mutual takeover configurations from within rc.db2pe. (Buffer pool size modification is needed to ensure proper performance when two database partitions run on one physical node. See the next section for additional information.) The script file, rc.db2pe, is installed on each node in /usr/bin.
When you create an application server in a HACMP configuration of a DB2 database partition, specify rc.db2pe as a start and stop script in the following way:
/usr/bin/rc.db2pe <instance> <dpn> <secondary dpn> start <use switch> /usr/bin/rc.db2pe <instance> <dpn> <secondary dpn> stop <use switch>
where:
<instance> is the instance name.
<dpn> is the database partition number.
<secondary dpn> is the 'companion' database partition number in
'mutual takeover' configurations only; in 'hot standby' configurations
it is the same as <dpn>.
<use switch> is usually blank; when blank, by default this indicates that
the SP Switch network is used for hostname field in the db2nodes.cfg file
(all traffic for DB2 is routed over the SP switch); if not blank, the name
used is the hostname of the SP node to be used.
| Note: | The DB2 command LIST DATABASE DIRECTORY is used from within rc.db2pe to find all databases configured for this database partition. The rc.db2pe script file then looks for /usr/bin/reg.parms.DATABASE and /usr/bin/failover.parms.DATABASE files, where DATABASE is each of the databases configured for this database partition. In a "mutual takeover" configuration, it is recommended you create these parameter files (reg.parms.xxx and failover.parms.xxx). In the failover.parms.xxx file, the settings for BUFFPAGE, DBHEAP, and any others affecting buffer pools should be adjusted to account for the possibility of more than one buffer pool. Buffer pool size modification is needed to ensure proper performance when two or more database partitions run on one physical node. Sample files reg.parms.SAMPLE and failover.parms.SAMPLE are provided for your use. |
One of the important parameters in this environment is START_STOP_TIME. This database manager configuration parameter has a default value of ten (10) minutes. However, rc.db2pe sets this parameter to two (2) minutes. You should modify this parameter within rc.db2pe so that it is set to ten (10) minutes or perhaps something slightly larger. The length of time in the context of a failed database partition is the time between the failure of the partition and the recovery of that partition. If there are frequent "COMMIT"s used in the applications running on a partition, then ten minutes following the failure on a database partition should be sufficient time to rollback uncommitted transactions and reach a point of consistency for the database on that partition. If your workload is heavy and/or you have many partitions, you may need to increase the parameter value until there is no longer an additional problem beyond that of the original partition failure. (The additional problem would be the timeout message resulting from exceeding the START_STOP_TIME value while waiting for the rollback to complete at the failed database partition.)
The assumption in this example is that the mutual takeover configuration will exist between physical nodes one and two with a DB2 instance name of "POWERTP". The database partitions are one and two, and the database name is "TESTDATA" on filesystem /database.
Resource group name: db2_dp_1 Node Relationship: cascading Participating nodenames: node1_eth, node2_eth Service_IP_label: nfs_switch_1 (<<< this is the switch alias address) Filesystems: /database/powertp/NODE0001 Volume Groups: DB2vg1 Application Servers: db2_dp1_app Application Server Start Script: /usr/bin/rc.db2pe powertp 1 2 start Application Server Stop Script: /usr/bin/rc.db2pe powertp 1 2 stop
Resource group name: db2_pd_2 Node Relationship: cascading Participating nodenames: node2_eth, node1_eth Service_IP_label: nfs_switch_2 (<<< this is the switch alias address) Filesystems: /database/powertp/NODE0002 Volume Groups: DB2vg2 Application Servers: db2_dp2_app Application Server Start Script: /usr/bin/rc.db2pe powertp 2 1 start Application Server Stop Script: /usr/bin/rc.db2pe powertp 2 1 stop
The assumption in this example is that the hot standby takeover configuration will exist between physical nodes one and two with a DB2 instance name of "POWERTP". The database partition is one, and the database name is "TESTDATA" on filesystem /database.
Resource group name: db2_dp_1 Node Relationship: cascading Participating nodenames: node1_eth, node2_eth Service_IP_label: nfs_switch_1 (<<< this is the switch alias address) Filesystems: /database/powertp/NODE0001 Volume Groups: DB2vg1 Application Servers: db2_dp1_app Application Server Start Script: /usr/bin/rc.db2pe powertp 1 1 start Application Server Stop Script: /usr/bin/rc.db2pe powertp 1 1 stop
Just as with the configuration of a DB2 database partition presented above, the rc.db2pe script can be used to make available NFS-mounted directories of DB2 parallel instance user directories. This can be accomplished by setting the MOUNT_NFS parameter to "YES" in rc.db2pe and configuring the NFS failover server pair as follows:
For example, an /nfshome JFS filesystem can be exported to all nodes as /dbhome. Each node creates a NFS filesystem /dbname which is nfs_server:/nfshome. Therefore, the home directory of the DB2 instance owner would be /dbhome/powertp when the instance name is "powertp".
Ensure the NFS parameters for the mount in /etc/filesystems are "hard", "bg", "intr", and "rw".
The user definitions in an SP environment are typically created on the Control Workstation and "supper" or "pcp" is used to distribute /etc/passwd, /etc/security/passwd, /etc/security/user, and /etc/security/group to all nodes.
The assumptions in this example are that there is an NFS server filesystem /nfshome in the volume group nfsvg over the IP address "nfs_server". The DB2 instance name is "POWERTP" and the home directory is /dbhome/powertp.
Resource group name: nfs_server Node Relationship: cascading Participating nodenames: node1_eth, node2_eth Service_IP_label: nfs_server (<<< this is the switch alias address) Filesystems: /nfshome Volume Groups: nfsvg Application Servers: nfs_server_app Application Server Start Script: /usr/bin/rc.db2pe powertp NFS SERVER start Application Server Stop Script: /usr/bin/rc.db2pe powertp NFS SERVER stop
| Note: | In this example:
|
When implementing HACMP ES with the SP switch, consider the following:
ifconfig css0 inet alias sw_alias_1 up
The following examples show different possible failover support configurations and what happens when failure occurs.
Figure 71. Mutual Takeover with NFS Failover - Normal
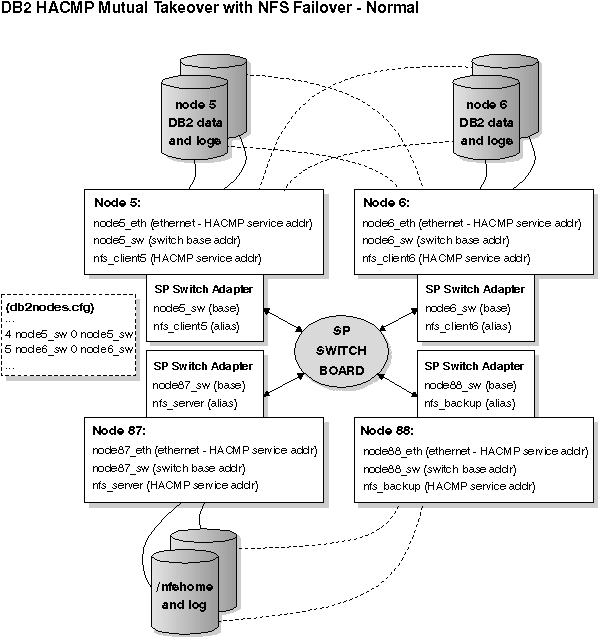
The previous figure and the next two figures each have the following notes associated with them:
Figure 72. Mutual Takeover with NFS Failover - NFS Failover
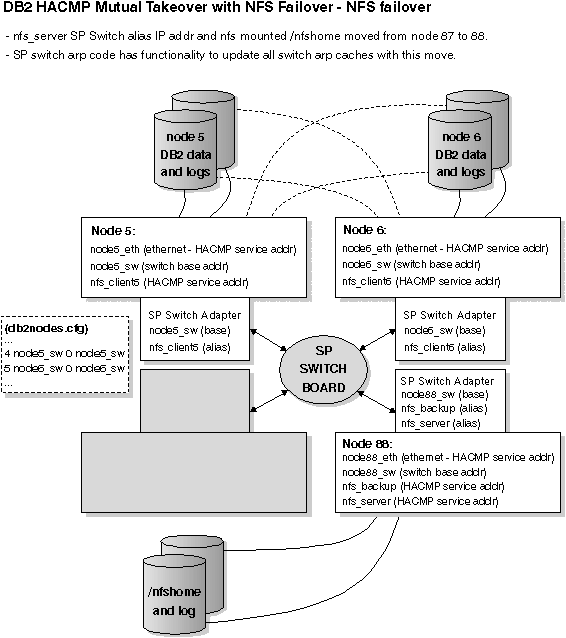
Figure 73. Mutual Takeover with NFS Failover - DB2 Failover
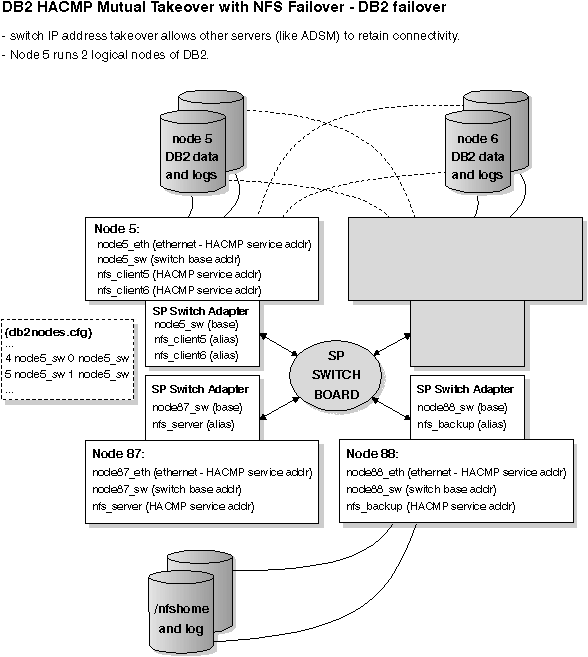
Figure 74. Hot Standby with NFS Failover - Normal
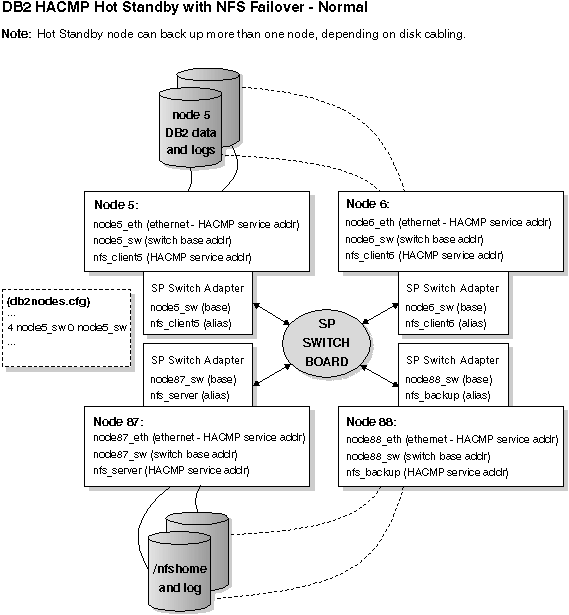
The previous figure and the next figure each have the following notes associated with them:
Figure 75. Hot Standby with NFS Failover - DB2 Failover
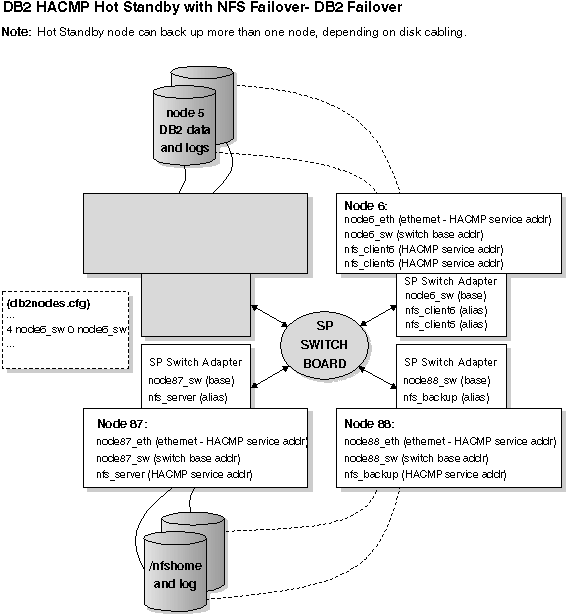
Figure 76. Mutual Takeover without NFS Failover - Normal
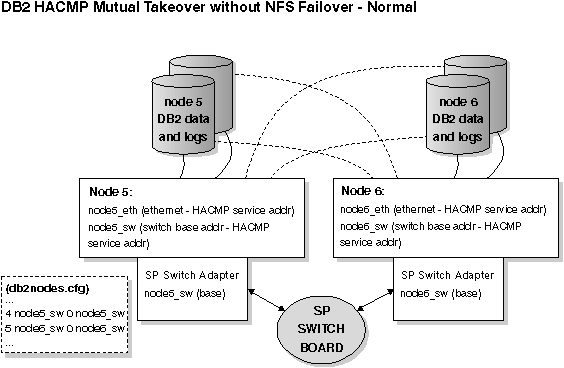
The previous figure and the next figure each have the following notes associated with them:
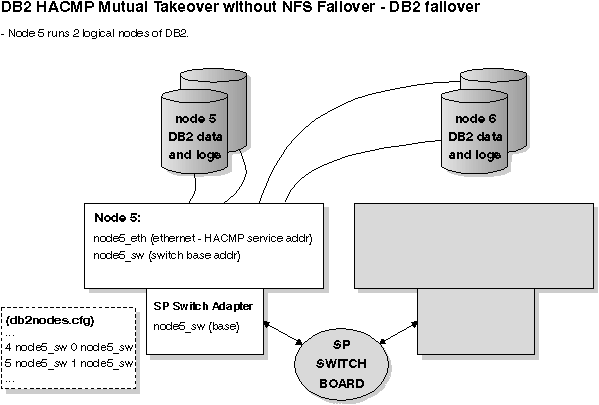
Figure 77. Mutual Takeover without NFS Failover - DB2 Failover
It is recommended that you do not specify HACMP to be started at boot time in /etc/inittab. HACMP should be started manually after the nodes are booted. This allows for non-disruptive maintenance of a failed node.
As an example of "disruptive maintenance", consider the case where a node has a hardware failure and crashed. At such a time, service needs to be performed. Failover would be automatically initiated by HACMP and recovery completed successfully. However, the failed node needs to be fixed. If HACMP was configured to be started on reboot in /etc/inittab, then this node would attempt to reintegrate after boot completion which is not desirable in this situation.
As an example of "non-disruptive maintenance", consider manually starting HACMP on each node. This allows for non-disruptive service of failed nodes since they can be fixed and reintegrated without affecting the other nodes. The ha_cmd script is provided for controlling HACMP start and stop commands from the control workstation.