
When compiling an SQL statement, the SQL optimizer estimates the execution cost of different ways of satisfying your request. Based on this evaluation, the optimizer selects what it believes to be the optimal access plan. An access plan specifies the order of operations required to resolve an SQL statement. When an application program is bound, a package is created. This package contains access plans for all of the static SQL statements in that application program. Access plans for dynamic SQL statements are created at the time that the application is executed.
There are two ways of accessing data in a table: by directly reading the table (relation scan), or by first accessing an index on that table (index scan).
A relation scan occurs when the database manager sequentially accesses every row of a table. See "Index Scan Concepts" to learn how an index scan works and see "Relation Scan versus Index Scan" to understand under what conditions each type of scan is used.
The following topics describe other methods that can also be used in an access plan to access data in a table, and to produce the results for your query:
Other Related Topics:
An index scan occurs when the database manager accesses an index to do any or all of the following:
The following additional topics are provided:
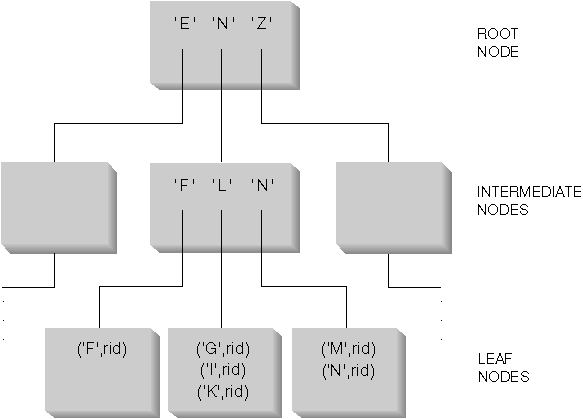
The database manager uses a B+ tree structure for storing its indexes. A B+ tree has one or more levels, as shown in the following diagram (where RID means row ID):
|
The top level is called the root node. The bottom level consists of leaf nodes, where the actual index key values are stored, as well as a pointer to the actual row in the table. Levels between the root and leaf node levels are called intermediate nodes.
In looking for a particular index key value, Index Manager searches the index tree, starting at the root node. The root contains one key for each node at the next level. The value of each of these keys is the largest existing key value for the corresponding node at the next level. For example, if an index has three levels as shown in Figure 44, then to find an index key value, Index Manager would search the root node for the first key value greater than or equal to the key being looked for. This root node key would point to a specific intermediate node. The same procedure would be followed with that intermediate node to determine which leaf node to go to. The final index key would be found in the leaf node. Using Figure 44, the key being looked for is "I". The first key in the root node greater than or equal to "I" is "N". This points to the middle node at the next level. The first key in that intermediate node that is greater than or equal to "I" is "L". This points to a specific leaf node where the index key for "I" along with its corresponding row ID(s) are found (the row ID of the corresponding rows in the base table).
In determining whether an index can be used for a particular query, the optimizer evaluates each column of the index starting with the first column to see if it can be used to satisfy:
A predicate is an element of a search condition in a WHERE clause that expresses or implies a comparison operation. Predicates that can be used to delimit the range of an index scan are those involving an index column in which one of the following is true:
For example, given an index with the following definition:
INDEX IX1: NAME ASC,
DEPT ASC,
MGR DESC,
SALARY DESC,
YEARS ASC
the following predicates could be used in delimiting the range of the scan of index IX1:
WHERE NAME = :hv1
AND DEPT = :hv2
or
WHERE MGR = :hv1
AND NAME = :hv2
AND DEPT = :hv3
Note that in the second example the WHERE predicates do not have to be specified in the same order as the key columns appear in the index. And, although host variables are used in the examples, parameter markers, expressions, or constants would have the same effect.
In the following WHERE clause, only the predicates for NAME and DEPT would be used in delimiting the range of the index scan, but not the predicates for SALARY or YEARS:
WHERE NAME = :hv1
AND DEPT = :hv2
AND SALARY = :hv4
AND YEARS = :hv5
This is because there is a key column (MGR) separating these columns from the first two index key columns, so the ordering would be off. However, once the range is determined by the NAME = :hv1 and DEPT = :hv2 predicates, the remaining predicates can be evaluated against the remaining index key columns.
In addition to the equality predicates described above, certain inequality predicates may be used to delimit the range of an index scan. The following discusses the two types of inequality predicates: strict inequality and inclusive inequality.
Strict Inequality Predicates: The strict inequality operators which can be used for range delimiting predicates are > and <.
For delimiting a range for an index scan, only one column with strict inequality predicates will be considered. In the following example, the predicates on the NAME and DEPT columns can be used to delimit the range, but the predicate on the MGR column cannot be used.
WHERE NAME = :hv1
AND DEPT > :hv2
AND DEPT < :hv3
AND MGR < :hv4
Inclusive Inequality Predicates: The following are inclusive inequality operators which can be used for range delimiting predicates:
For delimiting a range for an index scan, multiple columns with inclusive inequality predicates will be considered. In the following example, all of the predicates can be used to delimit the range of the index scan:
WHERE NAME = :hv1
AND DEPT >= :hv2
AND DEPT <= :hv3
AND MGR <= :hv4
To further illustrate this example, suppose that :hv2 = 404, :hv3 = 406, and :hv4 = 12345. The database manager will scan the index for all of departments 404 and 405, but it will stop scanning department 406 when it reaches the first manager that has an employee number (MGR column) greater than 12345.
For additional information, see "Range Delimiting and Index SARGable Predicates".
If the query involves ordering, an index can be used to order the data if the ordering columns appear consecutively in the index, starting from the first index key column. (Ordering or sorting can result from operations such as ORDER BY, DISTINCT, GROUP BY, "= ANY" subquery, "> ALL" subquery, "< ALL" subquery, INTERSECT or EXCEPT, UNION.) An exception to this is when the index key columns are compared for equality against "constant values" (that is, any expression that evaluates to a constant). In this case the ordering column can be other than the first index key columns. For example, in the query:
WHERE NAME = 'JONES'
AND DEPT = 'D93'
ORDER BY MGR
the index could be used to order the rows since NAME and DEPT will always be the same values and will thus be ordered. Another way of saying this is that the preceding WHERE and ORDER BY clauses are equivalent to:
WHERE NAME = 'JONES'
AND DEPT = 'D93'
ORDER BY NAME, DEPT, MGR
A unique index can also be used to truncate an order requirement. For example, given the following index definition and order by clause:
UNIQUE INDEX IX0: PROJNO ASC
SELECT PROJNO, PROJNAME, DEPTNO
FROM PROJECT
ORDER BY PROJNO, PROJNAME
additional ordering on the PROJNAME column is not required since the IX0 index ensures that PROJNO is unique. This uniqueness ensures that there is only one PROJNAME value for each PROJNO value.
In some cases, all of the required data can be retrieved from the index without accessing the table. This is known as an index-only access.
To illustrate an index-only access, consider the following index definition:
INDEX IX1: NAME ASC,
DEPT ASC,
MGR DESC,
SALARY DESC,
YEARS ASC
and the following query can be satisfied by accessing only the index, and without reading the base table:
SELECT NAME, DEPT, MGR, SALARY
FROM EMPLOYEE
WHERE NAME = 'SMITH'
In other cases, there may be columns that do not appear in the index. To obtain the data for these columns, rows of the base table must be read. For example, given the IX1 index, the following query needs to access the base table to obtain the PHONENO and HIREDATE column data:
SELECT NAME, DEPT, MGR, SALARY, PHONENO, HIREDATE
FROM EMPLOYEE
WHERE NAME = 'SMITH'
By creating a unique index with include columns, you can improve the performance of data retrieval by increasing the number of access attempts based solely on indexes.
To illustrate the use of include columns, consider the following index definition:
CREATE UNIQUE INDEX IX1 ON EMPLOYEE
(NAME ASC)
INCLUDE (DEPT, MGR, SALARY, YEARS)
This creates a unique index which enforces uniqueness of the NAME column yet stores and maintains data for DEPT, MGR, SALARY, and YEARS columns.
The following query can be statisfied by accessing only the index and without reading the base table:
SELECT NAME, DEPT, MGR, SALARY
FROM EMPLOYEE
WHERE NAME='SMITH'
In all of the above examples, a single index scan was performed to produce the results. To satisfy the predicates of a WHERE clause, the optimizer can choose to scan multiple indexes. For example, given the following two index definitions:
INDEX IX2: DEPT ASC
INDEX IX3: JOB ASC,
YEARS ASC
the following predicates could be resolved using these two indexes:
WHERE DEPT = :hv1
OR (JOB = :hv2
AND YEARS >= :hv3)
In this example, scanning index IX2 will produce a list of row IDs (RIDs) that satisfy the DEPT = :hv1 predicate. Scanning index IX3 will produce a list of RIDs satisfying the JOB = :hv2 AND YEARS >= :hv3 predicate. These two lists of RIDs can be combined and duplicates removed before accessing the table. This is known as index ORing.
Index ORing may also be used for predicates using the IN expression, as in the following example:
WHERE DEPT IN (:hv1, :hv2, :hv3)
With index ORing you are looking to eliminate duplicate RIDs, however with index ANDing you are looking for RIDs that occur in every index scanned. Index ANDing may occur with applications where there are multiple indexes on corresponding columns within the same table and a query using multiple "and" predicates is run against that table. Multiple index scans against each indexed column in such a query produce qualifying rows that have their RID values hashed to dynamically create bitmaps. The second bitmap is used to probe the first bitmap to generate the qualifying rows that are fetched to create the final returned data set.
For example, given the following two index definitions:
INDEX IX4: SALARY ASC INDEX IX5: COMM ASC
the following predicates could be resolved using these two indexes:
WHERE SALARY BETWEEN 20000 AND 30000
AND COMM BETWEEN 1000 AND 3000
In this example, scanning index IX4 produces a dynamic bitmap index satisfying the SALARY BETWEEN 20000 AND 30000 predicate. Scanning IX5 and probing the dynamic bitmap index for IX4 results in the list of qualifying RIDs that satisfy both predicates. This is known as "dynamic bitmap ANDing". It only occurs if the table has sufficient cardinality and the columns have sufficient values in the qualifying range, or sufficient duplication if equality predicates are used.
| Note: | In the accessing of any single table, DB2 does not combine index ANDing and index ORing. |
When selecting the access plan, the optimizer considers the I/O cost of fetching pages from disk to the buffer pool. In its calculations, the optimizer will estimate the number of I/Os required to satisfy a query. This estimate includes a prediction of buffer pool usage, since additional I/Os are not required to read rows in a page that is already in the buffer pool.
For index scans, the optimizer uses information from the system catalog tables (SYSCAT.INDEXES) to help estimate I/O cost of reading data pages into the buffer pool. The following columns from the SYSCAT.INDEXES table are used:
or
If statistics are not available, the optimizer will use default values for the statistics, which assume poor clustering of the data to the index. See also Chapter 12. "System Catalog Statistics" and "Collecting Statistics Using the RUNSTATS Utility".
You can specify a clustering index that will be used both to cluster the rows during a table reorganization and to preserve this characteristic during insert processing. (See "Reorganizing Table Data" for information about table reorganization.) Subsequent updates and inserts may make the index less well clustered (as measured by the statistics gathered by RUNSTATS), so you may need to periodically reorganize the table. To reduce the frequency of reorganization on a volatile database, use the PCTFREE parameter when altering a table. This will allow for additional inserts to be clustered with the existing data.
The degree to which the data is clustered with respect to the index can have a significant impact on performance and you should try to keep one of the indexes on the table close to 100 percent clustered.
In general, only one index can be one hundred percent clustered, except in those cases where the keys are a superset of the keys of the clustering index; or, where there is de facto correlation between the key columns of the two indexes.
See "Performance Tips for Administering Indexes" for more information on performance reasons to use clustering indexes. Refer to the SQL Reference, CREATE INDEX, for more information on how to create a clustering index.
Clustering Page Reads Using List Prefetch: If the optimizer uses an index to access rows, it can defer reading the data pages until all the RIDs (row identifiers) have been obtained from the index. For example, given the previously defined index IX1:
INDEX IX1: NAME ASC,
DEPT ASC,
MGR DESC,
SALARY DESC,
YEARS ASC
and the following search criteria:
WHERE NAME BETWEEN 'A' and 'I'
the optimizer could perform an index scan on IX1 to determine the rows (and data pages) to retrieve. If the data was not clustered according to this index, list prefetch will include a step to sort the list of RIDs obtained from the index scan. See "Understanding List Prefetching" for more information.
When appropriate, the database manager detects sequential access to index pages and will generate prefetch requests. This will significantly reduce the elapsed time for nonselective index scans, and selective index scans accessing a significant portion of the index.
The optimizer uses index statistics such as DENSITY and SEQUENTIAL_PAGES, the characteristics of the table spaces in which the index resides, and the effect of any range delimiting predicates, to estimate the amount of index page prefetch that will occur. These estimates are factored into the overall cost estimate for using a particular index.
See "Understanding Sequential Prefetching" for more information.
The optimizer will choose a relation scan when an index cannot be used for the query, or if the optimizer determines that an index scan would be more costly. An index scan could be more costly when:
You may use the SQL Explain facilities to determine whether your access plan uses a relation scan or an index scan. See Chapter 14. "SQL Explain Facility".
The query rewrite will access a summary table if it determines that the query can be answered by using the data in the summary table instead of accessing the base table or tables.
Notes:
Following is an example of a multidimensional analysis that could take advantage of summary tables. A summary table is created with the sum and count of sales for each level of:
A wide range of queries can pick up their answers from this stored aggregate data. The following example calculates the sum of product group sales, by state, by month. Queries that can take advantage of such pre-computed sums would include:
While the precise answer is not included in the summary table for any of these queries, the cost of computing the answer using the summary table could be significantly less than using a large base table, because a portion of the answer is already computed. For example:
CREATE TABLE PG_SALESSUM
AS (
SELECT l.id AS prodline, pg.id AS pgroup,
loc.country, loc.state
YEAR(pdate) AS year, MONTH(pdate) AS month,
SUM(ti.amount) AS amount,
COUNT(*) AS count
FROM cube.transitem AS ti, cube.trans AS t,
cube.loc AS loc, cube.pgroup AS pg,
cube.prodline AS l
WHERE ti.transid = t.id
AND ti.pgid = pg.id
AND pg.lineid = l.id
AND t.locid = loc.id
AND YEAR(pdate) > 1990
GROUP BY l.id, pg.id, loc.country, loc.state,
year(pdate), month(pdate)
)
DATA INITIALLY DEFERRED REFRESH DEFERRED;
REFRESH TABLE SALESCUBE;
The following are sample queries that would obtain significant performance improvements because they are able to use the results in the summary table that are already computed. The first example returns the total sales for 1995 and 1996:
SET CURRENT REFRESH AGE=ANY
SELECT YEAR(pdate) AS year, SUM(ti.amount) AS amount
FROM cube.transitem AS ti, cube.trans AS t,
cube.loc AS loc, cube.pgroup AS pg,
cube.prodline AS l
WHERE ti.transid = t.id
AND ti.pgid = pg.id
AND pg.lineid = l.id
AND t.locid = loc.id
AND YEAR(pdate) IN (1995, 1996)
GROUP BY year(pdate);
The second example returns the total sales by product group for 1995 and 1996:
SET CURRENT REFRESH AGE=ANY
SELECT pg.id AS "PRODUCT GROUP",
SUM(ti.amount) AS amount
FROM cube.transitem AS ti, cube.trans AS t,
cube.loc AS loc, cube.pgroup AS pg,
cube.prodline AS l
WHERE ti.transid = t.id
AND ti.pgid = pg.id
AND pg.lineid = l.id
AND t.locid = loc.id
AND YEAR(pdate) IN (1995, 1996)
GROUP BY pg.id;
A user application requests a set of rows from the database with an SQL statement, qualifying the specific rows desired through the use of predicates. When the optimizer decides how to evaluate an SQL statement, each predicate falls into one of four categories. The category is determined by how and when that predicate is used in the evaluation process. These categories are listed below, ordered in terms of performance from best to worst:
SARGable refers to something that can be used as a search argument.
"Summary of Predicate Usage" provides a comparison of the characteristics that affect the performance of the various predicate categories.
Range delimiting predicates are those used to bracket an index scan. They provide start and/or stop key values for the index search. Index SARGable predicates are not used to bracket a search, but can be evaluated from the index because the columns involved in the predicate are part of the index key. For example, given the previously defined index IX1 (in the section "Index Scan Concepts") and the following WHERE clause:
WHERE NAME = :hv1
AND DEPT = :hv2
AND YEARS > :hv5
the first two predicates (NAME = :hv1, DEPT = :hv2) would be range delimiting predicates, while YEARS > :hv5 would be an index SARGable predicate.
The database manager will make use of the index data in evaluating these predicates rather than reading the base table. These index SARGable predicates reduce the number of data pages accessed by reducing the set of rows that need to be read from the table. These types of predicates do not affect the number of index pages that are accessed.
Predicates that cannot be evaluated by Index Manager, but can be evaluated by Data Management Services are called data SARGable predicates. Typically, these predicates require the access of individual rows from a base table. If required, Data Management Services will retrieve the columns needed to evaluate the predicate, as well as any others to satisfy the columns in the SELECT list that could not be obtained from the index.
For example, given a single index defined on the PROJECT table:
INDEX IX0: PROJNO ASC
And given the following query, the DEPTNO = 'D11' predicate is considered to be data SARGable.
SELECT PROJNO, PROJNAME, RESPEMP
FROM PROJECT
WHERE DEPTNO = 'D11'
ORDER BY PROJNO
Residual predicates, typically, are those that require I/O beyond the simple accessing of a base table. Examples of residual predicates include those using correlated subqueries, using quantified subqueries (subqueries with ANY, ALL, SOME, or IN), or reading LONG VARCHAR or LOB data (stored in a file separate from the table). These predicates are evaluated by Relational Data Services.
Sometimes predicates, which are applied to the index only, have to be reapplied when the data page is accessed. For example, access plans using index ORing or index ANDing, (see "Multiple Index Access"), always reapply the predicates as residual predicates, when the data page is accessed.
The use of predicates in a query can help to reduce the amount of data read to
satisfy the query. Different categories of predicates have different
impacts on the performance of a query and these impacts are considered by the
optimizer. The following table shows the ranking of the different types
of predicates and how each type of predicate can influence performance.
Table 44. Summary of Predicate Type Characteristics
| Characteristic | Predicate Type | |||
|---|---|---|---|---|
| Range Delimiting | Index SARGable | Data SARGable | Residual | |
| Reduce index I/O | Yes | No | No | No |
| Reduce data page I/O | Yes | Yes | No | No |
| Reduce number of rows passed internally | Yes | Yes | Yes | No |
| Reduce number of qualifying rows | Yes | Yes | Yes | Yes |
A join is where rows from one table are concatenated to rows of one or more other tables. For example, given the following two tables:
TABLE1 TABLE2
----------------- -----------------
PROJ PROJ_ID PROJ_ID NAME
------ ------- ------- ------
A 1 1 Sam
B 2 3 Joe
C 3 4 Mary
D 4 1 Sue
2 Mike
Joining Table1 and Table2 where the ID columns are equal would be represented by the following SQL statement:
SELECT PROJ, x.PROJ_ID, NAME
FROM TABLE1 x, TABLE2 y
WHERE x.PROJ_ID = y.PROJ_ID
and would yield the following set of result rows:
PROJ PROJ_ID NAME
------ ------- ------
A 1 Sam
A 1 Sue
B 2 Mike
C 3 Joe
D 4 Mary
When joining two tables, one table is selected as the outer table and the other as the inner. The outer table is accessed first and is only scanned once. Whether the inner table is scanned multiple times depends on the type of join and which indexes are present. Whether your query joins two tables or more than two tables, the optimizer will only join two tables at a time. If needed, temporary, intermediary results tables will be created.
The optimizer will choose one of the two join methods (nested loop join or merge join) depending on the existence of a join predicate (defined in "Merge Join"), as well as various costs involved as determined by table and index statistics.
A nested loop join is performed in one of two ways:
For example, if column A in tables T1 and T2 has the following values:
Outer Table T1: column A Inner Table T2: column A
------------------------ ------------------------
2 3
3 2
3 2
3
1
The steps for doing the nested loop:
This method can be used for the specified predicates if there is a predicate of the following form:
expr(outer_table.column) relop inner_table.column
where relop is a relative operator (for example =, >, >=, <, or <=) and expr is a valid expression on the outer table. The following are examples:
OUTER.C1 + OUTER.C2 <= INNER.C1
and
OUTER.C4 < INNER.C3
This method could be a way to significantly reduce the number of rows accessed in the inner table for each access of the outer table (although it depends on a number of factors, including the selectivity of the join predicate).
When evaluating a nested loop join, the optimizer will also determine whether or not to sort the outer table before performing the join. By ordering the outer table, based on the join columns, the number of read operations to access pages from disk for the inner table may be reduced, since it is more likely they will already be in the buffer pool. If the join uses a highly clustered index to access the inner table, the number of index pages accessed may be minimized if the outer table has been sorted.
In addition, the optimizer may also choose to perform the sort before the join, if it expects that the join will make a later sort more expensive. A later sort could be required to support a GROUP BY, DISTINCT, ORDER BY or merge join.
Merge join (sometimes known as merge scan join or sort merge join) requires a predicate of the form table1.column = table2.column. This is called an equality join predicate. Merge join requires ordered input on the joining columns, either through index access or by sorting. In order for a merge join to be used, the join column cannot be a LONG field column or a large object (LOB) column.
The joined tables are scanned simultaneously. The outer table of the merge join is scanned just once. The inner table is also scanned once unless there are repeated values in the outer table. If there are repeated values in the outer table, a group of rows in the inner table may be scanned again. For example, if column A in tables T1 and T2 has the following values:
Outer Table T1: column A Inner Table T2: column A
------------------------ ------------------------
2 1
3 2
3 2
3
3
The steps for doing the merge join are:
Hash join requires one or more predicates of the form table1.columnX = table2.columnY, and for which the column types are the same. For columns of type CHAR, the length must be the same. For columns of type DECIMAL, the precision and scale must be the same. The column type cannot be a LONG field column, or a large object (LOB) column.
First, one table (called the INNER table) is scanned and the rows copied into memory buffers drawn from the sort heap allocation (see the "Sort Heap Size (sortheap)" database configuration parameter). The memory buffers are divided into partitions based on a "hash code" computed from the column(s) of the join predicate(s). If the size of the first table exceeds the available sort heap space, buffers from selected partitions are written to temporary tables. After finishing the processing of the INNER table, the second table (called the OUTER table) is scanned. Rows of the OUTER table are matched to rows from the INNER table by first comparing a "hash code" generated from the columns of the join predicate(s). Then, if the "hash code" of the OUTER row matches the "hash code" of the INNER row, the actual join predicate columns are compared.
OUTER table rows corresponding to partitions not written to a temporary table are matched immediately with INNER table rows in memory. Otherwise, if the corresponding INNER table partition was written to a temporary table, the OUTER row is also written to a temporary table. Finally, matching pairs of partitions from temporary tables are read and the "hash codes" of their rows are matched and join predicates checked.
When joining, how are the inner and outer tables determined? The following are general guidelines for how the optimizer decides which table will be the inner and which will be the outer.
In the case of a hash join, the inner table is kept in memory buffers. If there are too few memory buffers, then the hash join is obliged to spill. The optimizer attempts to avoid this and so will pick the smaller of the two tables as the inner table, and the larger one as the outer table.
The order in which the tables are accessed is particularly important for a nested loop join because the outer table is accessed once but the inner table is accessed once for each row of the outer table. The optimizer chooses the outer and inner tables based on cost estimates. These cost estimates are influenced by the following factors:
The smaller table is often chosen to be the outer table to reduce the number of times the inner table must be re-accessed. However, prefetch can cause just the opposite to be true. Prefetching can reduce the cost of accessing a large table substantially. However, usually prefetching is only effective for the outer table of a join. Therefore, the larger table may be accessed first. See "Prefetching Data into the Buffer Pool" for more information.
A table is more likely to be chosen as the outer table if selective predicates can be applied to it because the inner table is only accessed for rows which satisfy the predicates applied to the outer table.
If the entire inner table must be scanned for each row of the outer table (that is, an index lookup cannot be performed on the inner table), the smaller of the two tables may be chosen as the inner table to take advantage of buffering. This will be influenced by table size and buffer pool size. Note that since join decisions are influenced by buffer pool size, the access plan for your applications may change, if you rebind your applications to the database, after changing the buffer pool size.
Your ability to create more than one buffer pool, and change the size of that buffer pool, and control the table spaces that use that buffer pool, can affect when buffering is used within inner and outer tables.
If it is possible to do an index lookup on one of the tables, then that table is a good candidate to use as the inner table. It could then be accessed with an index key lookup using the outer table's join key predicate as one of the key values. If a table does not have an index, it would not be a good candidate for the inner table since in that case the entire inner table would have to be scanned for every row of the outer table.
The table associated with a required order might be assessed first. For example, if the output of the join between t1 and t2 was to be ordered on t1.c, accessing t1 as the outer with an index on t1.c might be a good choice. The output of the join would be ordered and no sort would be required.
SELECT * FROM t1, t2
WHERE t1.a = t2.b
ORDER BY t1.c
The order in which the tables are accessed is somewhat less important for a merge join because both the inner and outer tables are read only once. However, portions of the inner table which correspond to duplicate join values in the outer are kept in an in-memory buffer. The buffer is reread if the next outer row is the same as the previous outer row, otherwise the buffer is reset. If the number of duplicate join values exceeds the capacity of the in-memory buffer, not all of the duplicates are kept. This will only happen when the duplication on any value is large and the value has a matching value in the outer table.
With all of these considerations for duplicate values, in most cases it is the table with fewer duplicates that will be chosen as the outer table in a join. Ultimately, however, the optimizer chooses the outer and inner tables based on detailed cost estimates.
The optimizer can determine optimal join methods using different search strategies. The search strategy that will be used is determined by the optimization class in use (see "Adjusting the Optimization Class"). The search strategies and their characteristics are:
The join enumeration algorithm is a key determinant of the number of plan combinations that are explored by the optimizer.
In general, the tables referenced in a query should be connected by join predicates. If two tables are joined without the presence of a join predicate, the Cartesian product of the two tables is formed. That is, every qualifying row of the first table is joined with every qualifying row of the second, creating a result table consisting of the cross product of the size of the two tables that is typically very large. Since such a plan is unlikely to perform very well, the optimizer avoids even determining the cost of such an access plan. The only exception to this occurs when the optimization class is set to 9, or the following special case for "Star Schemas". For more information, see "Adjusting the Optimization Class".
The cases where access plans involving Cartesian products perform well are usually large decision support databases designed with the Star Schema technique. The star schema is a database design in which the bulk of the raw data is kept in a single large table with many columns and is commonly known as a "fact" table. Many of the columns contain encoded values that characterize the dimensions of the particular datum stored in the fact table. In order to allow easy analysis of some subset of the facts, dimension tables are used to decode the encoded values. A typical query would consist of multiple local predicates referencing decoded values in the dimension tables and would contain join predicates connecting the dimension tables to the fact table. For these kinds of queries it may be beneficial to perform the Cartesian product of multiple small dimension tables before accessing the large fact table. This technique is beneficial when multiple join predicates match a multi-column index.
DB2 has the ability to recognize queries against databases designed with star schemas having at least three (3) dimension tables, and to increase the search space to include potential plans that involve forming the Cartesian product of dimension tables. If the plan involving the Cartesian products has the lowest estimated cost, it will be selected by the optimizer.
The Star Schema technique discussed above was focussed on the situation where primary key indexes were used in the join. Another scenario could involve foreign key indexes. Given that the foreign key columns in the fact table are single-column indexes and that there is a relatively high selectivity across all dimension tables, the following Star Join technique can be used:
Using this technique, there is no requirement to have multi-column indexes.
Another important parameter determines the shape of the sequence of joins in a query. The result of joining a pair of tables is a new table known as a composite. Typically, this resulting composite table becomes the outer table of a join with another inner table. This is known as a "composite outer". In some situations, particularly when using the greedy join enumeration technique, it is useful to take the result of joining two tables and make that the inner table of a later join. When the inner table of a join itself consists of the result of joining two or more tables, we say that the plan contains a "composite inner". For example, in the following query:
SELECT COUNT(*)
FROM T1, T2, T3, T4
WHERE T1.A = T2.A AND
T3.A = T4.A AND
T2.Z = T3.Z
it may be beneficial to join table T1 and T2 ( T1xT2 ), then join T3 to T4 ( T3xT4 ) and finally select the first join result as the outer and the second join result as the inner. In the final plan ( (T1xT2) x (T3xT4) ) the join result (T3xT4) is known as a composite inner. Depending on the query optimization class, the optimizer places different constraints on the maximum number of tables that may be the inner table of a join. Composite inners are allowed with optimization classes 5, 7, and 9.
By using replicated summary tables in a partitioned database environment, you can improve performance by having the database manage pre-computed values of the base table data. For example, the query below would benefit from creating the replicated summary table below. The following assumptions are made:
CREATE TABLE R_EMPLOYEE
AS (
SELECT EMPNO, FIRSTNME, MIDINIT, LASTNAME, WORKDEPT
FROM EMPLOYEE
)
DATA INITIALLY DEFERRED REFRESH IMMEDIATE
IN REGIONTABLESPACE
REPLICATED;
REFRESH TABLE R_EMPLOYEE;
The following example calculates sales by employee, the total for the department, and the grand total:
SELECT d.mgrno, e.empno, SUM(s.sales)
FROM department AS d, employee AS e, sales as S
WHERE s.sales_person = e.lastname
AND e.workdept = d.deptno
GROUP BY ROLLUP(d.mgrno, e.empno)
ORDER BY d.mgrno, e.empno;
Instead of using the EMPLOYEE table, which is on only one database partition, the database manager will use the R_EMPLOYEE table, which is replicated on each of the database partitions that the SALES tables is on. The performance enhancement occurs because the employee information does not have to be moved across the network to each database partition to calculate the join.
The following sections describe the join strategies that are possible in a partitioned database environment. The DB2 optimizer automatically selects the best join strategy depending on the requirements of each application. The join strategies are presented here to help you understand what is happening in each strategy. A "table queue" is a mechanism for transferring rows between database partitions, or between processors in a single partition database.
In the descriptions that follow, a directed table queue is one whose rows are hashed to one of the receiving database partitions. A broadcast table queue is one whose rows are sent to all of the receiving database partitions (that is, it is not hashed). In the diagrams for this section q1, q2, and q3 refer to table queues in the examples. Also the tables that are referenced are divided across two database partitions for the purpose of these scenarios. The arrows indicate the direction in which the table queues are sent. The coordinator node is partition 0.
One consideration for those tables involved in frequent joins in a partitioned database is that of table collocation. Table collocation provides the means in a partitioned database to locate data from one table with the data from another table at the same partition based on the same partitioning key. Once collocated, data to be joined can participate in a query without having to be moved to another database partition as part of the query activity. Only the answer set for the join is moved to the coordinator node. See "Table Collocation" for more information on this subject.
For information on join dependencies, refer to the SQL Reference manual.
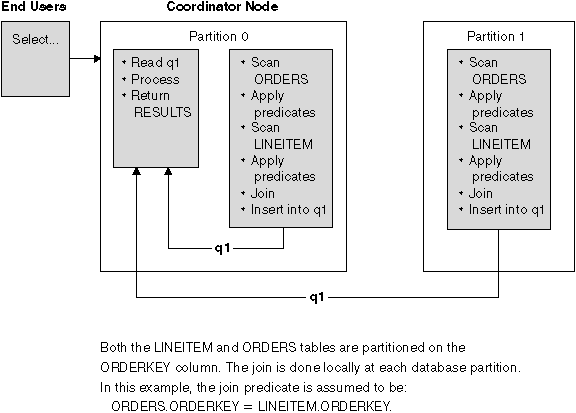
For the optimizer to consider a collocated join, the joined tables must be collocated, and all pairs of the corresponding partitioning key must participate in the equijoin predicates. An example is shown in Figure 45.
| Note: | Replicated summary tables enhance the likelihood of collocated joins. See "Replicated Summary Tables" for more information. |
Figure 45. Collocated Join Example
 |
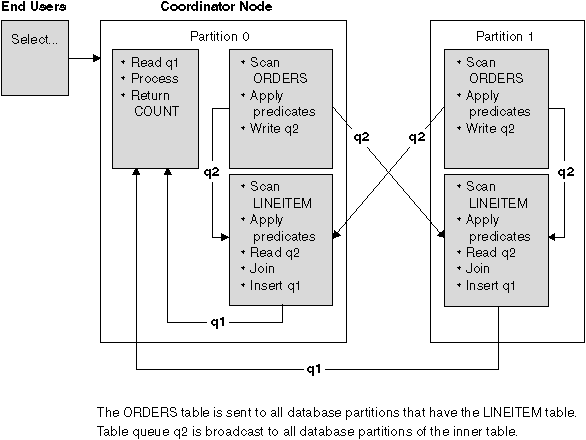
This parallel join strategy can be used if there are no equijoin predicates between the joined tables. It can also be used in other situations in which it is the most cost-effective join method. Typically, this would occur when there is one very large table and one very small table, neither of which is partitioned on the join predicate columns. Rather than partition both tables, it may be "cheaper" to broadcast the smaller table to the larger table. An example is shown in Figure 46.
Figure 46. Broadcast Outer-Table Join Example
 |
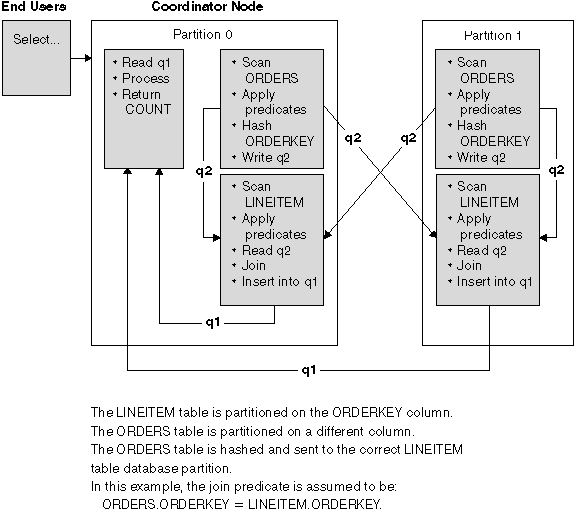
In this join strategy, each row of the outer table is sent to one database partition of the inner table (based on the partitioning attributes of the inner table). The join occurs on this database partition. An example is shown in Figure 47.
Figure 47. Directed Outer-Table Join Example
 |
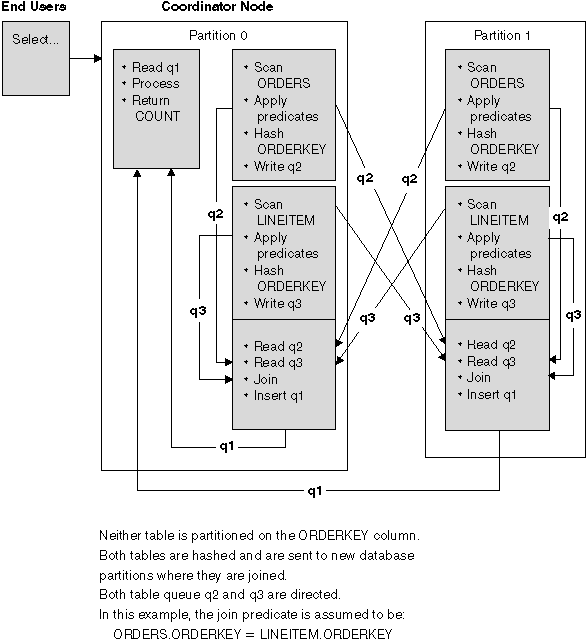
With this strategy, rows of the outer and inner tables are directed to a set of database partitions, based on the values of the joining columns. The join occurs on these database partitions. An example is shown in Figure 48.
Figure 48. Directed Inner-Table and Outer-Table Join Example
 |
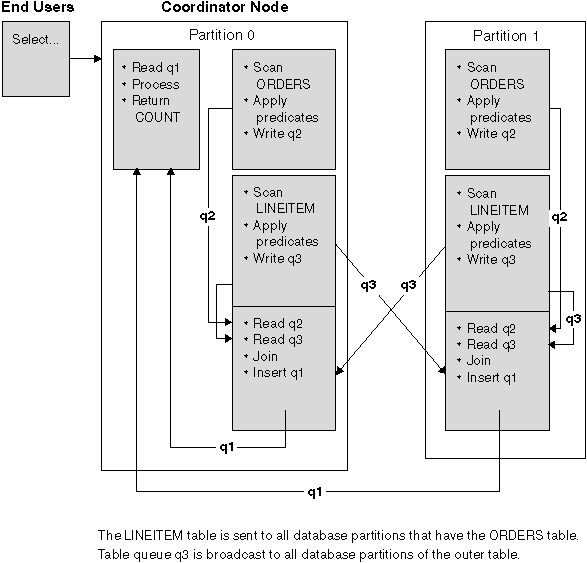
With this strategy, the inner table is broadcast to all the database partitions of the outer join table. An example is shown in Figure 49.
Figure 49. Broadcast Inner-Table Join Example
 |
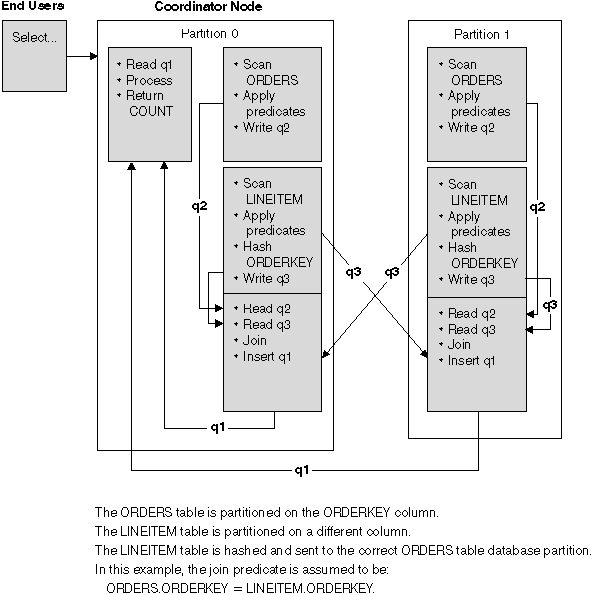
With this strategy, each row of the inner table is sent to one database partition of the outer join table (based on the partitioning attributes of the outer table). The join occurs on this database partition. An example is shown in Figure 50.
Figure 50. Directed Inner-Table Join Example
 |
A table queue is used:
Each table queue is used to pass the data in a single direction.
The compiler decides where table queues are required, and includes them in the plan. When the plan is executed, the connections between the database partitions initiate the table queues. The table queues close as processes end.
There are several types of table queues:
Asynchronous table queues are used when you specify the FOR FETCH ONLY clause on the SELECT statement. If you are only fetching rows, the asynchronous table queue is faster.
Synchronous table queues are used when you do not specify the FOR FETCH ONLY clause on the SELECT statement. In a partitioned database environment, if you are updating rows, the database manager will use the synchronous table queues.
When the optimizer chooses an access plan, it considers the performance impact of sorting data. Sorting occurs when no index exists to satisfy the requested ordering of fetched rows. Sorting could also occur when the sort is determined by the optimizer to be less expensive than an index scan. The optimizer may carry out one of the following actions when sorting the data:
At the completion of a sort, if the final sorted list of data can be read in a single sequential pass, the results can be piped. Piping is quicker than the use of other (non-piped) means of communicating the results of the sort. The optimizer chooses to pipe the results of a sort whenever possible.
Independent of whether a sort is piped, the time to sort will depend on a number of factors, including the number of rows to be sorted, the key size and the row width. If the rows to be sorted occupy more than the space available in the sort heap, several sort passes are performed, where each pass sorts a subset of the entire set of rows. Each sort pass is stored in a temporary table in the buffer pool. (As part of the buffer pool management, it is possible that pages from this temporary table may be written to disk.) Once all the sort passes are complete, these sorted subsets must be merged into a single sorted set of rows. If the sort is piped, as the rows are merged they are handed directly to Relational Data Services.
For more information, see "Looking for Indicators of Sorting Performance Problems", or the discussion of the sortheap configuration parameter in "Configuration Parameters Affecting Query Optimization".
In some cases, the optimizer can choose to "push-down" a sort or aggregation operation to the Data Management Services component from the Relational Data Services component. Pushing down these operations improves performance by allowing the Data Management Services component to pass data directly to a sort or aggregation routine. Without this push-down, Data Management Services would first pass this data to Relational Data Services, which would then interface with the sort or aggregation routines. For example, the following query benefits from this optimization:
SELECT WORKDEPT, AVG(SALARY) AS AVG_DEPT_SALARY
FROM EMPLOYEE
GROUP BY WORKDEPT
When sorting is used to produce the order required for a GROUP BY operation the optimizer has the option of performing some or all of the GROUP BY's aggregation while doing the sort. This is advantageous if the number of rows in each group is large. It is even more advantageous if doing some of the grouping during the sor reduces or eliminates the need for the sort to spill to disk.
When aggregation in sort is used, there are up to three (3) stages of aggregation required to ensure proper results are calculated. The first stage of aggregation, "partial aggregation," calculates the aggregate values until the sort heap is filled. Partial aggregation is the process whereby unaggregated data is taken in and partial aggregates are produced. If the sort heap is filled, the rest of the data is spilled to disk and includes all of the partial aggregations that have been calculated in the current filling of the sort heap. Following the reset of the sort heap, new aggregations are started.
The second stage of aggregation, "intermediate aggregation," takes all of the spilled sort runs, and aggregates further on the grouping keys. The aggregation cannot be completed because the grouping key columns are a subset of the partitioning key columns. Intermediate aggregation takes in existing partial aggregates and produce new partial aggregates. This stage is optional, and is used for both intra-partition parallelism, and for inter-partition parallelism. In the last case, the grouping is finished when a global grouping key is available. In inter-partition parallelism, this would occur when the grouping key is a subset of the partitioning key dividing groups across partitions, and thus requiring repartitioning to complete the aggregation. A similar case exists in intra-partition parallelism when each agent finishes merging it's spilled sort runs before reducing to a single agent to complete the aggregation.
The last stage of aggregation, "final aggregation," takes all of the partial aggregates and completes the aggregation. Final aggregation takes in partial aggregates and produces final aggregates. This step always takes place in a GROUP BY operator. Sort cannot do complete aggregation because there is no way to guarantee that the sort will not split. Complete aggregation takes in unaggregated data and produces final aggregates. This method of aggregation is typically used when grouping data that is already in the correct order and when partitioning does not prohibit it's use.