2 0 2 5
Command R7B Arabic
Command R7B Arabic is a SOTA 7-billion parameter LLM for English and Arabic use cases, trained using a combination of standard SFT, offline preference optimization, and model merging. The model was specially trained to target Modern Standard Arabic language performance and native speaker preferences on enterprise use cases. Our report on this model was accepted to the AfricaNLP Workshop at ACL 2025.
2 0 2 4
AI Summit Seoul 2024 Talk - "From Proof-of-Concept to Production: Battle-Tested Insights from 100+ Enterprise GenAI Deployments"
I gave a talk along with the lead of my team at Cohere, Vivek Muppalla, at AI Summit Seoul 2024 in South Korea. We went over lessons we have learned within the Applied Machine Learning team in deploying LLMs for enterprise use cases. Topics included effectively using LLMs for RAG, customizing language models for specific use cases, and designing and running enterprise evaluations.
Quantifying Robustness in White-Box Instruction-Tuned Large Language Models (XCS224u project)
This was my final project for the course XCS224u (Natural Language Understanding) at the Stanford Center for Professional Development (SCPD). The goal was to determine if the vulnerability of a model to minor prompt variations could be quantified in its activations, in the vein of mechanistic interpretability. I examined two candidate techniques for quantifying robustness to prompt perturbation, testing them on on three 7-billion parameter models for two different perturbation schemes.
2 0 2 3
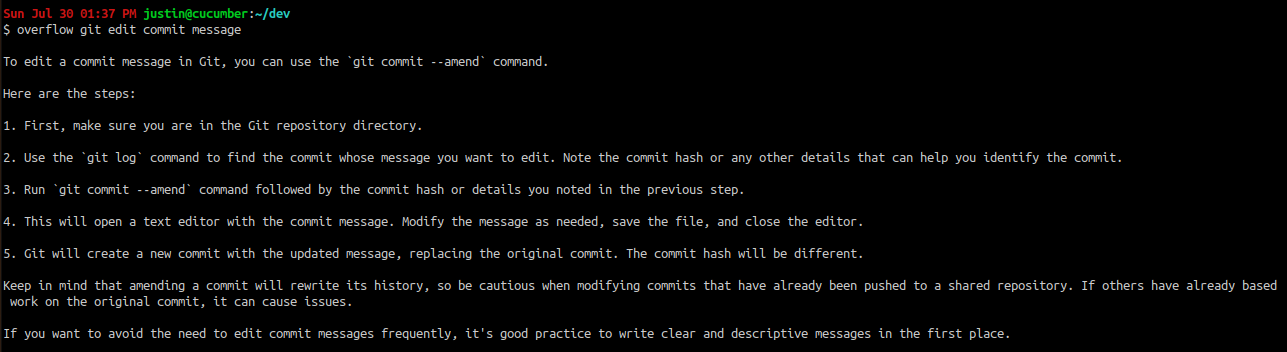
Overflow - Directly Querying OpenAI API from the CLI
A fun hack for replacing Stack Overflow in your coding workflow with GPT-3.5, all from the CLI:
2 0 2 2
My Experience Taking "XCS224n: NLP with Deep Learning"
This is a short post on my experience taking XCS224n, or "NLP with Deep Learning," this fall through the Stanford Center for Professional Development (SCPD). Prior to taking this course, I didn't find too much information about it online. Here, I will share what it covers, how it differs from the more well-known CS224n, and who I think the course would benefit.
2 0 2 1
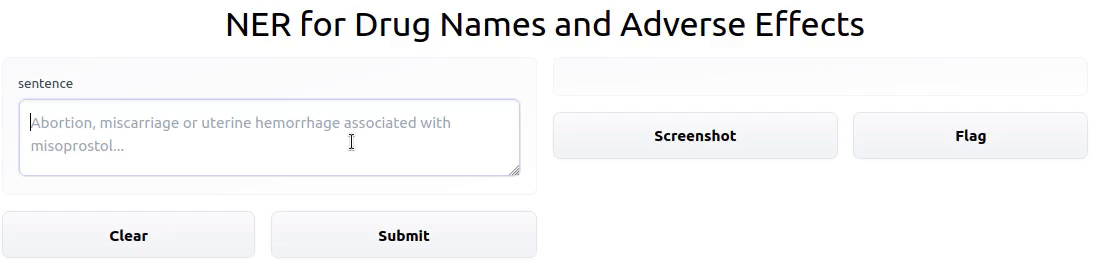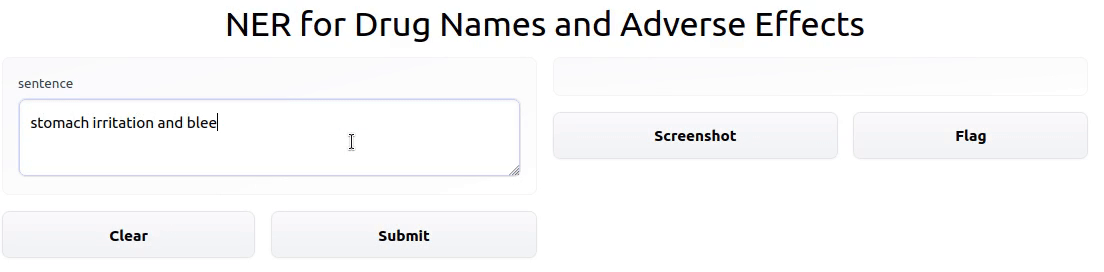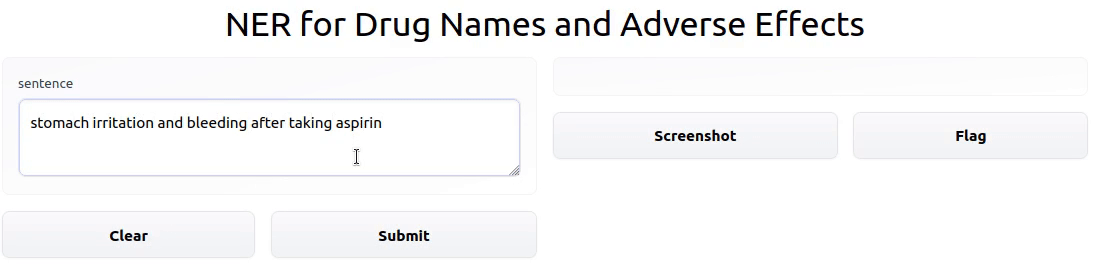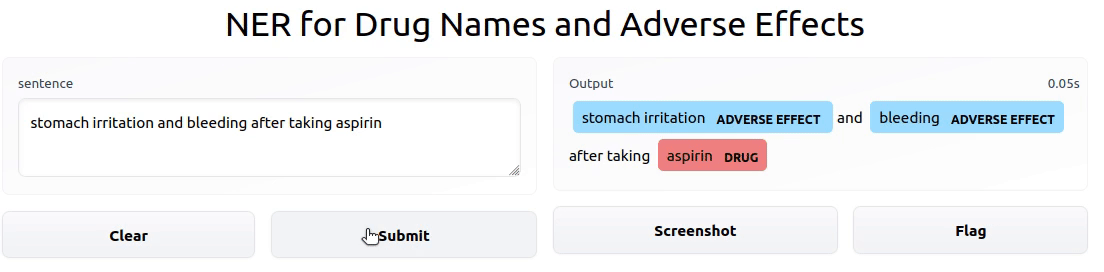
Fine-Tuning SciBERT to Recognize Drug Names and Adverse Effects
In this project, I trained a Transformer model to perform Named Entity Recognition on drug names and adverse drug effects.
During the Hugging Face Community Event from November 15-19, 2021, I modified theade_corpus_v2dataset to make it amenable to training a Named Entity Recognition model. I then fine-tuned SciBERT on the modified dataset. Finally, I deployed an interactive demo of the model to a Gradio app hosted by Hugging Face Spaces.
A notebook with code to process the dataset for the NER task and fine-tune the SciBERT model can be found here.
AWS Startups Blog Guest Post: Accelerating Drug Development with Amazon Comprehend
I wrote a post on the AWS Startups Blog about how we're using natural language processing to accelerate drug development efforts at Sumitovant Biopharma. We used open-source data to train a model using Amazon Comprehend to classify sentences from clinical trial publication abstracts. Then, we deployed the model and integrated it into an internal front-end application where users can search for publications on PubMed and see relevant details in their abstracts highlighted for quick evaluation.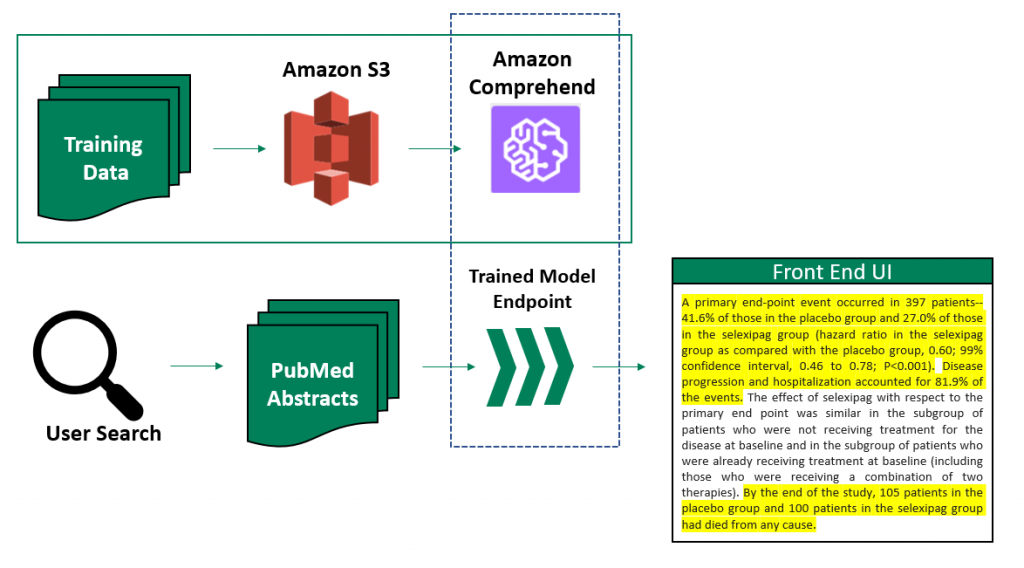
Transformers: a Primer
The purpose of this post is to break down the math behind the Transformer architecture, as well as share some helpful resources and gotcha's based on my experience in learning about this architecture. Starting with an exploration of sequence transduction literature leading up to the Transformer, I then walk through the foundational Attention is All You Need paper by Vaswani, et al. (2017). The post was written with the goal that someone with little to no prior experience with the Transformer architecture could come away with a mathematically intuitive understanding of its components.

2 0 2 0
Catan® Monte Carlo Simulator Tool
This project came together after I played too many games of Settlers of Catan while sheltering in place during COVID-19. Given a specified game board for a player, this tool computes the expected value of rolls needed for the player to obtain a given resource as a game progresses. Then, given the same board, it performs a series of simulations to obtain a distribution of how many rolls it could potentially take to collect everything needed to build a road, settlement or city, or to obtain a development card. The simulations were written using JavaScript, and visualizations using D3.
Workshop on Neural Network Visualizations
Harvard IACS ComputeFest 2020
Collaborators: Paul Blankley, Ryan Janssen
ComputeFest is an annual 4-day series of lectures and workshops on machine learning guided by lecturers, students, and alumni of the Harvard Institute for Applied Computational Science, along with industry partners. The 2020 iteration had over 300 attendees and allowed the IACS to raise over $50,000 in support of scholarships for graduate students.
In this workshop, two former classmates and I presented on various local and global techniques for visualizing and interpreting neural networks. Topics of discussion included: input optimization for visualizing convolutional kernel characteristics, saliency and occlusion maps, and Local Interpretable Model-agnostic Explanations (LIME).
Slides from our workshop are available here, and and accompanying Jupyter notebooks are available at our GitHub readme here. These and other materials from the ComputeFest 2020 workshops are being incorporated into a course at Harvard for the Spring 2020 semester, AC295: Advanced Practical Data Science.

2 0 1 9
sklearn-Compatible Implementation of k-means-- Algorithm
I extended thesklearn KMeansclass to implement the key algorithm found in the paper k-means--: A Unified Approach to Clustering and Outlier Detection. This extension gives the user access to a new hyperparameter that allows them to control the robustness of the k-means clustering algorithm to outliers within the training data. Because the extension is implemented as ansklearntransformer, this hyperparameter can be tuned within ansklearn Pipelineobject via cross-valiation. After the algorithm is trained, it handles each new sample to cluster either by assigning it a cluster label, or explicitly marking it as an outlier.
To explore whether the detection of outliers with this algorithm could aid in a predictive task, I used it to generate a data augmentation for a random forest trained on the MNIST dataset. I demonstrated that training the random forest with the augmented dataset improved accuracy over a similar augmentation generated from vanilla k-means.
Word-Level Biography Generation for Engineering Professors using LSTMs
I trained several LSTM architectures on over 350 professor biographies that I scraped from the websites of the engineering schools at Harvard and Columbia. The generation was done at the word-level, with tokenized punctuation treated as words to be generated. The result is amusing but superficially realistic:
electromagnetic ieee properties of the western year and public technologies by leveraging a far-ranging for statistical systems. he developed academics from chemical engineering mechanics, required by the system grafts, numerical practicing physics, or italy. in addition, the mellon and safety approaches to produce water function computations, but use new zealand; sheets, where such as appropriate brains be had found that replicate these setting, or area-efficiency and kinetics of natural processes. he is a treasury that arise in understanding the objects and time by groundwater models characterization. profile near-infrared conducts professor of biological engineering award, and an optical physical society. prior to he received a phd degree in chemistry from numerous acm requirements and is placed that works composed of high-performance, llc and illumination, syntax, self-repairing, an ms professor in top technological components.
2 0 1 8
PM2.5 Interpolation using Deep Learning with Harvard School of Public Health
Project for Harvard AC297r, IACS Capstone Course
Collaborators: Keyan Halperin, Christopher Hase, Casey Meehan
AC297r is a semester-long capstone project course at Harvard in which groups of students are partnered with a company or academic research group to work on a problem involving data science and machine learning. Our group, comprised of Master's students in Statistics and Computational Science & Engineering, worked with Dr. Francesca Dominici's research group at the Harvard School of Public Health on performing interpolation of PM2.5 (a class of particulate matter correlated with a host of long-term health problems) levels in the atmosphere over the United States.
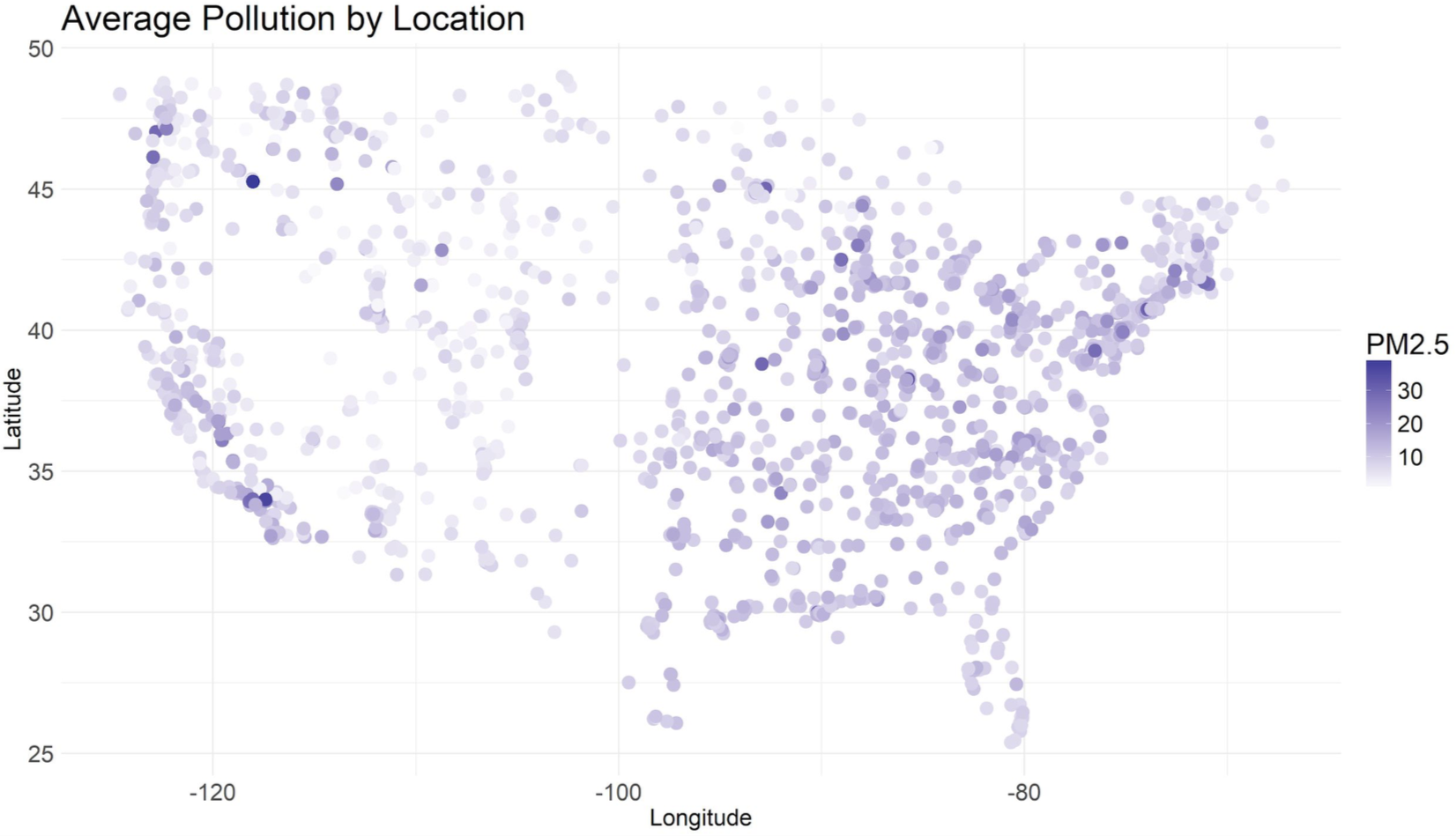
The central problem in this project pertained to a network of >2000 particulate matter sensors maintained by the EPA and affiliate research institutions around the continental United States. These sensors are expensive to maintain, and so therefore their placement around the country is not uniform - inevitably, there are more sensors in areas where more people live. As a result, millions of people live in areas in which the placement of sensors is quite sparse. It is therefore crucial, from a public health perspective, to be able to perform robust interpolation of particulate levels in such underrepresented areas in order to understand what health risks could affect their residents.
We were provided with over 15 years' worth of particulate matter sensor data, along with hundreds of topographical and atmospheric features describing the sensor locations over the same timespan, collected via satellite. For a quick summary, see our final project poster here.
{kind=link}
Video Generation from Caption and Input Image
Project for Harvard AC209b, Data Science 2 (Graduate Version)
Collaborators: Vincent M. Casser, Camilo L. Fosco, Karan R. Motwani
This was my group's final project for Harvard's Data Science 2 course. In this project, we developed a neural network architecture that generated short sequences of images based on an input image and a short textual description (e.g. "the person walks left"). The architecture drew inspiration from U-Net , which was originally developed for biomedical image segmentation. Unlike U-Net, our architecture accepted sequential collections of images (represented as rectangular prisms in our diagram below). Representations of each input frame's accompanying caption were given as input mid-network, after the input frames were transformed to a latent space.
We trained our architecture in an adversarial setting, and tested it on simple artifical datasets generated from MNIST, as well as more complex GIFs of natural images from a cleaned version of the T-GIF dataset, which had both GIFs and accompanying textual descriptions. We found that the network generated more reasonable frames from simpler inputs than from the information-rich T-GIF inputs.
We presented this work at the Harvard SEAS Design & Project Fair in May 2018. See our work below:
_____________
Bayesian GANs
Project for Harvard AM207, Stochastic Optimization
Collaborators: Vincent M. Casser, Camilo L. Fosco, Spandan Madan
This was my group's final project for Harvard's Stochastic Optimization course. The objective of the project was to provide an exposition and technical tutorial of a research paper relevant to the course. The paper we chose was Bayesian GAN by Saatchi and Wilson (2017).
The idea behind this paper was to examine the parameter space of Generative Adversarial Networks (GANs) from a Bayesian perspective, and use sampling techniques to search this space for networks that are robust against common problems in GANs such as mode collapse (i.e. generating repeatedly from a small pool of realistic yet uninteresting outputs to fool the discriminator).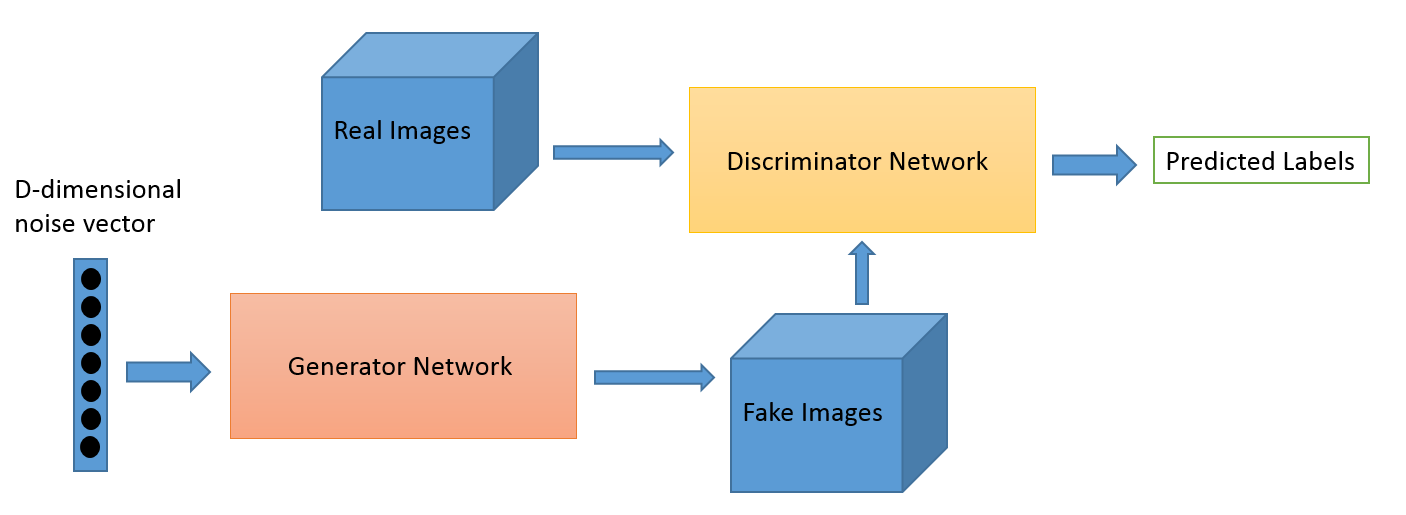
Parallelization of Data Preprocessing with Zoba, Inc.
Project for Harvard CS205, Computing Foundations for Computational Science
Collaborators: Nathaniel Stein
This was our final project for Harvard's CS205 course, a survey of large-scale computational tools and parallelization techniques. Course contents included High Performance and High Throughput Computing, various aspects of memory hierarchy and architectures, CPU/GPU computing, cloud computing, and parallelization techniques such as map-reduce.
The project was a collaboration between Master's students in the Harvard IACS and Zoba , a startup that originated out of Harvard Innovation Labs who is using machine learning techniques and geolocation data to make predictions about criminal risk, public health outcomes, and other events inside American cities and around the globe. After I met the founders at a career event, we discussed the possiblity of collaborating on a project together.
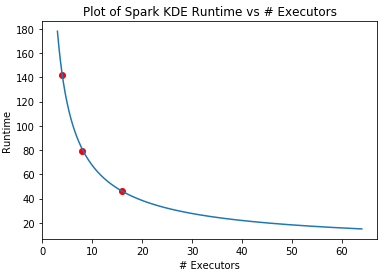
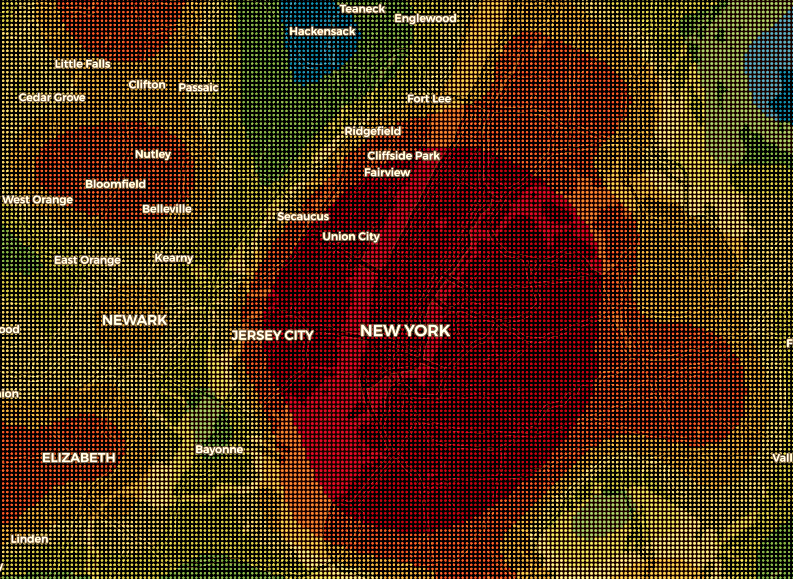
The goals for this project were:
(1) Examine Zoba's existing data pipeline, apply parallelization techniques from CS205 to sections of the pipeline, and analyse performance improvements.
(2) Prototype new tools to improve runtime of bottlenecks in the pipeline. For this, we used the PySpark libary to speed up the computation of Kernel Density Estimates on crime and geolocation data. We then tested our code on AWS clusters of various processor and memory configurations to demonstrate that Spark could be used to scale Zoba's KDE computations to large data sizes.
2 0 1 7
Analysis of Alzheimer's Disease Neuroimaging Initiative Dataset
Project for Harvard AC209a, Data Science 1 (Graduate Version)
Collaborators: Ben Anandappa, Bernard Kleynhans, Filip Michalsky
This was my group's final project for Harvard's Data Science 1 course. The objective was to analyze a dataset of individuals screened for Alzheimer's Disease (AD) curated as part of the Alzheimer's Disease Neuroimaging Initiative.
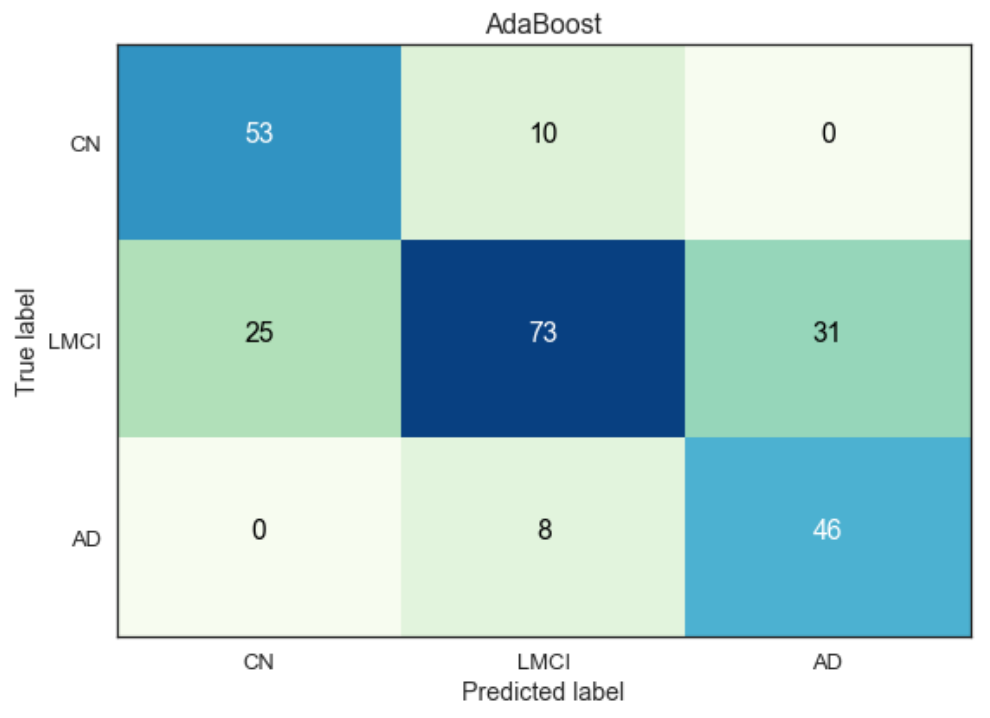 Our group cleaned and processed various ADNI datasets to then train models that classify an individual into one of three AD diagnosis categories: Cognitively Normal, Low-to-Medium Cognitive Impairment, and Alzheimer's Disease. Among the models we considered were multiple logistic regression with regularization, LDA/QDA, SVMs, and tree-based methods such as AdaBoost, XGBoost, and gradient-boosted trees.
Our group cleaned and processed various ADNI datasets to then train models that classify an individual into one of three AD diagnosis categories: Cognitively Normal, Low-to-Medium Cognitive Impairment, and Alzheimer's Disease. Among the models we considered were multiple logistic regression with regularization, LDA/QDA, SVMs, and tree-based methods such as AdaBoost, XGBoost, and gradient-boosted trees.
Also as part of our analysis, we considered genomic, demographic, PET/MRI, and cognitive assessment data from the dataset to perform predictions of diagnoses of a patient at baseline (initial) visit. We also considered feature selection methods that heuristically considered the costs (financial, timespan, health risks) of obtaining certain features.
2 0 1 6
Survey of PDE and Cellular Automata Modeling Techniques for Automobile Traffic
Project for Columbia APMA4903, Senior Seminar in Applied Mathematics
Collaborators: Linxuan (Claire) Yang
The Senior Seminar in Applied Mathematics (APMA4903) is a required part of Columbia's undergraduate Applied Mathematics curriculum; seniors form groups to give one 75-minute presentation on a technical topic of interest, along with an accompanying demonstration. The intention is for students to practice giving in-depth technical presentations, practice critiquing the technical work of their peers, and receive exposure throughout the semester to a wide variety of mathematical topics. The Fall 2016 iteration was led by Chris Wiggins.
Our group gave a survey of research in modeling road traffic over the last 60 years. This topic is exciting in its breadth of applicable mathematical concepts, as well as its practical relevance to municipal officials and urban planners. This field will likely be of significant interest to companies developing autonomous driving systems, because of the possibility of using the telemetry data that these systems collect to diagnose and/or avoid problems such as spontaneous traffic jams (surprisingly, these often occur in real life for no other reason than a handful of slow drivers). Two approaches have been dominant in academic research on this topic: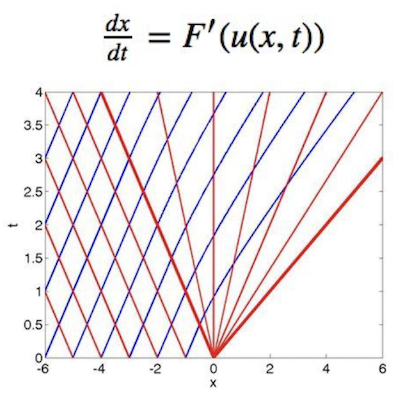
(1) Treating large-scale traffic flow along a road as akin to fluid flow in a two-dimensional pipe, and using partial differential equations (PDEs) to model the velocity of the vehicle "fluid" along different points in the pipe. This approach is compatible with various realistic boundary conditions (e.g. an obstruction, for modeling traffic jams). For this section, we examined the theory underlying a collection of relevant PDEs, such as Burgers' Equation.
(2) Using cellular automata to model traffic at the individual vehicle level. This approach was pioneered in the 1990s by Nagel and Schreckenberg, just as computing power began to permit large-scale modeling in this kind of granular manner. In contrast to the continuous modeling techniques in (1) above, this approach can be customized at the level of individual cars, allowing for more model flexibility. We also gave a demonstration of a great Python package that used this approach to model and visualize various configurations of cars traveling along a road.