
Creating a database sets up all the system catalog tables that are needed by the database and allocates the database recovery log. The database configuration file is created, and the default values are set. The database manager will also bind the database utilities to the database.
The following database privileges are automatically granted to PUBLIC: CREATETAB, BINDADD, CONNECT, and IMPLICIT_SCHEMA. SELECT privilege on the system catalog views is also granted to PUBLIC.
The following command line processor command creates a database called personl, in the default location, with the associated comment "Personnel DB for BSchiefer Co".
create database personl
with "Personnel DB for BSchiefer Co"
The tasks carried out by the database manager when you create a database are discussed in the following sections:
For additional information related to the physical implementation of your database, see Chapter 2. "Designing Your Physical Database".
If you wish to create a database in a different, possibly remote, database manager instance, see "Using Multiple Instances of the Database Manager". This topic also provides an introduction to the command you need to use if you want to perform any instance-level administration against an instance other than your default instance, including remote instances.
| Note: | See the Command Reference for information about the default database location and about specifying a different location with the CREATE DATABASE command. |
When a database is initially created, database partitions are created for all partitions specified in the db2nodes.cfg file. Other partitions can be added or removed with the ADD NODE and DROP NODE commands.
When a database is initially created, three table spaces are defined:
If you do not specify any table space parameters with the CREATE DATABASE command, the database manager will create these table spaces using system managed storage (SMS) directory containers. These directory containers will be created in the subdirectory created for the database (see "Database Physical Directories"). The extent size for these table spaces will be set to the default.
If you do not want to use the default definition for these table spaces, you may specify their characteristics on the CREATE DATABASE command. For example, the following command could be used to create your database on OS/2:
CREATE DATABASE PERSONL
CATALOG TABLESPACE
MANAGED BY SYSTEM USING ('d:\pcatalog','e:\pcatalog')
EXTENTSIZE 16 PREFETCHSIZE 32
USER TABLESPACE
MANAGED BY DATABASE USING (FILE'd:\db2data\personl' 5000,
FILE'd:\db2data\personl' 5000)
EXTENTSIZE 32 PREFETCHSIZE 64
TEMPORARY TABLESPACE
MANAGED BY SYSTEM USING ('f:\db2temp\personl')
WITH "Personnel DB for BSchiefer Co"
In this example, the definition for each of the initial table spaces is explicitly provided. You only need to specify the table space definitions for those table spaces for which you do not want to use the default definition.
The coding of the MANAGED BY phrase on the CREATE DATABASE command follows the same format as the MANAGED BY phrase on the CREATE TABLESPACE command. For additional examples, see "Creating a Table Space".
Before creating your database, see "Designing and Choosing Table Spaces".
A set of system catalog tables is created and maintained for each database. These tables contain information about the definitions of the database objects (for example, tables, views, indexes, and packages), and security information about the type of access users have to these objects. These tables are stored in the SYSCATSPACE table space.
These tables are updated during the operation of a database; for example, when a table is created. You cannot explicitly create or drop these tables, but you can query and view their content. When the database is created, in addition to the system catalog table objects, the following database objects are defined in the system catalog:
After your database has been created, you may wish to limit the access to the system catalog views, as described in "Securing the System Catalog Views".
Three directories are used when establishing or setting up a new database.
A local database directory file exists in each path (or drive on other platforms) in which a database has been defined. This directory contains one entry for each database accessible from that location. Each entry contains:
To see the contents of this file for a particular database, issue the following command, where location specifies the location of the database:
LIST DATABASE DIRECTORY ON location
A system database directory file exists for each instance of the database manager, and contains one entry for each database that has been cataloged for this instance. Databases are implicitly cataloged when the CREATE DATABASE command is issued and can also be explicitly cataloged with the CATALOG DATABASE command. For information about cataloging databases, see "Cataloging a Database".
For each database created, an entry is added to the directory containing the following information:
To see the contents of this file, issue the LIST DATABASE DIRECTORY command without specifying the location of the database directory file.
In a partitioned database environment, you must ensure that all database partitions always access the same system database directory file, sqldbdir, in the sqldbdir subdirectory of the home directory for the instance. Unpredictable errors can occur if either the system database directory or the system intention file sqldbins in the same sqldbdir subdirectory are symbolic links to another file that is on a shared file system. These files are described in "Enabling Data Partitioning".
The database manager creates the node directory when the first database partition is cataloged. To catalog a database partition, use the CATALOG NODE command. To list the contents of the local node directory, use the LIST NODE DIRECTORY command. The node directory is created and maintained on each database client. The directory contains an entry for each remote workstation having one or more databases that the client can access. The DB2 client uses the communication end point information in the node directory whenever a database connection or instance attachment is requested.
The entries in the directory also contain information on the type of communication protocol to be used to communicate from the client to the remote database partition. Cataloging a local database partition creates an alias for an instance that resides on the same machine. A local node should be cataloged when there is more than one instance on the same workstation to be accessed from the user's client.
A database recovery log keeps a record of all changes made to a database, including the addition of new tables or updates to existing ones. This log is made up of a number of log extents, each contained in a separate file called a log file.
The database recovery log can be used to ensure that a failure (for example, a system power outage or application error) does not leave the database in an inconsistent state. In case of a failure, the changes already made but not committed are rolled back, and all committed transactions, which may not have been physically written to disk, are redone. These actions ensure the integrity of the database.
For more information, see Chapter 7. "Recovering a Database".
When a database is created, the database manager attempts to bind the utilities in db2ubind.lst to the database. This file is stored in the bnd subdirectory of your sqllib directory.
Binding a utility creates a package, which is an object that includes all the information needed to process specific SQL statements from a single source file.
| Note: | If you wish to use these utilities from a client, you must bind them explicitly. See the Quick Beginnings manual appropriate to your platform for information. |
If for some reason you need to bind or rebind the utilities to a database, issue the following commands using the command line processor:
connect to sample bind @db2ubind.lst
| Note: | You must be in the directory where these files reside to create the packages in the sample database. The bind files are found in the BND subdirectory of the SQLLIB directory. In this example, sample is the name of the database. |
When you create a new database, it is automatically cataloged in the system database directory file. You may also use the CATALOG DATABASE command to explicitly catalog a database in the system database directory file. The CATALOG DATABASE command allows you to catalog a database with a different alias name, or to catalog a database entry that was previously deleted using the UNCATALOG DATABASE command.
The following command line processor command catalogs the personl database as humanres:
catalog database personl as humanres
with "Human Resources Database"
Here, the system database directory entry will have humanres as the database alias, which is different from the database name (personl).
You can also catalog a database on an instance other than the default. In the following example, connections to database B are to INSTANCE_C.
catalog database b as b at node instance_c
| Note: | The CATALOG DATABASE command is also used on client nodes to catalog databases that reside on database server machines. For more information, see the Quick Beginnings manual appropriate to your platform. |
For information on the Distributed Computing Environment (DCE) cell directory, see "DCE Directory Services" and Appendix G. "Using Distributed Computing Environment (DCE) Directory Services".
| Note: | To improve performance, you may cache directory files, including the database directory, in memory. (See "Directory Cache Support (dir_cache)" for information about enabling directory caching.) When directory caching is enabled, a change made to a directory (for example, using a CATALOG DATABASE or UNCATALOG DATABASE command) by another application may not become effective until your application is restarted. To refresh the directory cache used by a command line processor session, issue a db2 terminate command. |
In addition to the application level cache, a database manager level cache is also used for internal, database manager look-up. To refresh this "shared" cache, issue the db2stop and db2start commands.
For more information about directory caching, see "Directory Cache Support (dir_cache)".
DCE is an Open Systems Foundation** (OSF**) architecture that provides tools and services to support the creation, use, and maintenance of applications in a distributed heterogeneous computing environment. It is a layer between the operating system, the network, and a distributed application that allows client applications to access remote servers.
With local directories, the physical location of the target database is individually stored on each client workstation in the database directory and node directory. The database administrator can therefore spend a large amount of time updating and changing these directories. The DCE directory services provide a central directory alternative to the local directories. It allows information about a database or a database manager instance to be recorded once in a central location, and any changes or updates to be made at that one location.
DCE is not a prerequisite for running DB2, but if you are operating in a DCE environment, see Appendix G. "Using Distributed Computing Environment (DCE) Directory Services" for more information.
You create a nodegroup with the CREATE NODEGROUP statement. This statement specifies the set of nodes on which the table space containers and table data are to reside. This statement also:
Assume that you want to load some tables on a subset of the database partitions in your database. You would use the following command to create a nodegroup of two nodes (1 and 2) in a database consisting of at least 3 (0 to 2) nodes:
CREATE NODEGROUP mixng12 ON NODES (1,2)
For more information about creating nodegroups, see the SQL Reference manual.
The CREATE DATABASE command or sqlecrea() API also create the default system nodegroups, IBMDEFAULTGROUP, IBMCATGROUP, and IBMTEMPGROUP. (See "Designing and Choosing Table Spaces" for information.)
Creating a table space within a database assigns containers to the table space and records its definitions and attributes in the database system catalog. You can then create tables within this table space.
The syntax of the CREATE TABLESPACE statement is discussed in detail in the SQL Reference manual. For information on SMS and DMS table spaces, see "Designing and Choosing Table Spaces".
The following SQL statement creates an SMS table space on OS/2 or Windows NT using three directories on three separate drives:
CREATE TABLESPACE RESOURCE
MANAGED BY SYSTEM
USING ('d:\acc_tbsp', 'e:\acc_tbsp', 'f:\acc_tbsp')
The following SQL statement creates a DMS table space on OS/2 using two file containers each with 5,000 pages:
CREATE TABLESPACE RESOURCE
MANAGED BY DATABASE
USING (FILE'd:\db2data\acc_tbsp' 5000,
FILE'e:\db2data\acc_tbsp' 5000)
In the above two examples, explicit names have been provided for the containers. You may also specify relative container names, in which case, the container will be created in the subdirectory created for the database (see "Database Physical Directories").
In addition, if part of the path name specified does not exist, the database manager will create it. If a subdirectory is created by the database manager, it may also be deleted by the database manager when the table space is dropped.
The assumption in the above examples is that the table spaces are not associated with a specific nodegroup. The default nodegroup IBMDEFAULTGROUP is used when the following parameter is not specified in the statement:
IN nodegroup
The following SQL statement creates a DMS table space on a UNIX-based system using three logical volumes of 10 000 pages each, and specifies their I/O characteristics:
CREATE TABLESPACE RESOURCE
MANAGED BY DATABASE
USING (DEVICE '/dev/rdblv6' 10000,
DEVICE '/dev/rdblv7' 10000,
DEVICE '/dev/rdblv8' 10000)
OVERHEAD 24.1
TRANSFERRATE 0.9
The UNIX devices mentioned in this SQL statement must already exist and be able to be written to by the instance owner and the SYSADM group.
The following example creates a DMS table space on a nodegroup called ODDNODEGROUP in a UNIX partitioned database. ODDNODEGROUP must be previously created with a CREATE NODEGROUP statement. In this case, the ODDNODEGROUP nodegroup is assumed to be made up of database partitions numbered 1, 3, and 5. On all database partitions, use the device /dev/hdisk0 for 10 000 4K pages. In addition, declare a device for each database partition of 40 000 4K pages.
CREATE TABLESPACE PLANS
MANAGED BY DATABASE
USING (DEVICE '/dev/HDISK0' 10000, DEVICE '/dev/n1hd01' 40000) ON NODE 1
(DEVICE '/dev/HDISK0' 10000, DEVICE '/dev/n3hd03' 40000) ON NODE 3
(DEVICE '/dev/HDISK0' 10000, DEVICE '/dev/n5hd05' 40000) ON NODE 5
UNIX devices are classified into two categories: character serial devices and block-structured devices. For all file-system devices, it is normal to have a corresponding character serial device (or raw device) for each block device (or cooked device). The block-structured devices are typically designated by names similar to "hd0" or "fd0". The character serial devices are typically designated by names similar to "rhd0", "rfd0", or "rmt0". These character serial devices have faster access than block devices. The character serial device names should be used on the CREATE TABLESPACE command and not block device names.
The overhead and transfer rate help to determine the best access path to use when the SQL statement is compiled. For information on the OVERHEAD and TRANSFERRATE parameters, see Part 3. "Tuning Application Performance".
DB2 can greatly improve the performance of sequential I/O using the sequential prefetch facility, which uses parallel I/O. See "Understanding Sequential Prefetching" for details on this facility.
You also have the ability to create a table space that uses a page size larger than the default 4 KB size. The following SQL statement creates an SMS table space on a UNIX-based system with an 8 KB page size.
CREATE TABLESPACE SMS8K
PAGESIZE 8192
MANAGED BY SYSTEM
USING ('FSMS_8K_1')
BUFFERPOOL BUFFPOOL8K
Notice that the associated buffer pool must also have the same 8 KB page size.
The created table space cannot be used until the buffer pool it references is activated.
The ALTER TABLESPACE SQL statement can be used to add a container to a DMS table space and modify the PREFETCHSIZE, OVERHEAD, and TRANSFERRATE settings for a table space. The transaction issuing the table space statement should be committed as soon as possible, to prevent system catalog contention.
| Note: | The PREFETCHSIZE should be a multiple of the EXTENTSIZE. For example if the EXTENTSIZE is 10, the PREFETCHSIZE should be 20 or 30. For more information, see "Understanding Sequential Prefetching". |
By placing a table space in a multiple database partition nodegroup, all of the tables within the table space are divided or partitioned across each database partition in the nodegroup. The table space is created into a nodegroup. Once in a nodegroup, the table space must remain there; It cannot be changed to another nodegroup. The CREATE TABLESPACE statement is used to associate a table space with a nodegroup.
DB2 for Windows NT supports direct disk access (raw I/O). This allows you to attach a direct disk access (raw) device to a Windows NT system. The following list demonstrates the physical and logical methods for identifying this type of device:
\\.\PhysicalDriveN
where N represents one of the physical drives in the system. For example, N could be replaced by 0, 1, 2, or any other positive integer.
\\.\N:
where N: represents a logical drive letter in the system. For example, N: could be replaced by E: or any other drive letter on the system.
For example:
| Note: | You must have Windows NT Version 4.0 with Service Pack 3 installed to be able to write logs to a device. |
| Note: | You can only specify a device on AIX, Windows NT, and Solaris platforms. |
There are advantages and disadvantages when you use raw devices to decide I/O configuration:
DB2 for Windows NT uses raw devices to manage database storage. The following commands or SQL statements can be used to specify a raw device for the type of container being created:
The following is an example of the CREATE TABLESPACE statement:
db2 create tablespace PAYROLL managed by database using
(device '\\.\PhysicalDrive1' 100000 )
overhead 24.1 transferrate 0.9
This creates a table space with one container on the second physical device, and consumes the first 409 600 000 bytes of the device. Note that in a Windows 95 environment, table spaces cannot be composed of containers that are defined as raw devices.
You can also use this method in conjunction with "Change the Database Log Path (newlogpath)" to use raw devices to store log files. There are considerations when doing this, however:
If you use multiple disks, this will provide a larger device, and the striping that results can improve performance by faster I/O throughput.
Information about the size of the device is used to indicate the size of the device (in 4 KB pages) available to DB2 under the support of the operating system. The amount of disk space that DB2 can write to is referred to as the device-size-available.
The first 4 KB page of the device is not used by DB2 (this space is generally used by operating system for other purposes.) This means that the total space available to DB2 is device-size = device-size-available - 1.
Notes:
While organizing your data into tables, it may also be beneficial to group tables (and other related objects) together. This is done by defining a schema through the use of the CREATE SCHEMA statement. Information about the schema is kept in the system catalog tables of the database to which you are connected. As other objects are created, they can be placed within this schema.
The syntax of the CREATE SCHEMA statement is described in detail in the SQL Reference manual. The new schema name cannot already exist in the system catalogs and it cannot begin with "SYS".
If a user has SYSADM or DBADM authority, then the user can create a schema with any valid name. When a database is created, IMPLICIT_SCHEMA authority is granted to PUBLIC (that is, to all users).
The definer of any objects created as part of the CREATE SCHEMA statement is the schema owner. This owner can GRANT and REVOKE schema privileges to other users.
The following is an example of a CREATE SCHEMA statement that creates a schema for an individual user with the authorization ID "joe":
CREATE SCHEMA joeschma AUTHORIZATION joe
This statement must be issued by a user with DBADM authority.
Schemas may also be implicitly created when a user has IMPLICIT_SCHEMA authority. With this authority, users implicitly create a schema whenever they create an object with a schema name that does not already exist.
If users do not have IMPLICIT_SCHEMA authority, the only schema they can create is one that has the same name as their own authorization ID.
You may wish to establish a default schema for use by unqualified object references in dynamic SQL statements issued from within a specific DB2 connection. This is done by setting the special register CURRENT SCHEMA to the schema you wish to use as the default. Any user can set this special register: No authorization is required.
The syntax of the SET SCHEMA statement is described in detail in the SQL Reference manual.
The following is an example of how to set the CURRENT SCHEMA special register:
SET CURRENT SCHEMA = 'SCHEMA01'
This statement can be used from within an application program or issued interactively. Once set, the value of the CURRENT SCHEMA special register is used as the qualifier (schema) for unqualified object references in dynamic SQL statements, with the exception of the CREATE SCHEMA statement where an unqualified reference to a database object exists.
The initial value of the CURRENT SCHEMA special register is equal to the authorization ID of the current session user.
After you determine how to organize your data into tables, the next step is to create those tables, by using the CREATE TABLE statement. The table descriptions are stored in the system catalog of the database to which you are connected.
The syntax of the CREATE TABLE statement is described in detail in the SQL Reference. For information about naming tables, columns, and other database objects, see Appendix E. "Naming Rules".
The CREATE TABLE statement gives the table a name, which is a qualified or unqualified identifier, and a definition for each of its columns. You can store each table in a separate table space, so that a table space will contain only one table. If a table will be dropped and created often, it is more efficient to store it in a separate table space and then drop the table space instead of the table. You can also store many tables within a single table space. In a partitioned database environment, the table space chosen also defines the nodegroup and the database partitions on which table data is stored.
The table does not contain any data at first. To add rows of data to it, use one of the following:
It is possible to add data into the table without logging the change. This is done using the NOT LOGGED INITIALLY parameter on the CREATE TABLE statement. Any changes made to the table by an INSERT, DELETE, UPDATE, CREATE INDEX, DROP INDEX, or ALTER TABLE operation in the same unit of work in which the table is created are not logged. Logging begins in subsequent units of work.
A table consists of one or more column definitions. A maximum of 500 columns can be defined for a table. Columns represent the attributes of an entity. The values in any column are all the same type of information. See the SQL Reference for more information.
| Note: | The maximum of 500 columns is true when using a 4K page size. The maximum is 1012 columns when using an 8K page size. |
A column definition includes a column name, data type, and any necessary null attribute, or default value (optionally chosen by the user).
The column name describes the information contained in the column and should be something that will be easily recognizable. It must be unique within the table; however, the same name can be used in other tables. See "Object Names" for information about naming rules.
The data type of a column indicates the length of the values in it and the kind of data that is valid for it. The database manager uses character string, numeric, date, time and large object data types. Graphic string data types are only available for database environments using multi-byte character sets. In addition, columns can be defined with user-defined distinct types, which are discussed in "Creating a User-Defined Type (UDT)".
The default attribute specification indicates what value is to be used if no value is provided. The default value can be specified, or a system-defined default value used. Default values may be specified for columns with, and without, the null attribute specification.
The null attribute specification indicates whether or not a column can contain null values.
The following is an example of a CREATE TABLE statement that creates the EMPLOYEE table in the RESOURCE table space. This table is defined in the sample database:
CREATE TABLE EMPLOYEE
(EMPNO CHAR(6) NOT NULL PRIMARY KEY,
FIRSTNME VARCHAR(12) NOT NULL,
MIDINIT CHAR(1) NOT NULL WITH DEFAULT,
LASTNAME VARCHAR(15) NOT NULL,
WORKDEPT CHAR(3),
PHONENO CHAR(4),
PHOTO BLOB(10M) NOT NULL)
IN RESOURCE
When creating a table, you can choose to have the columns of the table based on the attributes of a structured type.
One of the options you may consider when creating a table concerns the creation of a subtable. A subtable is a typed table based on a structured type where attributes are inherited from other tables. The other tables can be either root tables or supertables. (A root table is a supertable.) This is discussed further in subsequent sections.
The following sections build on the previous example to cover other options you should consider:
You can also create a table that is defined based on the result of a query. This type of table is called a summary table. For more information, see "Creating a Summary Table".
Before creating a table that contains large object columns, you need to make the following decisions:
If you do not want to log these changes, you must turn logging off by specifying the NOT LOGGED clause when you create the table. For example:
CREATE TABLE EMPLOYEE
(EMPNO CHAR(6) NOT NULL PRIMARY KEY,
FIRSTNME VARCHAR(12) NOT NULL,
MIDINIT CHAR(1) NOT NULL WITH DEFAULT,
LASTNAME VARCHAR(15) NOT NULL,
WORKDEPT CHAR(3),
PHONENO CHAR(4),
PHOTO BLOB(10M) NOT NULL NOT LOGGED)
IN RESOURCE
If the LOB column is larger than 1 GB, logging must be turned off. (As a rule of thumb, you may not want to log LOB columns larger than 10 MB.) As with other options specified on a column definition, the only way to change the logging option is to re-create the table.
Even if you choose not to log changes, LOB columns are shadowed to allow changes to be rolled back, whether the roll back is the result of a system generated error, or an application request. Shadowing is a recovery technique where current storage page contents are never overwritten. That is, old, unmodified pages are kept as "shadow" copies. These copies are discarded when they are no longer needed to support a transaction rollback.
| Note: | When recovering a database using the RESTORE and ROLLFORWARD commands, LOB data that was "NOT LOGGED"and was written since the last backup will be replaced by binary zeros. |
You can make the LOB column as small as possible using the COMPACT clause on the CREATE TABLE statement. For example:
CREATE TABLE EMPLOYEE
(EMPNO CHAR(6) NOT NULL PRIMARY KEY,
FIRSTNME VARCHAR(12) NOT NULL,
MIDINIT CHAR(1) NOT NULL WITH DEFAULT,
LASTNAME VARCHAR(15) NOT NULL,
WORKDEPT CHAR(3),
PHONENO CHAR(4),
PHOTO BLOB(10M) NOT NULL NOT LOGGED COMPACT)
IN RESOURCE
There is a performance cost when appending to a table with a compact LOB column, particularly if the size of LOB values are increased (because of storage adjustments that must be made).
On platforms such as OS/2 where sparse file allocation is not supported and where LOBs are placed in SMS table spaces, consider using the COMPACT clause. Sparse file allocation has to do with how physical disk space is used by an operating system. An operating system that supports sparse file allocation does not use as much physical disk space to store LOBs as compared to an operating system not supporting sparse file allocation. The COMPACT option allows for even greater physical disk space "savings" regardless of the support of sparse file allocation. Because you can get some physical disk space savings when using COMPACT, you should consider using COMPACT if your operating system does not support sparse file allocation.
| Note: | DB2 system catalogs use LOB columns and may take up more space than in previous versions. |
There are large object (LOB) columns in the catalog tables. LOB data is not kept in the buffer pool with other data but is read from disk each time it is needed. Reading from disk slows down the performance of DB2 where the LOB columns of the catalogs are involved. Since a file system usually has its own place for storing (or caching) data, using a SMS table space, or a DMS table space built on file containers, make avoidance of I/O possible when the LOB has previously been referenced.
This section discusses how to define constraints:
For more information on constraints, see "Planning for Constraint Enforcement" and the SQL Reference.
Unique constraints ensure that every value in the specified key is unique. A table can have any number of unique constraints, with at most one unique constraint defined as a primary key.
You define a unique constraint with the UNIQUE clause in the CREATE TABLE or ALTER TABLE statements. The unique key can consist of more than one column. More than one unique constraint is allowed on a table.
Once established, the unique constraint is enforced automatically by the database manager when an INSERT or UPDATE statement modifies the data in the table. The unique constraint is enforced through a unique index.
When a unique constraint is defined in an ALTER TABLE statement and an index exists on the same set of columns of that unique key, that index becomes the unique index and is used by the constraint.
You can take any one unique constraint and use it as the primary key. The primary key can be used as the parent key in a referential constraint (along with other unique constraints). There can be only one primary key per table. You define a primary key with the PRIMARY KEY clause in the CREATE TABLE or ALTER TABLE statement. The primary key can consist of more than one column.
A primary index forces the value of the primary key to be unique. When a table is created with a primary key, the database manager creates a primary index on that key.
Some performance tips for indexes used as unique constraints include:
Referential integrity is imposed by adding referential constraints to table and column definitions. Referential constraints are established with the the "FOREIGN KEY Clause", and the "REFERENCES Clause" in the CREATE TABLE or ALTER TABLE statements.
The identification of foreign keys enforces constraints on the values within the rows of a table or between the rows of two tables. The database manager checks the constraints specified in a table definition and maintains the relationships accordingly. The goal is to maintain integrity whenever one database object references another.
For example, primary and foreign keys each have a department number column. For the EMPLOYEE table, the column name is WORKDEPT, and for the DEPARTMENT table, the name is DEPTNO. The relationship between these two tables is defined by the following constraints:
The SQL statement defining the parent table, DEPARTMENT, is:
CREATE TABLE DEPARTMENT
(DEPTNO CHAR(3) NOT NULL,
DEPTNAME VARCHAR(29) NOT NULL,
MGRNO CHAR(6),
ADMRDEPT CHAR(3) NOT NULL,
LOCATION CHAR(16),
PRIMARY KEY (DEPTNO))
IN RESOURCE
The SQL statement defining the dependent table, EMPLOYEE, is:
CREATE TABLE EMPLOYEE
(EMPNO CHAR(6) NOT NULL PRIMARY KEY,
FIRSTNME VARCHAR(12) NOT NULL,
LASTNAME VARCHAR(15) NOT NULL,
WORKDEPT CHAR(3),
PHONENO CHAR(4),
PHOTO BLOB(10m) NOT NULL,
FOREIGN KEY DEPT (WORKDEPT)
REFERENCES DEPARTMENT ON DELETE NO ACTION)
IN RESOURCE
By specifying the DEPTNO column as the primary key of the DEPARTMENT table and WORKDEPT as the foreign key of the EMPLOYEE table, you are defining a referential constraint on the WORKDEPT values. This constraint enforces referential integrity between the values of the two tables. In this case, any employees that are added to the EMPLOYEE table must have a department number that can be found in the DEPARTMENT table.
The delete rule for the referential constraint in the employee table is NO ACTION, which means that a department cannot be deleted from the DEPARTMENT table if there are any employees in that department.
Although the previous examples use the CREATE TABLE statement to add a referential constraint, the ALTER TABLE statement can also be used. See "Altering a Table".
Another example: The same table definitions are used as those in the previous example. Also, the DEPARTMENT table is created before the EMPLOYEE table. Each department has a manager, and that manager is listed in the EMPLOYEE table. MGRNO of the DEPARTMENT table is actually a foreign key of the EMPLOYEE table. Because of this referential cycle, this constraint poses a slight problem. You could add a foreign key later (see "Adding Primary and Foreign Keys"). You could also use the CREATE SCHEMA statement to create both the EMPLOYEE and DEPARTMENT tables at the same time (see the example in the SQL Reference).
A foreign key references a primary key or a unique key in the same or another table. A foreign key assignment indicates that referential integrity is to be maintained according to the specified referential constraints. You define a foreign key with the FOREIGN KEY clause in the CREATE TABLE or ALTER TABLE statement.
The number of columns in the foreign key must be equal to the number of columns in the corresponding primary or unique constraint (called a parent key) of the parent table. In addition, corresponding parts of the key column definitions must have the same data types and lengths. The foreign key can be assigned a constraint name. If you do not assign a name, one is automatically assigned. For ease of use, it is recommended that you assign a constraint name and do not use the system-generated name.
The value of a composite foreign key matches the value of a parent key if the value of each column of the foreign key is equal to the value of the corresponding column of the parent key. A foreign key containing null values cannot match the values of a parent key, since a parent key by definition can have no null values. However, a null foreign key value is always valid, regardless of the value of any of its non-null parts.
The following rules apply to foreign key definitions:
The REFERENCES clause identifies the parent table in a relationship, and defines the necessary constraints. You can include it in a column definition or as a separate clause accompanying the FOREIGN KEY clause, in either the CREATE TABLE or ALTER TABLE statements.
If you specify the REFERENCES clause as a column constraint, an implicit column list is composed of the column name or names that are listed. Remember that multiple columns can have separate REFERENCES clauses, and that a single column can have more than one.
Included in the REFERENCES clause is the delete rule. In our example, the ON DELETE NO ACTION rule is used, which states that no department can be deleted if there are employees assigned to it. Other delete rules include ON DELETE CASCADE, ON DELETE SET NULL, and ON DELETE RESTRICT. See "DELETE Rules".
The LOAD utility will turn off constraint checking for self-referencing and dependent tables, placing these tables into check pending state. After the LOAD utility has completed, you will need to turn on the constraint checking for all tables for which it was turned off. For example, if the DEPARTMENT and EMPLOYEE tables are the only tables that have been placed in check pending state, you can execute the following command:
SET CONSTRAINTS FOR DEPARTMENT, EMPLOYEE IMMEDIATE CHECKED
The IMPORT utility is affected by referential constraints in the following ways:
To use these functions, first drop all foreign keys in which the table is a parent. When the import is complete, re-create the foreign keys with the ALTER TABLE statement.
A table check constraint specifies a search condition that is enforced for each row of the table on which the table check constraint is defined. You create a table check constraint on a table by associating a check-constraint definition with the table when the table is created or altered. This constraint is automatically activated when an INSERT or UPDATE statement modifies the data in the table. A table check constraint has no effect on a DELETE or SELECT statement.
A constraint name cannot be the same as any other constraint specified within the same CREATE TABLE statement. If you do not specify a constraint name, the system generates an 18-character unique identifier for the constraint.
A table check constraint is used to enforce data integrity rules not covered by key uniqueness or a referential integrity constraint. In some cases, a table check constraint can be used to implement domain checking. The following constraint issued on the CREATE TABLE statement ensures that the start date for every activity is not after the end date for the same activity:
CREATE TABLE EMP_ACT
(EMPNO CHAR(6) NOT NULL,
PROJNO CHAR(6) NOT NULL,
ACTNO SMALLINT NOT NULL,
EMPTIME DECIMAL(5,2),
EMSTDATE DATE,
EMENDATE DATE,
CONSTRAINT ACTDATES CHECK(EMSTDATE <= EMENDATE) )
IN RESOURCE
Although the previous example uses the CREATE TABLE statement to add a table check constraint, the ALTER TABLE statement can also be used. See "Altering a Table".
You can create a typed table using a variant of the CREATE TABLE statement. After defining hierarchies of user-defined structured types as described in "Creating a User-Defined Structured Type", you should consider the creation of typed tables. For example:
CREATE TABLE Department OF Department_t
(REF IS Oid USER GENERATED);
CREATE TABLE Person OF Person_t
(REF IS Oid USER GENERATED);
CREATE TABLE Employee OF Employee_t UNDER Person
INHERIT SELECT PRIVILEGES
(Dept WITH OPTIONS SCOPE Department);
CREATE TABLE Student OF Student_t UNDER Person
INHERIT SELECT PRIVILEGES;
CREATE TABLE Manager OF Manager_t UNDER Employee
INHERIT SELECT PRIVILEGES;
CREATE TABLE Architect OF Architect_t UNDER Employee
INHERIT SELECT PRIVILEGES;
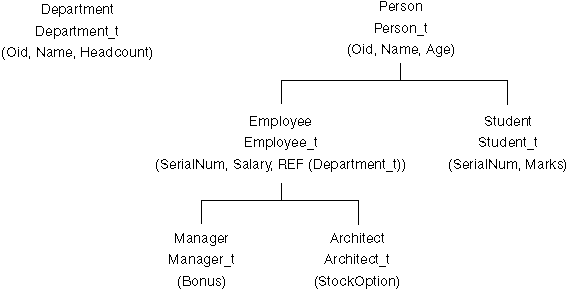
The first typed table created above is Department. This table is defined to be OF type Department_t, so it will hold instances of that type. This means that it will have a column corresponding to each attribute of the structured type Department_t. Because typed tables contain objects that can be referenced by other objects, every typed table must have an "object identifier" (OID) column as its first column. In this example, the type of the OID column will be REF(Department_t), and its column name (Oid) is given in the REF IS...USER GENERATED clause. The USER GENERATED part of this clause indicates that the initial value for the OID column of each newly inserted row will be provided by the user when inserting a row; once inserted, the OID column cannot be updated.
The next typed table above, Person, is of type Person_t. The type Person_t is the root of a type hierarchy, so we need to create a corresponding "table hierarchy" if we want to store instances of type Person_t and its subtypes. Thus, after creating the table Person, we create two "subtables" of the Person table, Employee and Student, and also two subtables of the Employee table, Manager and Architect. Just as a subtype inherits the attributes of its supertype, a subtable inherits the columns of its supertable -- including the OID column. (Note: A subtable must reside in the same schema as its supertable.) Rows in the Employee subtable, for example, will therefore have a total of six columns: Oid, Name, Age, SerialNum, Salary, and Dept.
The INHERIT SELECT PRIVILEGES clause specifies that the subtable being defined, such as, Employee, should (at least initially) be readable by the same users and groups as the "supertable", such as, Person, UNDER which it is created. Any user or group holding a SELECT privilege on the supertable will be granted SELECT privilege on the newly created subtable, with the subtable definer being the grantor of this privilege.
| Note: | Privileges may be granted and revoked independently at every level of a table hierarchy. Thus, the inherited SELECT privileges on a subtable may be revoked after the subtable has been created if the definer of the subtable does not wish for them to remain granted. While doing so does not prevent a user with SELECT privilege on the supertable from seeing those columns of the subtable's rows, it does prevent them from seeing the additional columns that appear only at the level of the subtable because a user can only operate directly on a subtable if they hold the necessary privilege on that subtable. |
The WITH OPTIONS SCOPE clause in the CREATE statement for the Employee table declares that the Dept column of this table has a "scope" of Department. This means that the reference values in this column of the Employee table are intended to refer to objects in the Department table. The scope information is needed if the user wants to be able to dereference these references in SQL statements using the new SQL dereference operator (->).
This example has shown how a table hierarchy can be defined, based on a corresponding hierarchy of structured types, in order to create a database in which objects of particular types and subtypes can be stored and managed. Every table hierarchy has a "root table", which has an OID column plus a column for each attribute of its declared type. In addition, it can have a number of "subtables", each of which is created UNDER the root table or some other appropriate "supertable" within the table hierarchy. This example has also shown how scopes are specified for reference attributes.
See SQL Reference for more information on the CREATE TABLE statement (or the CREATE VIEW statement) and how to establish subtype/supertype relationships between typed tables. (For an introduction to CREATE VIEW you could see "Creating a Typed View".)
After creating the structured types and then creating the corresponding tables and subtables, you will have a database like the following:
Once the hierarchy is established, you will need to populate the tables with data. This may be done as shown in the following example:
INSERT INTO Department (Oid, Name, Headcount)
VALUES(Department_t('1'), 'Toy', 15);
INSERT INTO Department (Oid, Name, Headcount)
VALUES(Department_t('2'), 'Shoe', 10);
INSERT INTO Person (Oid, Name, Age)
VALUES(Person_t('a'), 'Andrew', 20);
INSERT INTO Person (Oid, Name, Age)
VALUES(Person_t('b'), 'Bob', 30);
INSERT INTO Person (Oid, Name, Age)
VALUES(Person_t('c'), 'Cathy', 25);
INSERT INTO Employee (Oid, Name, Age, SerialNum, Salary, Dept)
VALUES(Employee_t('d'), 'Dennis', 26, 105, 30000, Department_t('1'));
INSERT INTO Employee (Oid, Name, Age, SerialNum, Salary, Dept)
VALUES(Employee_t('e'), 'Eva', 31, 83, 45000, Department_t('2'));
INSERT INTO Employee (Oid, Name, Age, SerialNum, Salary, Dept)
VALUES(Employee_t('f'), 'Franky', 28, 214, 39000, Department_t('2'));
INSERT INTO Student (Oid, Name, Age, SerialNum, Marks)
VALUES(Student_t('g'), 'Gordon', 19, 10245, 90);
INSERT INTO Student (Oid, Name, Age, SerialNum, Marks)
VALUES(Student_t('h'), 'Helen', 20, 10357, 70);
INSERT INTO Manager (Oid, Name, Age, SerialNum, Salary, Dept, Bonus)
VALUES(Manager_t('i'), 'Iris', 35, 251, 55000, Department_t('1'), 12000);
INSERT INTO Manager (Oid, Name, Age, SerialNum, Salary, Dept, Bonus)
VALUES(Manager_t('j'), 'Christina', 10, 317, 85000, Department_t('1'), 25000);
INSERT INTO Manager (Oid, Name, Age, SerialNum, Salary, Dept, Bonus)
VALUES(Manager_t('k'), 'Ken', 55, 482, 105000, Department_t('2'), 48000);
INSERT INTO Architect (Oid, Name, Age, SerialNum, Salary, Dept, StockOption)
VALUES(Architect_t('l'), 'Leo', 35, 661, 92000, Department_t('2'), 20000);
INSERT INTO Architect (Oid, Name, Age, SerialNum, Salary, Dept, StockOption)
VALUES(Architect_t('m'), 'Brian', 7, 882, 112000,
(SELECT Oid FROM Department WHERE name = 'Toy'), 30000);
Notice from the example that first value in each inserted row is the OID for the data being inserted into the tables. Also, when inserting data into a subtable, note that data must be provided for its inherited columns. Finally, notice that any reference-valued expression of the appropriate type can be used to initialize a reference attribute. In most cases above, the Dept reference of the employees is input as an appropriately type-casted constant; however, in the case of Brian, the reference is obtained using a subquery.
Following the above INSERT statements, we can now query the typed tables using their associated SQL extensions. For example, here is the result we would obtain if we now ask DB2 to "SELECT Name, Age FROM Person", which prints the names and ages of all persons (in Person or its subtables) in our database:
NAME AGE -------------------- ----------- Andrew 20 Bob 30 Dennis 26 Eva 31 Franky 28 Gordon 19 Helen 20 Iris 35 Christina 10 Ken 55 Leo 35 Brian 7 12 record(s) selected.
Similarly, here is the result that obtained if we ask DB2 to "SELECT Name, Salary, Dept->Name FROM Employee", which prints the names, salaries, and department names of all the employees in the database:
NAME SALARY NAME -------------------- ----------- -------------------- Dennis 30000 Toy Eva 45000 Shoe Franky 39000 Shoe Iris 55000 Toy Christina 85000 Toy Ken 105000 Shoe Leo 92000 Shoe Brian 112000 Toy 8 record(s) selected.
| Note: | In the second SELECT statement above, the dereference operator (->) is used. The dereference operator returns the named column value from the target table or subtable, or the target view or subview, of the scoped reference expression from the row with the matching OID column. Dept is the "scoped reference expression" (that is, a reference type that has a scope). Name is the name of an attribute of the target type of the scoped reference expression. |
Data, index, and long column data can be stored in the same table space as the table or in a different table space only for DMS. The following example shows how the EMP_PHOTO table could be created to store the different parts of the table in different table spaces:
CREATE TABLE EMP_PHOTO
(EMPNO CHAR(6) NOT NULL,
PHOTO_FORMAT VARCHAR(10) NOT NULL,
PICTURE BLOB(100K) )
IN RESOURCE
INDEX IN RESOURCE_INDEXES
LONG IN RESOURCE_PHOTO
This example will cause the EMP_PHOTO data to be stored as follows:
See "Table Space Design Considerations" for additional considerations on the use of multiple DMS table spaces for a single table.
See the SQL Reference for more information.
Before creating a table that will be physically divided or partitioned, you need to consider the following:
One additional option exists when creating a table in a partitioned database environment: the partitioning key. A partitioning key is a key that is part of the definition of a table. It determines the partition on which each row of data is stored.
It is important to select an appropriate partitioning key because it cannot be changed later. Furthermore, any unique indexes (and therefore unique or primary keys) must be defined as a superset of the partitioning key. That is, if a partitioning key is defined, unique keys and primary keys must include all of the same columns as the partitioning key (they may have more columns).
If you do not specify the partitioning key explicitly, the following defaults are used. Ensure that the default partitioning key is appropriate.
Following is an example:
CREATE TABLE MIXREC (MIX_CNTL INTEGER NOT NULL,
MIX_DESC CHAR(20) NOT NULL,
MIX_CHR CHAR(9) NOT NULL,
MIX_INT INTEGER NOT NULL,
MIX_INTS SMALLINT NOT NULL,
MIX_DEC DECIMAL NOT NULL,
MIX_FLT FLOAT NOT NULL,
MIX_DATE DATE NOT NULL,
MIX_TIME TIME NOT NULL,
MIX_TMSTMP TIMESTAMP NOT NULL)
IN MIXTS12
PARTITIONING KEY (MIX_INT) USING HASHING
In the preceding example, the table space is MIXTS12 and the partitioning key is MIX_INT. If the partitioning key is not specified explicitly, it is MIX_CNTL. (If no primary key is specified and no partitioning key is defined, the partitioning key is the first non-long column in the list.)
A row of a table, and all information about that row, always resides on the same database partition.
The size limit for one partition of a table is 64 GB, or the available disk space, whichever is smaller. (This assumes a 4 KB page size for the table space.) The size of the table can be as large as 64 GB (or the available disk space) times the number of database partitions. If the page size for the table space was 8 KB, the size of the table can be as large as 128 GB (or the available disk space) times the number of database partitions.
A trigger defines a set of actions that are executed in conjunction with, or triggered by, an INSERT, UPDATE, or DELETE clause on a specified base table. Some uses of triggers are to:
You can use triggers to support general forms of integrity or business rules. For example, a trigger can check a customer's credit limit before an order is accepted or update a summary data table.
The benefits of using a trigger are:
The following SQL statement creates a trigger that increases the number of employees each time a new person is hired, by adding 1 to the number of employees (NBEMP) column in the COMPANY_STATS table each time a row is added to the EMPLOYEE table.
CREATE TRIGGER NEW_HIRED
AFTER INSERT ON EMPLOYEE
FOR EACH ROW MODE DB2SQL
UPDATE COMPANY_STATS SET NBEMP = NBEMP+1;
A trigger body can include one or more of the following SQL statements: INSERT, searched UPDATE, searched DELETE, full-selects, SET transition-variable, and SIGNAL SQLSTATE. The trigger can be activated before or after the INSERT, UPDATE, or DELETE statement to which it refers. See the SQL Reference for complete syntax information on the CREATE TRIGGER statement. See the Embedded SQL Programming Guide for information about creating and using triggers.
All dependencies of a trigger on some other object are recorded in the SYSCAT.TRIGDEP catalog. A trigger can depend on many objects. These objects and the dependent trigger are presented in detail in the SQL Reference discussion on the DROP statement.
If one of these objects is dropped, the trigger becomes inoperative but its definition is retained in the catalog. To revalidate this trigger, you must retrieve its definition from the catalog and submit a new CREATE TRIGGER statement.
If a trigger is dropped, its description is deleted from the SYSCAT.TRIGGERS catalog view and all of its dependencies are deleted from the SYSCAT.TRIGDEP catalog view. All packages having UPDATE, INSERT, or DELETE dependencies on the trigger are invalidated.
If the dependent object is a view and it is made inoperative, the trigger is also marked inoperative. Any packages dependent on triggers that have been marked inoperative are invalidated. (For more information, see "Statement Dependencies When Changing Objects".)
User-defined functions (UDFs) extend and add to the support provided by built-in functions of SQL, and can be used wherever a built-in function can be used. You can create UDFs as either:
There are three types of UDFs:
For example, if there is a distinct type SHOESIZE defined with base type INTEGER, a UDF AVG(SHOESIZE) which is sourced on the built-in function AVG(INTEGER) could be defined, and it would be a column function.
For example, table functions can take a file and convert it to a table, tabularize sample data from the World Wide Web, or access a Lotus Notes database and return information such as the date, sender, and text of mail messages. This information can be joined with other tables in the database.
A table function can only be an external function. It cannot be a sourced function.
Information about existing UDFs is recorded in the SYSCAT.FUNCTIONS and SYSCAT.FUNCPARMS catalog views. The system catalog does not contain the executable code for the UDF. (Therefore, when creating your backup and recovery plans you should consider how you will manage your UDF executables.)
Statistics about the performance of UDFs are important when compiling SQL statements. For information about how to update UDF statistics in the system catalog, see "Updating Statistics for User-Defined Functions".
A UDF cannot be dropped if a view, trigger, table check constraint, or another UDF is dependent on it. If a UDF is dropped, packages that are dependent on it are marked inoperative. (For more information, see "Statement Dependencies When Changing Objects".)
For details on using the CREATE FUNCTION statement to write a UDF to suit your specific application, see the Embedded SQL Programming Guide. See the SQL Reference for details on UDF syntax.
A user-defined type (UDT) is a named data type that is created in the database by the user. A UDT can be a distinct type which shares a common respresentation with a built-in data type or a structured type which has a sequence of named attributes that each have a type. A structured type can be a subtype of another structured type (called a supertype), defining a type hierarchy.
UDTs support strong typing, which means that even though they share the same representation as other types, values of a given UDT are considered to be compatible only with values of the same UDT or UDTs in the same type hierarchy.
The SYSCAT.DATATYPES catalog view allows you to see the UDTs that have been defined for your database. This catalog view also shows you the data types defined by the database manager when the database was created. For a complete list of all data types, see the SQL Reference.
A UDT cannot be used as an argument for most of the system-provided, or built-in, functions. User-defined functions must be provided to enable these and other operations.
You can drop a UDT only if:
When a UDT is dropped, any functions that are dependent on it are also dropped.
A user-defined distinct type is a data type derived from an existing type, such as an integer, decimal, or character type. You can create a distinct type using the CREATE DISTINCT TYPE statement.
The following SQL statement creates the distinct type t_educ as a smallint:
CREATE DISTINCT TYPE T_EDUC AS SMALLINT WITH COMPARISONS
Instances of the same distinct type can be compared to each other, if the WITH COMPARISONS clause is specified on the CREATE DISTINCT TYPE statement (as in the example). The WITH COMPARISONS clause cannot be specified if the source data type is a large object, a DATALINK, LONG VARCHAR, or LONG VARGRAPHIC type.
Instances of distinct types cannot be used as arguments of functions or operands of operations that were defined on the source type. Similarly, the source type cannot be used in arguments or operands that were defined to use a distinct type.
Once you have created a distinct type, you can use it to define columns in a CREATE TABLE statement:
CREATE TABLE EMPLOYEE
(EMPNO CHAR(6) NOT NULL,
FIRSTNME VARCHAR(12) NOT NULL,
LASTNAME VARCHAR(15) NOT NULL,
WORKDEPT CHAR(3),
PHONENO CHAR(4),
PHOTO BLOB(10M) NOT NULL,
EDLEVEL T_EDUC)
IN RESOURCE
Creating the distinct also generates support to cast between the distinct type and the source type. Hence, a value of type T_EDUC can be cast to a SMALLINT value and SMALLINT value can be cast to a T_EDUC value.
See the SQL Reference for complete syntax information on the CREATE DISTINCT TYPE statement. See the Embedded SQL Programming Guide for information about creating and using a distinct type.
You can create a structured type using the CREATE TYPE statement. Subtyping is supported for structured types, and is expressed by using the CREATE TYPE...UNDER variant of the CREATE TYPE statement.
For example, consider the following user-defined structured types:
CREATE TYPE Department_t AS (Name VARCHAR(20), Headcount INT)
WITHOUT COMPARISONS NOT FINAL MODE DB2SQL;
CREATE TYPE Person_t AS (Name VARCHAR(20), Age INT)
WITHOUT COMPARISONS NOT FINAL MODE DB2SQL;
CREATE TYPE Employee_t UNDER Person_t
AS (SerialNum INT, Salary INT, Dept REF(Department_t))
WITHOUT COMPARISONS NOT FINAL MODE DB2SQL;
CREATE TYPE Student_t UNDER Person_t AS (SerialNum INT, Marks INT)
WITHOUT COMPARISONS NOT FINAL MODE DB2SQL;
CREATE TYPE Manager_t UNDER Employee_t AS (Bonus INT)
WITHOUT COMPARISONS NOT FINAL MODE DB2SQL;
CREATE TYPE Architect_t UNDER Employee_t AS (StockOption INT)
WITHOUT COMPARISONS NOT FINAL MODE DB2SQL;
The AS clause provides the attribute definitions associated with the type.
The WITHOUT COMPARISONS clause indicates that comparison functions are not supported for instances of the structured type.
The NOT FINAL clause indicates that the structured type may be used as a supertype.
The MODE DB2SQL clause is used to specify the mode of the type. DB2SQL is the only value for mode currently supported.
The UNDER clause specifies that the structured type is being defined as a subtype of the specified supertype.
The first structured type above (Department_t) is a type with two attributes: Name and Headcount. The second structured type (Person_t) is another type with two attributes: Name and Age. The type Person_t has two subtypes, Employee_t and Student_t, that each inherit the attributes of Person_t but have several additional attributes that are specific to their particular types. Note that the Dept attribute of Employee_t is a reference, of type REF(Department_t), that can refer to an object of type Department_t. Finally, Manager_t and Architect_t are both subtypes of Employee_t; they inherit all the attributes of Employee_t and extend them further as appropriate for their types. Thus, an instance of type Manager_t will have a total of six attributes: Name, Age, SerialNum, Salary, Dept, and Bonus.
This example showing user-defined structured types contains definitions for two "type hierarchies". One is the Department_t type hierarchy, which consists only of the type Department_t (and therefore isn't much of a hierarchy). The other is the Person_t type hierarchy, which consists of the type Person_t, two subtypes of Person_t, namely Employee_t and Student_t, and two subtypes of Employee_t, namely Manager_t and Architect_t. The Department_t type and Person_t type are "root types" since they are not subtypes of any other type (that is, neither one has an UNDER clause in its type definition). The Employee_t type is a "subtype" of Person_t, or respectively Person_t is a "supertype" of Employee_t, since the structured type Employee_t is created UNDER the type Person_t and inherits its attributes.
See SQL Reference for more information on the CREATE TYPE (Structured) statement.
Views are derived from one or more base tables or views, and can be used interchangeably with base tables when retrieving data. When changes are made to the data shown in a view, the data is changed in the table itself.
A view can be created to limit access to sensitive data, while allowing more general access to other data. For example, the EMPLOYEE table may have salary information in it, which should not be made available to everyone. The employee's phone number, however, should be generally accessible. In this case, a view could be created from the LASTNAME and PHONENO columns only. Access to the view could be granted to PUBLIC, while access to the entire EMPLOYEE table could be restricted to those who have the authorization to see salary information. For information about read-only views, see the SQL Reference manual.
With a view, you can make a subset of table data available to an application program and validate data that is to be inserted or updated. A view can have column names that are different from the names of corresponding columns in the original tables.
The use of views provides flexibility in the way your programs and end-user queries can look at the table data.
The following SQL statement creates a view on the EMPLOYEE table that lists all employees in Department A00 with their employee and telephone numbers:
CREATE VIEW EMP_VIEW (DA00NAME, DA00NUM, PHONENO)
AS SELECT LASTNAME, EMPNO, PHONENO FROM EMPLOYEE
WHERE WORKDEPT = 'A00'
WITH CHECK OPTION
The first line of this statement names the view and defines its columns. The name EMP_VIEW must be unique within its schema in SYSCAT.TABLES. The view name appears as a table name although it contains no data. The view will have three columns called DA00NAME, DA00NUM, and PHONENO, which correspond to the columns LASTNAME, EMPNO, and PHONENO from the EMPLOYEE table. The column names listed apply one-to-one to the select list of the SELECT statement. If column names are not specified, the view uses the same names as the columns of the result table of the SELECT statement.
The second line is a SELECT statement that describes which values are to be selected from the database. It may include the clauses ALL, DISTINCT, FROM, WHERE, GROUP BY, and HAVING. The name or names of the data objects from which to select columns for the view must follow the FROM clause.
The WITH CHECK OPTION clause indicates that any updated or inserted row to the view must be checked against the view definition, and rejected if it does not conform. This enhances data integrity but requires additional processing. If this clause is omitted, inserts and updates are not checked against the view definition.
The following SQL statement creates the same view on the EMPLOYEE table using the SELECT AS clause:
CREATE VIEW EMP_VIEW
SELECT LASTNAME AS DA00NAME,
EMPNO AS DA00NUM,
PHONENO
FROM EMPLOYEE
WHERE WORKDEPT = 'A00'
WITH CHECK OPTION
You can create a view that uses a UDF in its definition. However, to update this view so that it contains the latest functions, you must drop it and then re-create it. If a view is dependent on a UDF, that function cannot be dropped.
The following SQL statement creates a view with a function in its definition:
CREATE VIEW EMPLOYEE_PENSION (NAME, PENSION)
AS SELECT NAME, PENSION(HIREDATE,BIRTHDATE,SALARY,BONUS)
FROM EMPLOYEE
The UDF function PENSION calculates the current pension an employee is eligible to receive, based on a formula involving their HIREDATE, BIRTHDATE, SALARY, and BONUS.
In addition to using views as described above, a view can also be used to:
An alternative to creating a view is to use a nested or common table expression to reduce catalog lookup and improve performance. See the SQL Reference for more information about common table expressions.
You can create a typed view using the CREATE VIEW statement. For example, to create a view of the typed Department table that we created earlier, we can define a structured type that has the desired attributes and then create a typed view using that type:
CREATE TYPE VDepartment_t AS (Name VARCHAR(20))
WITHOUT COMPARISONS NOT FINAL MODE DB2SQL;
CREATE VIEW VDepartment OF VDepartment_t MODE DB2SQL
(REF IS VOid USER GENERATED)
AS SELECT VDepartment_t(Varchar(Oid)), Name FROM Department;
The OF clause in the CREATE VIEW statement tells the system that the columns of the view are to be based on the attributes of the indicated structured type (in this case VDepartment_t).
The MODE DB2SQL clause specifies the mode of the typed view. This is the only valid mode currently supported.
The REF IS... clause is identical to that of the typed CREATE TABLE statement. It provides a name for the view's OID column (VOid in this case), which is the first column of the view. Typed views, like typed tables, require an OID column to be specified (in the case of a root view) or inherited (in the case of a subview, as will be shown shortly).
The USER GENERATED clause specifies that the initial value for the OID column must be provided by the user when inserting a row. Once inserted, the OID column cannot be updated.
To illustrate the creation of a typed view hierarchy, the following example defines a view hierarchy that omits some sensitive data and eliminates some type distinctions from the Person table hierarchy created earlier under "Creating a Typed Table":
CREATE TYPE VPerson_t AS (Name VARCHAR(20))
WITHOUT COMPARISONS NOT FINAL MODE DB2SQL;
CREATE TYPE VEmployee_t UNDER VPerson_t
AS (Salary INT, Dept REF(VDepartment_t))
WITHOUT COMPARISONS NOT FINAL MODE DB2SQL;
CREATE VIEW VPerson OF VPerson_t MODE DB2SQL
(REF IS VOid USER GENERATED)
AS SELECT VPerson_t (Varchar(Oid)), Name FROM ONLY(Person);
CREATE VIEW VEmployee OF VEmployee_t MODE DB2SQL
UNDER VPerson INHERIT SELECT PRIVILEGES
(Dept WITH OPTIONS SCOPE VDepartment)
AS SELECT VEmployee_t(Varchar(Oid)), Name, Salary,
VDepartment_t(Varchar(Dept))
FROM Employee;
The two CREATE TYPE statements create the structured types that are needed to create the object view hierarchy for this example.
The first typed CREATE VIEW statement above creates the root view of the hierarchy, VPerson, and is very similar to the VDepartment view definition. The difference is the use of ONLY(Person) to ensure that only the rows in the Person table hierarchy that are in the Person table are included in the VPerson view. This ensures that the Oid values in VPerson are unique compared with the Oid values in VEmployee. The second CREATE VIEW statement creates a subview VEmployee of the view VPerson. As was the case for the UNDER clause in the CREATE TABLE...UNDER statement, the UNDER clause when creating a view establishes the superview/subview relationship. (Note: The subview must be created in the same schema as its superview.) As was the case for typed tables, columns are inherited by subviews. Rows in the VEmployee view will inherit the columns VOid and Name from VPerson and have the additional columns Salary and Dept associated with the type VEmployee_t.
The INHERIT SELECT PRIVILEGES clause has the same meaning here as in the typed CREATE TABLE statement.
Similarly, the WITH OPTIONS clause in a typed view definition plays the same role as it does in a typed table definition -- it allows column options such as SCOPE to be specified. As well, a new column option, READ ONLY (not used in our example), is provided for columns of typed views. This clause is used to force a superview column to be marked as read-only so that a later subview definition can legitimately specify an expression for the same column that is implicitly read-only.
If a view has a reference column (like VEmployee's Dept column), a scope must be associated with the column if it is to be useable in SQL dereference operations. If no scope is specified for the reference column of the view and the underlying table or view column was scoped, then the underlying column's scope is passed on to the view's reference column. It can be explicitly given a scope by using WITH OPTIONS, as in our example where the Dept column of the VEmployee view gets the VDepartment view as its scope. The column would remain unscoped if the underlying table or view column did not have a scope and none was explicitly assigned in the view definition (or later by using the ALTER VIEW statement).
There are several important rules associated with restrictions on the queries for typed views found in the SQL Reference that you should read carefully before attempting to create and use a typed view.
A summary table is a table whose definition is based on the result of a query. As such, the summary table typically contains pre-computed results based on the data existing in the table or tables that its definition is based on. If the SQL compiler determines that a dynamic query will run more efficiently against a summary table than the base table, the query executes against the summary table, and you obtain the result faster than you otherwise would.
The creation of a summary table with the replication option can be used to replicate tables across all nodes in a partitioned database environment. These are known as "replicated summary tables". See "Replicated Summary Tables" for more information.
| Note: | Summary tables are not used with static SQL. |
To create a summary table, you use the CREATE SUMMARY TABLE statement with the AS fullselect clause and the REFRESH DEFERRED option. REFRESH DEFERRED is the only option currently supported; the IMMEDIATE option is not. Summary tables specified with REFRESH DEFERRED will not reflect changes to the underlying base tables. You should use summary tables where this is not a requirement. For example, if you run DSS queries, you would use the summary table to contain legacy data.
A summary table defined with REFRESH DEFERRED may be used in place of a query when it:
The SQL special register CURRENT REFRESH AGE SQL is set to ANY or has a value of 99999999999999. The collection of nines is the maximum value allowed in this special register which is a timestamp duration value with a data type of DECIMAL(20,6).
| Note: | Summary tables are not used to optimize static SQL. |
You use the CURRENT REFRESH AGE special register to specify the amount of time that the summary table with deferred refresh can be used for a dynamic query before it must be refreshed. To set the value of the CURRENT REFRESH AGE special register, you can use the SET CURRENT REFRESH AGE statement. For more information about the CURRENT REFRESH AGE special register and the SET CURRENT REFRESH AGE statement, refer to the SQL Reference.
| Note: | Setting the CURRENT REFRESH AGE special register to a value other than zero should be done with caution. By allowing a summary table that may not represent the values of the underlying base table to be used to optimize the processing of the query, the result of the query may not accurately represent the data in the underlying table. This may be reasonable when you know the underlying data has not changed, or you are willing to accept the degree of error in the results based on your knowledge of the data. |
With activity affecting the source data, a summary table over time will no longer contain accurate data. You will need to use the REFRESH TABLE statement. Refer to the SQL Reference for more information.
If you want to create a new base table that is based on any valid fullselect, specify the DEFINITION ONLY keyword when you create the table. When the create table operation completes, the new table is not treated as a summary table, but rather as a base table. For example, you can create the exception tables used in LOAD and SET CONSTRAINTS as follows:
CREATE TABLE XT AS
(SELECT T.*, CURRENT TIMESTAMP AS TIMESTAMP,CLOB(",32K)
AS MSG FROM T) DEFINITION ONLY
Here are some of the key restrictions regarding summary tables:
Refer to the SQL Reference for a complete statement of summary table restrictions.
An alias is an indirect method of referencing a table or view, so that an SQL statement can be independent of the qualified name of that table or view. Only the alias definition must be changed if the table or view name changes. An alias can be created on another alias. An alias can be used in a view or trigger definition and in any SQL statement, except for table check-constraint definitions, in which an existing table or view name can be referenced.
The alias is replaced at statement compilation time by the table or view name. If the alias or alias chain cannot be resolved to a table or view name, an error results. For example, if WORKERS is an alias for EMPLOYEE, then at compilation time:
SELECT * FROM WORKERS
becomes in effect
SELECT * FROM EMPLOYEE
An alias name can be used wherever an existing table name can be used, and can refer to another alias if no circular or repetitive references are made along the chain of aliases.
The following SQL statement creates an alias WORKERS for the EMPLOYEE table:
CREATE ALIAS WORKERS FOR EMPLOYEE
The alias name cannot be the same as an existing table, view, or alias, and can only refer to a table within the same database. The name of a table or view used in a CREATE TABLE or CREATE VIEW statement cannot be the same as an alias name in the same schema.
You do not require special authority to create an alias, unless the alias is in a schema other than the one owned by your current authorization ID, in which case DBADM authority is required.
An alias can be defined for a table, view, or alias that does not exist at the time of definition. However, it must exist when an SQL statement containing the alias is compiled.
When an alias, or the object to which an alias refers, is dropped, all packages dependent on the alias are marked invalid and all views and triggers dependent on the alias are marked inoperative.
| Note: | DB2 for MVS/ESA employs two distinct concepts of aliases: ALIAS and SYNONYM. These two concepts differ from DB2 Universal Database as follows: |
An index is a list of the locations of rows, sorted by the contents of one or more specified columns. Indexes are typically used to speed up access to a table. However, they can also serve a logical data design purpose. For example, a unique index does not allow entry of duplicate values in the columns, thereby guaranteeing that no two rows of a table are the same. Indexes can also be created to specify ascending or descending order of the values in a column.
An index is defined by columns in the base table. It can be defined by the creator of a table, or by a user who knows that certain columns require direct access. Up to 16 columns can be specified for an index. A primary index key is automatically created on the primary key, unless a user-defined index already exists.
Any number of indexes can be defined on a particular base table and they can have a beneficial effect on the performance of queries. However, the more indexes there are, the more the database manager must modify during update, delete, and insert operations. Creating a large number of indexes for a table that receives many updates can slow down processing of requests. Therefore, use indexes only where a clear advantage for frequent access exists.
An index key is a column or collection of columns on which an index is defined, and determines the usefulness of an index. Although the order of the columns making up an index key does not make a difference to index key creation, it may make a difference to the optimizer when it is deciding whether or not to use an index.
If the table being indexed is empty, an index is still created, but no index entries are made until the table is loaded or rows are inserted. If the table is not empty, the database manager makes the index entries while processing the CREATE INDEX statement.
For a clustering index, new rows are inserted physically close to existing rows with similar key values. This yields a performance benefit during queries because it results in more a linear access pattern to data pages and more effective pre-fetching.
If you want a primary key index to be a clustering index, a primary key should not be specified at CREATE TABLE. Once a primary key is created, the associated index cannot be modified. Instead, perform a CREATE TABLE without a primary key clause. Then issue a CREATE INDEX statement, specifying clustering attributes. Finally, use the ALTER TABLE statement to add a primary key that corresponds to the index just created. This index will be used as the primary key index.
Generally, clustering is more effectively maintained if the clustering index is unique.
Column data which is not part of the unique index key but which is to be stored/maintained in the index is called an include column. Include columns can be specified for unique indexes only. When creating an index with include columns, only the unique key columns are sorted and considered for uniqueness. Use of include columns improves the performance of data retrieval when index access is involved.
Indexes for tables in a partitioned database are built using the same CREATE INDEX statement. They are partitioned based on the partitioning key of the table. An index on a table consists of the local indexes in that table on each node in the nodegroup. Note that unique indexes defined in a multiple partition environment must be a superset of the partitioning key.
Performance Tip: Create your indexes before using the LOAD utility if you are going to carry out the following series of tasks:
You should consider ordering the execution of tasks in the following way:
For more information on LOAD performance improvements, see "System Catalog Tables".
Indexes are maintained after they are created. Subsequently, when application programs use a key value to randomly access and process rows in a table, the index based on that key value can be used to access rows directly. This is important, because the physical storage of rows in a base table is not ordered. When a row is inserted, unless there is a clustering index defined, the row is placed in the most convenient storage location that can accommodate it. When searching for rows of a table that meet a particular selection condition and the table has no indexes, the entire table is scanned. An index optimizes data retrieval without performing a lengthy sequential search.
The data for your indexes can be stored in the same table space as your table data, or in a separate table space containing index data. The table space used to store the index data is determined when the table is created (see "Creating a Table in Multiple Table Spaces").
The following two sections "Using an Index" and "Using the CREATE INDEX Statement" provide more information on creating an index.
An index is never directly used by an application program. The decision on whether to use an index and which of the potentially available indexes to use is the responsibility of the optimizer.
The best index on a table is one that:
For a detailed discussion of how an index can be beneficial, see "Index Scan Concepts".
You can create an index that will allow duplicates (a non-unique index) to enable efficient retrieval by columns other than the primary key, and allow duplicate values to exist in the indexed column or columns.
The following SQL statement creates a non-unique index called LNAME from the LASTNAME column on the EMPLOYEE table, sorted in ascending order:
CREATE INDEX LNAME ON EMPLOYEE (LASTNAME ASC)
The following SQL statement creates a unique index on the phone number column:
CREATE UNIQUE INDEX PH ON EMPLOYEE (PHONENO DESC)
A unique index ensures that no duplicate values exist in the indexed column or columns. The constraint is enforced at the end of the SQL statement that updates rows or inserts new rows. This type of index cannot be created if the set of one or more columns already has duplicate values.
The keyword ASC puts the index entries in ascending order by column, while DESC puts them in descending order by column. The default is ascending order.
The following SQL statement creates a clustering index called INDEX1 on LASTNAME column of the EMPLOYEE table:
CREATE INDEX INDEX1 ON EMPLOYEE (LASTNAME) CLUSTER
To be effective, use clustering indexes with the PCTFREE parameter associated with the ALTER TABLE statement so that new data can be inserted on the correct pages which maintains the clustering order. Typically, the greater the INSERT activity on the table, the larger the PCTFREE value (on the table) that will be needed in order to maintain clustering. Since this index determines the order by which the data is laid out on physical pages, only one clustering index can be defined for any particular table.
If, on the other hand, the index key values of these new rows are, for example, always new high key values, then the clustering attribute of the table will try to place them at the end of the table. Having free space in other pages will do little to preserve clustering. In this case, placing the table in append mode may be a better choice than a clustering index and altering the table to have a large PCTFREE value. You can place the table in append mode by issuing: ALTER TABLE APPEND ON. See "Changing Table Attributes" for additional overview information on ALTER TABLE. Refer to the SQL Reference for additional detailed information on ALTER TABLE.
The above discussion also applies to new "overflow" rows that result from UPDATEs which increase the size of a row.
The PCTFREE clause of the CREATE INDEX statement specifies the percentage of each index page to leave as free space when the index is built. Leaving more free space on the index pages will result in fewer page splits. This will reduce the need to reorganize the table in order to regain sequential index pages which increases prefetching. And prefetching is one important component that may improve performance. Again, if there are always high key values, then you will want to consider lowering the value of the PCTFREE clause of the CREATE INDEX statement. In this way there will be limited wasted space reserved on each index page.
In multiple partition databases, unique indexes must be defined as supersets of the partitioning key.
If you have a replicated summary table, its base table (or tables) must have a unique index, and the index key columns must be used in the query that defines the replicated summary table. For more information, see "Replicated Summary Tables".
For intra-partition parallelism, index create performance is improved by using multiple processors for the scanning and sorting of data that is performed during index creation. The use of multiple processors is enabled by setting intra_parallel to YES(1) or ANY(-1). The number of processors used during index create is determined by the system and is not affected by the configuration parameters dft_degree or max_querydegree, by the application runtime degree, or by the SQL statement compilation degree. If the database configuration parameter index sort is NO, then index create will not use multiple processors.